
Мне довольно часто приходится работать с программным рейдом в linux - mdadm. Это эффективное бюджетное решение для обеспечения отказоустойчивости дисковой подсистемы сервера. Чтобы оперативно реагировать на проблемы с рейдом, необходимо получать информацию о его состоянии. С помощью системы мониторинга Zabbix очень легко настроить мониторинг mdadm.
На углубленном курсе "Архитектура современных компьютерных сетей" вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Содержание:
Введение
У нас имеется любой сервер Linux с настроенным рейдом mdadm. Я специально не останавливаюсь на каком-то конкретном дистрибутиве, потому что этот рецепт универсален и будет актуален в любом дистрибутиве. Узнать состояние рейда можно командой в консоли:
# cat /proc/mdstat Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10] md0 : active raid6 sdg1[6] sde1[3] sdd1[2] sdf1[4] sdc1[7] sdb1[0] 11720534016 blocks super 1.2 level 6, 512k chunk, algorithm 2 [6/6] [UUUUUU]
Заглавные буквы U означают, что все жесткие диски на месте, с рейдом все в порядке. Если какой-то из них выйдет из строя, то вместо буквы будет стоять знак _ . По этому значению мы и будем определять статус рейд массива mdadm - если знака _ нет, то все в порядке.
Воспользуемся простой командой для определения символа _ в выводе mdstat:
# egrep -c "\[.*_.*\]" /proc/mdstat
Если символа _ нет, то на выходе получаем значение 0. Если же это значение больше 1, то рейд считается поврежденным, zabbix отправляет уведомление. Отправлять полученные значения на сервер мониторинга будем с помощью UserParameter.
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
То же самое на Debian 10, если предпочитаете его:
Настройка агента для мониторинга mdadm
Идем на сервер с настроенным mdadm, который будем мониторить и добавляем в файл конфигурации агента zabbix новый параметр:
# mcedit /etc/zabbix/zabbix_agentd.conf UserParameter=mdadm.status,egrep -c "\[.*_.*\]" /proc/mdstat
Перезапускаем агент той командой, которая актуальна для вашей системы. Скорее всего сгодится такая:
# service zabbix-agent restart
Проверим работу этого параметра:
# zabbix_agentd -t mdadm.status mdadm.status [t|0]
Все в порядке. Рейд в нормальном состоянии, команда возвращает параметр 0. Для проверки правильности регулярного выражения можно направить вывод /proc/mdstat в текстовый файл, изменить там значение U на _ и прогнать egrep по этому файлу. Должно на выходе быть значение 1 или более, в зависимости от того, сколько вы подчеркиваний добавите. Например вот так:
# cat /proc/mdstat > /root/mdstat # mcedit /root/mdstat
Заменяем U на _ .
# cat /root/mdstat Personalities : [linear] [multipath] [raid0] [raid1] [raid6] [raid5] [raid4] [raid10] md0 : active raid6 sdg1[6] sde1[3] sdd1[2] sdf1[4] sdc1[7] sdb1[0] 11720534016 blocks super 1.2 level 6, 512k chunk, algorithm 2 [6/6] [UUU_UU] # egrep -c "\[.*_.*\]" /root/mdstat 1
Все верно, команда отрабатывает правильно, значит мониторинг будет корректно работать.
Настройка на сервере Zabbix
Теперь идем на сервер мониторинга и настраиваем на нем все, что необходимо для мониторинга mdadm. Нам нужно будет создать шаблон, в нем один item и один trigger. Создаем шаблон: Configuration -> Templates -> Create template.
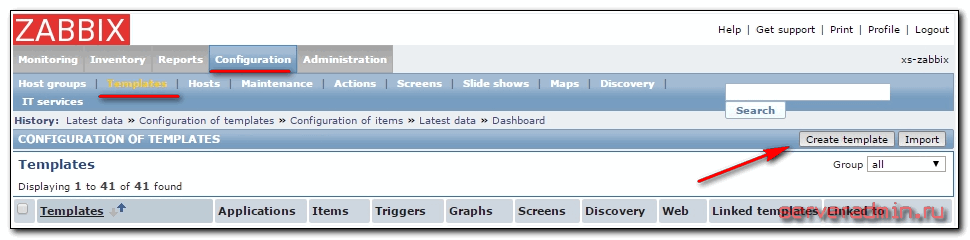
Пишем название, добавляем в группу и сохраняем. Открываем созданный шаблон, переходим в Items и создаем новый.

Заполняем параметры как у меня и жмем add.
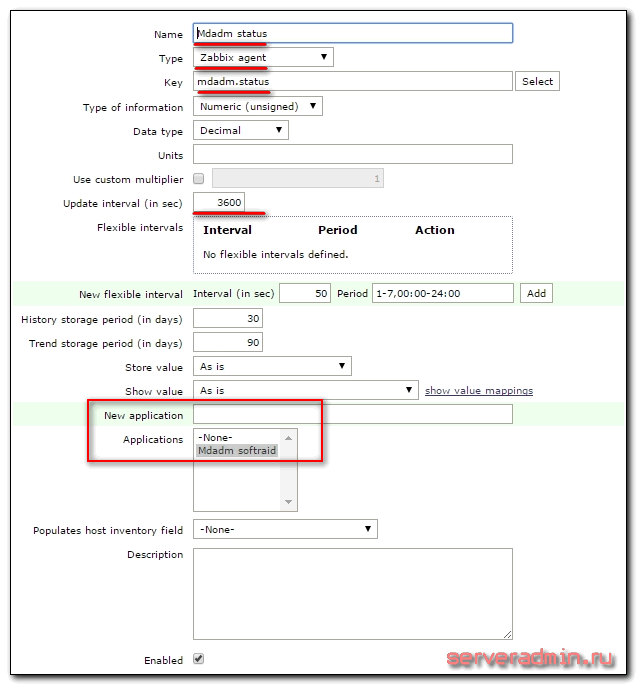
Я установил интервал обновления этого параметра в 3600 секунд, то есть раз в час. Не вижу смысла проверять его чаще. В этом нет практической пользы.
Теперь добавим триггер, который будет срабатывать, если с рейдом проблемы. Переходим на список триггеров, жмем Create trigger и заполняем значения.
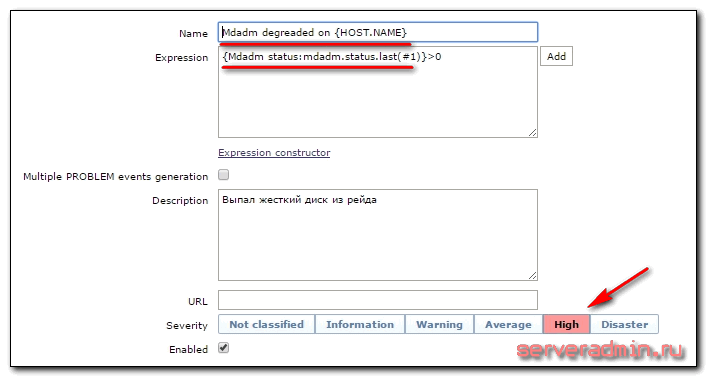
Добавляем триггер. На этом настройка шаблона закончена. Можно назначить шаблон всем хостам, на которых мы добавили UserParameter и ждать, когда в Last Data появятся первые значения. Я на момент отладки на всякий случай поставил сбор данных каждые 60 секунд. Когда убедился, что все работает, изменил это значение обратно на 3600.
Заключение
Вот так легко и просто настроить необходимый мониторинг в Zabbix. Пользовательские параметры предоставляют широкие возможности по настройке. Можно мониторить все, что угодно. Даже в данном случае можно придумать целую кучу всевозможных команд, с помощью которых можно собирать данные по mdadm. Можно сохранять не только состояние рейда, но и подробную информацию о нем. Для этого нужно просто полный вывод сделать и передавать его на сервер.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном онлайн-курcе по администрированию MikroTik. Автор курcа – сертифицированный тренер MikroTik Дмитрий Скоромнов. Более 40 лабораторных работ по которым дается обратная связь. В три раза больше информации, чем в MTCNA.
Реклама ИП Скоромнов Д.А. ИНН 331403723315

Хотел написать вопрос по поводу добавления выражения в триггере, в новом заббиксе оно выглядит по-другому ( last(/mdadm/mdadm.status)>0 ). Но у меня всё получилось. Для проверки сначала я пометил диск как сбойный.
Спасибо за статью!
Да, прикольно, но хотелось бы не в Zabix а в The Dude получать мониторинг mdadm. Было бы интересно увидеть у вас такую статью.
The Dude давно не развивается. Сам им не пользуюсь и статей точно не будет.
""Все в порядке. Рейд в нормальном состоянии, команда возвращает параметр 0. Для проверки правильности регулярного выражения можно направить вывод /proc/mdstat в текстовый файл, изменить там значение U на _ и прогнать egrep по этому файлу. Должно на выходе быть значение 1 или более, в зависимости от того, сколько вы подчеркиваний добавите.""
Ващ пример не будет считать количество подчеркиваний, не важно сколько их там будет хоть 1 или больше, всегда будет выдавать единицу, если будет хоть одно подчеркивание.
Можно например так: grep -o -i _ /root/mdstat | wc -l
А зачем их считать? Если хоть один диск вылетел из рейда, надо идти и разбираться, что с ним. В данном случае 0 и 1 это не количество дисков, а логические true и false.
Должно на выходе быть значение 1 или более, в зависимости от того, сколько вы подчеркиваний добавите.
Ваши слова в статье.
Ошибся наверное, когда писал.
Попробовал реализовать данную фичу
В агенте для тестирования прописал путь к порченному рейду. на агенте получаю:
zabbix_agentd -t mdadm.status
mdadm.status [t|1]
На сервере мониторинга Поставил время проверки 1 минуту. Но почему-то все время значение Mdadm status = 0.
Что-то где-то напутали. Если проверка на агенте показывает mdadm.status [t|1], значит механизм проверки корректен. А вот на сервере не то значение.
Разобрался, забикс не мог получать метрику из директории root
при запросе с сервера выдает:
grep: /proc/mdstat: Permission denied
Где поправить права?
Уже и zabbix в root запихал.
И в visudo
zabbix ALL=NOPASSWD: ALL
Все таже ошибка.
Каким образом проверяете? В свежих дистрах права zabbix пользователя в юнитах systemd иногда править приходится. Например, чтобы запустить агента от root. Копните в эту сторону.
zabbix_get -s 10.40.0.75 -k "mdadm.status"
Поставил
Allowroot =1
User = root
Добавил в [service]
User=root
Group=root
Служба не запускается
А ошибка какая?
[root@hd5 ~]# systemctl start zabbix-agent
Job for zabbix-agent.service failed. See "systemctl status zabbix-agent.service" and "journalctl -xe" for details.
[root@hd5 ~]# systemctl status zabbix-agent
● zabbix-agent.service - Zabbix Agent
Loaded: loaded (/usr/lib/systemd/system/zabbix-agent.service; enabled; vendor preset: disabled)
Active: activating (auto-restart) (Result: protocol) since Пн 2020-08-10 17:41:06 MSK; 5s ago
Process: 10166 ExecStart=/usr/sbin/zabbix_agentd -c $CONFFILE (code=exited, status=0/SUCCESS)
Main PID: 9027 (code=exited, status=0/SUCCESS)
авг 10 17:41:06 hd5.nghleb.local systemd[1]: Failed to start Zabbix Agent.
авг 10 17:41:06 hd5.nghleb.local systemd[1]: Unit zabbix-agent.service entered failed state.
авг 10 17:41:06 hd5.nghleb.local systemd[1]: zabbix-agent.service failed.
Надо /var/log/messages и /var/log/zabbix/zabbix_server.log смотреть. В этом выводе нет информации об ошибке.
/var/log/messages
Aug 11 13:11:25 hd5 systemd: zabbix-agent.service holdoff time over, scheduling restart.
Aug 11 13:11:25 hd5 systemd: Stopped Zabbix Agent.
Aug 11 13:11:25 hd5 systemd: Starting Zabbix Agent...
Aug 11 13:11:25 hd5 zabbix_agentd: zabbix_agentd [17255]: cannot open "/var/log/zabbix/zabbix_agentd.log": [13] Permission denied
Aug 11 13:11:25 hd5 systemd: Can't open PID file /run/zabbix/zabbix_agentd.pid (yet?) after start: No such file or directory
Aug 11 13:11:25 hd5 systemd: Daemon never wrote its PID file. Failing.
Aug 11 13:11:25 hd5 systemd: Failed to start Zabbix Agent.
Aug 11 13:11:25 hd5 systemd: Unit zabbix-agent.service entered failed state.
Aug 11 13:11:25 hd5 systemd: zabbix-agent.service failed.
Нужны права для root на /run/zabbix/zabbix_agentd.pid и на /var/log/zabbix/zabbix_agentd.log?
Запустил таки
ps -aux
root 2591 0.0 0.0 78948 1220 ? S 13:39 0:00 /usr/sbin/zabbix_agentd -c /etc/zabbix/zabbix_agentd.conf
root 2592 0.0 0.0 78948 1576 ? S 13:39 0:00 /usr/sbin/zabbix_agentd: collector [idle 1 sec]
root 2593 0.0 0.0 78948 2112 ? S 13:39 0:00 /usr/sbin/zabbix_agentd: listener #1 [waiting for connection]
root 2594 0.0 0.0 78948 2204 ? S 13:39 0:00 /usr/sbin/zabbix_agentd: listener #2 [waiting for connection]
root 2595 0.0 0.0 78948 2204 ? S 13:39 0:00 /usr/sbin/zabbix_agentd: listener #3 [waiting for connection]
root 2596 0.0 0.0 78948 2188 ? S 13:39 0:00 /usr/sbin/zabbix_agentd: active checks #1 [idle 1 sec]
НО
[root@zbx ~]# zabbix_get -s 10.40.0.75 -k "mdadm.status"
grep: /proc/mdstat: Permission denied
Запустил вручную
zabbix_agentd -c /etc/zabbix/zabbix_agentd.conf
прочитало
Спасибо! Как бы теперь с имитировать падение чтобы проверить уведомление?
Так я же показал в статье пример, как можно проверить.
Да, но хотелось бы посмотреть как триггер сработает)
Так измени правило в агенте, вместо /proc/mdstat чекай текстовый файл. Потом измени там один из дисков и жди, когда триггер сработает.
Спасибо