
Сегодня хочу рассказать о том, как я мониторю самодельные бэкапы с помощью zabbix. Подход немного костыльный, но на вопрос отвечает, ниже расскажу в чем его смысл. Я рассмотрю 2 способа, когда у вас бэкапы в виде директорий с оригинальными файлами, а второй - в виде запакованных архивов.
На углубленном курсе "Архитектура современных компьютерных сетей" вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Введение
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
То же самое на Debian 10, если предпочитаете его:
Бэкапы в виде сырых данных в директории (1-й способ)
У меня много где настроена самодельная система бэкапа, похожая на то, что описано в статье по настройке бэкапа с помощью rsync. Не буду подробно останавливаться на том, почему бэкаплю именно так. Во многих случаях это удобно, так как всегда имеешь под рукой свежую версию данных в исходном виде. В случае повреждения источника, просто меняешь точку монтирования и получаешь практически сразу все данные, без простоя рабочего процесса.
На всякий случай хочется следить за тем, что бэкапы у тебя актуальны и в случае чего ты можешь на них рассчитывать. Делать мы это будет по очень простой схеме. На сервере источнике будет раз в сутки создаваться файл. Во время бэкапа этот файл будет улетать на сервер с резервными данными. Этот сервер подключен к системе мониторинга zabbix с помощью агента. Этот агент будет периодически проверять дату последнего изменения файла. Если эта дата больше заданного интервала, то мы будем получать оповещение о том, что бэкапы не выполняются.
Для настройки описанной схемы нам понадобится выполнить несколько шагов:
- На серверах источниках настроить скрипт, который будет создавать файл и поместить его в планировщик.
- На сервере заббикс настроить на хосте с бэкапами item и trigger для слежения и оповещения о дате файла.
Бэкапы в виде запакованных архивов (2-й способ)
Если у вас бэкапится, к примеру, какая-то база в дамп или есть просто отдельный файл, то имеет смысл его архивировать и хранить в виде одиночного архива. Для таких бэкапов тоже нужен мониторинг. Чтобы следить за актуальностью бэкапа, я предлагаю мониторить 2 параметра:
- Размер файла. Если он равен нулю, то срабатывает триггер.
- Дата создания бэкапа. Если он старше какого-то срока, в моем примере будут 24 часа, то шлем оповещение.
Мониторинг бэкапов будет настроен из расчета, что у вас все бэкапы лежат в одной директории на сервере. В этой директории резервные копии хранятся для каждого объекта в отдельной папке. Будет настроено автообнаружение папок в директории с бэкапами.
1-й способ
Скрипт создания проверочного файла
Я использую описанную выше схему для бэкапа как windows так и linux серверов. Поэтому скрипта будет 2, для каждой системы. Вот пример такого скрипта для linux:
# mcedit create-timestamp.sh #!/bin/sh echo `date +"%Y-%m-%d_%H-%M"` > /shares/docs/timestamp
Скрипт просто создает файл и записывает в него текущую дату. Нам этого достаточно. Писать туда можно все, что угодно, так как проверять мы будем не содержимое, а дату последнего изменения.
Добавляем этот скрипт в cron:
# mcedit /etc/crontab #Create timestamp for backup monitoring 1 15 * * * root /root/bin/create-timestamp.sh
Раз в день в 15:01 скрипт будет создавать файл, перезаписывая предыдущий.
Делаем то же самое на windows. Создаем файл create-timestamp.bat следующего содержания:
echo %date:~-10% > D:\documents\timestamp
И добавляем его в планировщик windows. Не забудьте указать, чтобы скрипт запускался вне зависимости от регистрации пользователя, то есть чтобы он работал, даже если в системе никто не залогинен.
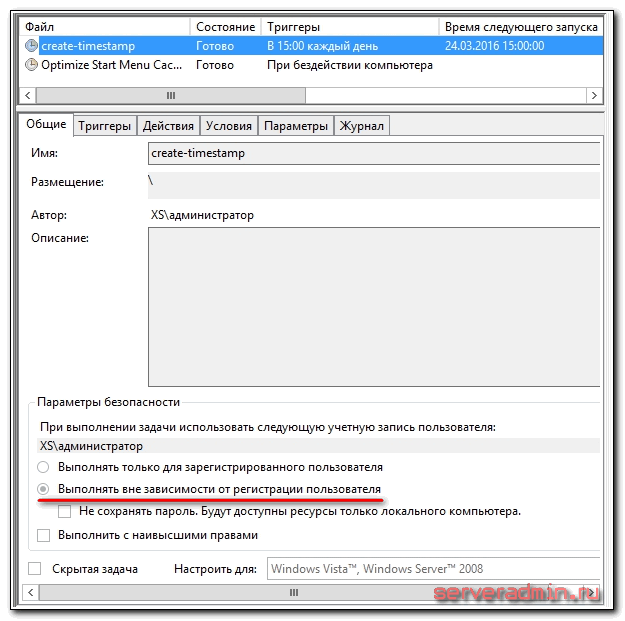
Запустите оба скрипта, чтобы проверить, что все в порядке, и необходимые файлы создаются.
Запустите стандартные скрипты бэкапа, чтобы созданные файлы переместились на резервные сервера. После этого можно приступать к настройке мониторинга за изменением файлов в zabbix.
Настраиваем мониторинг бэкапов через проверку даты изменения файлов
Дальше привычное дело по созданию итемов и триггеров. Идем в панель управления zabbix, открываем раздел Configuration -> Hosts, выбираем сервер, на котором у нас хранятся бэкапы и создаем там итем со следующими параметрами:
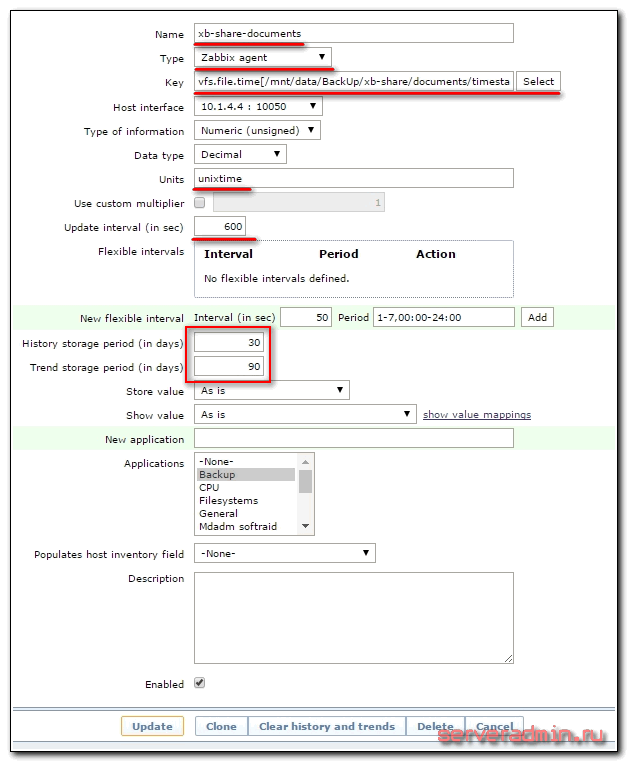
На скриншот не влезла вся строка параметра Key, поэтому привожу ее здесь:
vfs.file.time[/mnt/data/BackUp/xb-share/documents/timestamp,modify]
| /mnt/data/BackUp/xb-share/documents/timestamp | Путь к проверяемому файлу на сервере бэкапов |
| modify | Время изменения файла. Параметр может принимать значения: access - время последнего доступа, change - время последнего изменения |
Не очень понимаю, чем отличается время изменения, от времени последнего изменения. Эта информация из документации zabbix. Для того, чтобы у вас корректно собирались данные, необходимо, чтобы у пользователя zabbix были права на чтение указанного файла. Обязательно проверьте это. Я не сделал это, через одну из папок агент не мог пройти из-за недостатка прав. В итоге получил ошибку:
17177:20160321:002008.008 item "xb-share-documents:vfs.file.time[/mnt/data/BackUp/xb-share/documents/timestamp]" became not supported: Not supported by Zabbix Agent
Из текста не понятно, в чем проблема. Про права я догадался. Обновление итема установил раз в 10 минут (параметр update interval), чаще не вижу смысла, можно вообще поставить пару раз в сутки, в зависимости от вашего плана архивации данных.
Теперь создадим триггер для этого элемента данных:
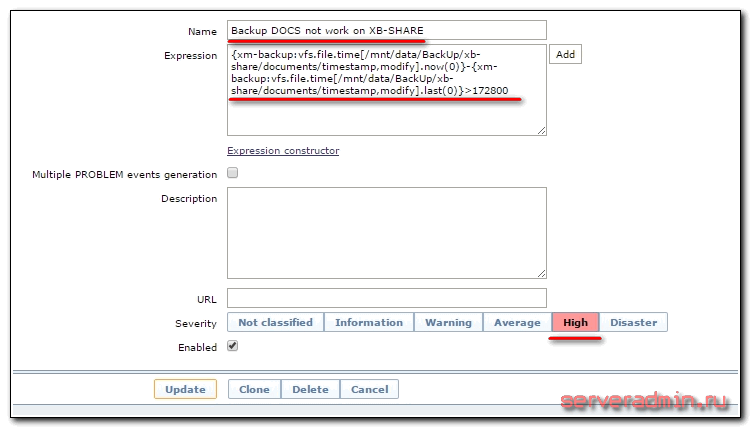
Разберем, что у нас в выражении написано:
{xm-backup:vfs.file.time[/mnt/data/BackUp/xb-share/documents/timestamp,modify].now(0)}-{xm-backup:vfs.file.time[/mnt/data/BackUp/xb-share/documents/timestamp,modify].last(0)}>172800
xm-backup - сервер, на котором хранятся бэкапы. Мы берем текущее время, вычитаем из него время последнего изменения файла. Если оно больше 172800 секунд (2 суток), то срабатывает триггер. Вы можете сами выбрать подходящий вам интервал времени сравнения в зависимости от плана бэкапа.
Для тестирования работы оповещений отключите в один из дней скрипты на источниках, создающие проверочный файл. Как только он просрочится, сработает триггер.
На этом все. Мы настроили простейший мониторинг бэкапов с помощью zabbix. Если по какой-то причине файлы перестанут синхронизироваться с сервером резервных копий, вы узнаете об этом и сможете вовремя обнаружить проблему.
2-й способ
Скрипты сбора информации о бэкапах
Во втором случае у нас есть директория с бэкапами /mnt/backup, где каждая отдельная папка содержит набор однотипных архивов за разные даты.
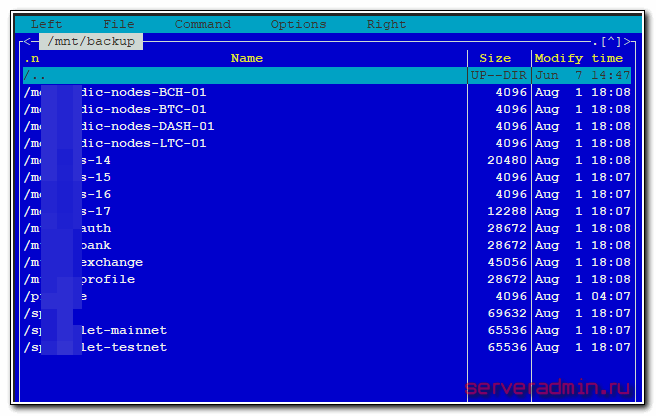
Внутри следующее содержимое. Каждый час делает резервная копия базы данных.
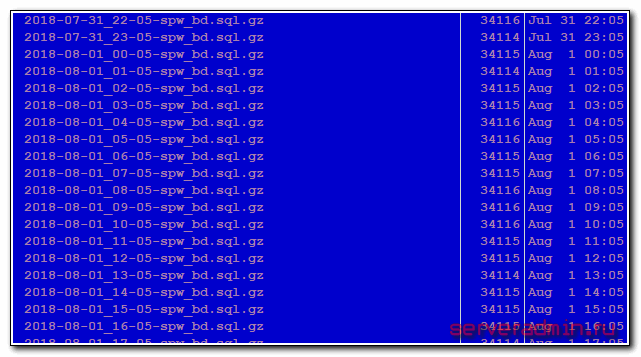
Дальнейшее описание способа мониторинга бэкапов будет актуально только для точно такой же структуры бэкапов. У вас есть общая директория, в ней папки, где внутри сжатые архивы формата .gz. Если расширение файлов другое, то можно подредактировать скрипты, которые я покажу дальше.
Нам пригодятся несколько скриптов. Первый из них - backup-info.sh. Он будет формировать текстовый файл backup_info.txt, где будет в одну строку указано имя папки с архивом, размер последнего архива, дата создания архива, время создания архива.
#!/bin/bash
BK_DIR=/mnt/backup # директория с бэкапами
SRV_NAME=`ls $BK_DIR` # формируем список папок с архивами
LOG_FILE=/etc/zabbix/scripts/backup_info.txt # выходной файл с информацией
# удаляем предыдущий файл с информацией
rm $LOG_FILE
for a in $SRV_NAME
# определяем размер последнего бэкапа
do bsize=`ls -lt $BK_DIR/$a | grep .gz | awk 'NR == 1{print$5}'`
if [[ "$bsize" = "" ]]
then
bsize=0
fi
# определяем имя последнего бэкапа
bfile=`ls -lt $BK_DIR/$a | grep .gz | awk 'NR == 1{print$9}'`
# определяем дату создания последнего бэкапа
btime=`stat $BK_DIR/$a/$bfile | grep Modify | awk '{print $2,$3}' | cut -f1-1 -d"."`
# записываем информацию в файл
echo $a $bsize $btime >> $LOG_FILE
done
В текстовом файле будет следующее:
dedic-nodes-BCH-01 496211 2018-08-01 17:54:58 dedic-nodes-BTC-01 702496 2018-08-01 17:12:46 dedic-nodes-DASH-01 244488 2018-08-01 17:40:51 dedic-nodes-LTC-01 491030 2018-08-01 17:20:23 vps-14 858433 2018-08-01 18:01:02 vps-15 235689258 2018-08-01 18:02:51 vps-16 235977137 2018-08-01 18:05:54 vps-17 23983868 2018-08-01 17:09:59
Я рекомендую разобрать каждую проверку и вручную ее выполнить в консоли, чтобы убедиться, что она работает как и должна и получает правильное значение. В разных дистрибутивах могут быть разные ключи и выводы команд. Например, команда ls может разделять значения одним пробелом, а может несколькими. Так же вывод и порядок столбцов в разных дистрибутивах может быть разный. Я все проверил только в Ubuntu 16. Данные скрипты писались и отлаживались в ней.
Следующий скрипт - backup-time.sh. Он берет значения из текстового файла, который формирует предыдущий скрипт, вычисляет разницу в часах между текущей датой и временем создания последнего бэкапа. Полученную информацию записывает в файл backup_time.txt.
#!/bin/bash
BK_DIR=/mnt/backup # директория с бэкапами
SRV_NAME=`ls $BK_DIR` # формируем список папок с архивами
LOG_FILE=/etc/zabbix/scripts/backup_time.txt # выходной файл с информацией
INFO_FILE=/etc/zabbix/scripts/backup_info.txt # входной файл для парсинга
# удаляем предыдущий файл с информацией
rm $LOG_FILE
for a in $SRV_NAME
# получаем дату создания архива
do btime=`cat $INFO_FILE | grep $a | awk '{print $3,$4}'`
# переводим дату создания архива в unix формат
stime=`date --date="$btime" +"%s"`
# получаем текущую дату в unix формате
ctime=`date +"%s"`
# сравниваем 2 даты и переводим в часы
difftime=$[ ($ctime - $stime) / 60 ]
# записываем полученный результат в файл
echo $a $difftime >> $LOG_FILE
done
Тестовый файл будет следующего содержания.
dedic-nodes-BCH-01 21 dedic-nodes-BTC-01 63 dedic-nodes-DASH-01 35 dedic-nodes-LTC-01 55 vps-14 14 vps-15 13 vps-16 10 vps-17 66
Рисуем скрипт backup-discovery.sh, который будет выполнять автообнаружение папок с архивами и передавать данные в json формате на zabbix сервер.
#!/bin/bash
JSON=$(for i in `ls -l /mnt/backup | sed '1d' | awk '{print $9}'`; do printf "{\"{#BACKUP}\":\"$i\"},"; done | sed 's/^\(.*\).$/\1/')
printf "{\"data\":["
printf "$JSON"
printf "]}"
Запустите файл и проверьте, что он корректно формирует вывод. Должно быть примерно следующее.
{"data":[{"{#BACKUP}":"dedic-nodes-BCH-01"},{"{#BACKUP}":"dedic-nodes-BTC-01"},{"{#BACKUP}":"dedic-nodes-DASH-01"},{"{#BACKUP}":"dedic-nodes-LTC-01"},{"{#BACKUP}":"vps-14"},{"{#BACKUP}":"vps-15"},{"{#BACKUP}":"vps-16"},{"{#BACKUP}":"vps-17"}]}
И еще 2 скрипта, которые будут непосредственно отдавать информацию заббикс серверу. Первый - analize-size.sh. Он будет передавать серверу информацию о размере архива.
#!/bin/bash
cat /etc/zabbix/scripts/backup_info.txt | grep $1 | awk '{print $2}'
И второй - analize-time.sh. Он передает информацию о времени создания бэкапа относительно текущего.
#!/bin/bash
cat /etc/zabbix/scripts/backup_time.txt | grep $1 | awk '{print $2}'
В завершении делаем пользователя zabbix владельцем всех скриптов и текстовых файлов. Если забыть это сделать, то потом получите ошибку и неактивный итем на сервере.
# chown -R zabbix. /etc/zabbix/scripts
Добавляем в zabbix-agent информацию о бэкапах
Теперь нам нужно добавить новые итемы в агент заббикса через UserParameter.Создаем файл /etc/zabbix/zabbix_agentd.d/backup_info.conf следующего содержания.
UserParameter=backup.discovery[*],/etc/zabbix/scripts/backup-discovery.sh UserParameter=backup.size[*],/etc/zabbix/scripts/analize-size.sh $1 UserParameter=backup.time[*],/etc/zabbix/scripts/analize-time.sh $1
Перезапускаем агента и проверяем. Для начала автообнаружение папок.
# zabbix_agentd -t backup.discovery
Вы должны увидеть список папок в json формате, как при ручном запуске скрипта. Дальше проверим вывод информации о самих бэкапах.
# zabbix_agentd -t backup.size[dedic-nodes-BCH-01] backup.size[dedic-nodes-BCH-01] [t|496211]
# zabbix_agentd -t backup.time[dedic-nodes-BCH-01] backup.time[dedic-nodes-BCH-01] [t|81]
Если получаете актуальную информацию, значит все в порядке. Можно переходить на zabbix-server.
Добавляем шаблон с мониторингом бэкапов на сервер
Здесь вам ничего руками делать не надо будет, так как шаблон я уже сделал и экспортировал в файл - zabbix-backup-info.xml. Экспорт выполнен с версии 3.4. Заработает ли на предыдущих версиях - не знаю, не проверял.
В шаблоне создано одно правило автообнаружения с двумя прототипами итемов и триггеров. Итемы имеют такие настройки:
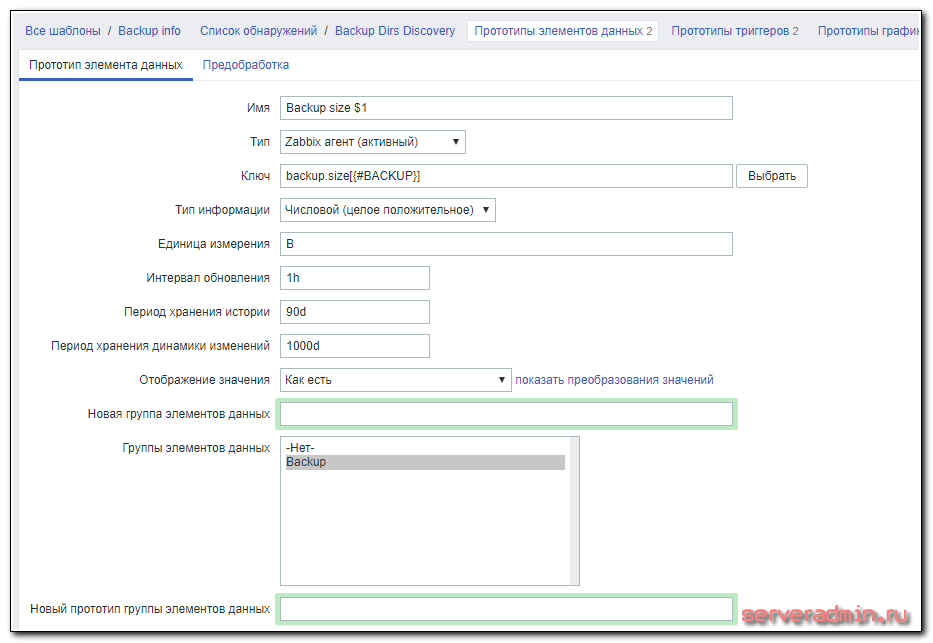
Триггеры такие:
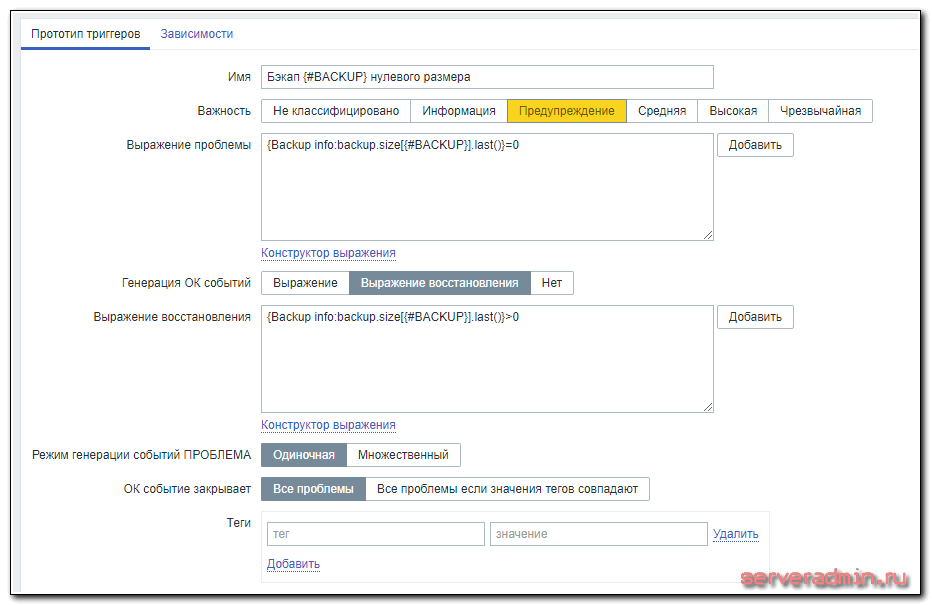
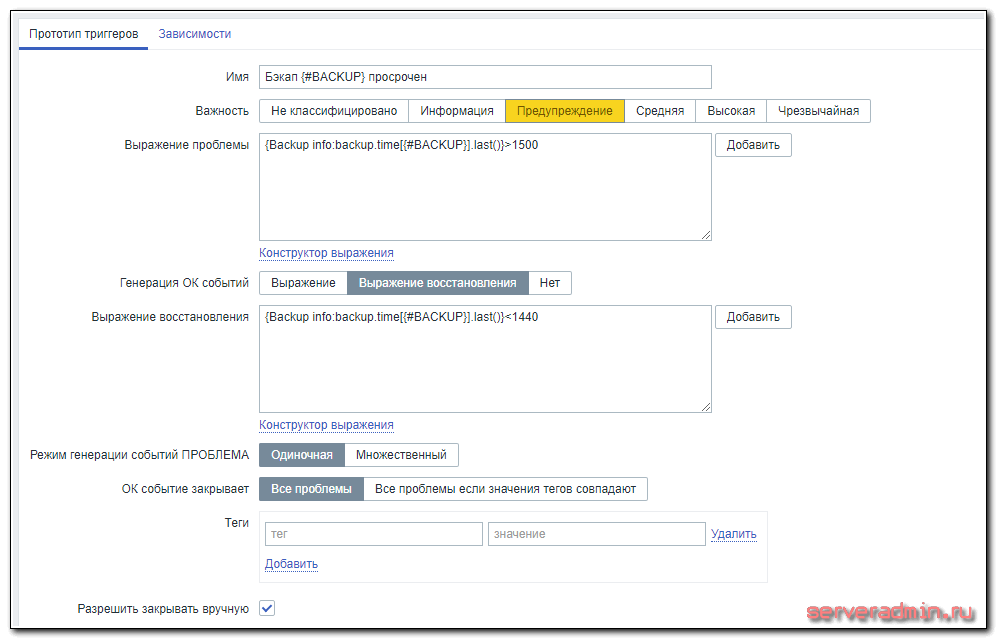
Триггер срабатывает, если архив имеет нулевой размер и если он старше 25 часов. Время переведено в минуты. Можете изменить значение по своему усмотрению. Прикрепляйте шаблон к хосту, где настроили zabbix-agent и ждите поступления данных. Обновляются они раз в час. Получите примерно такую картинку.
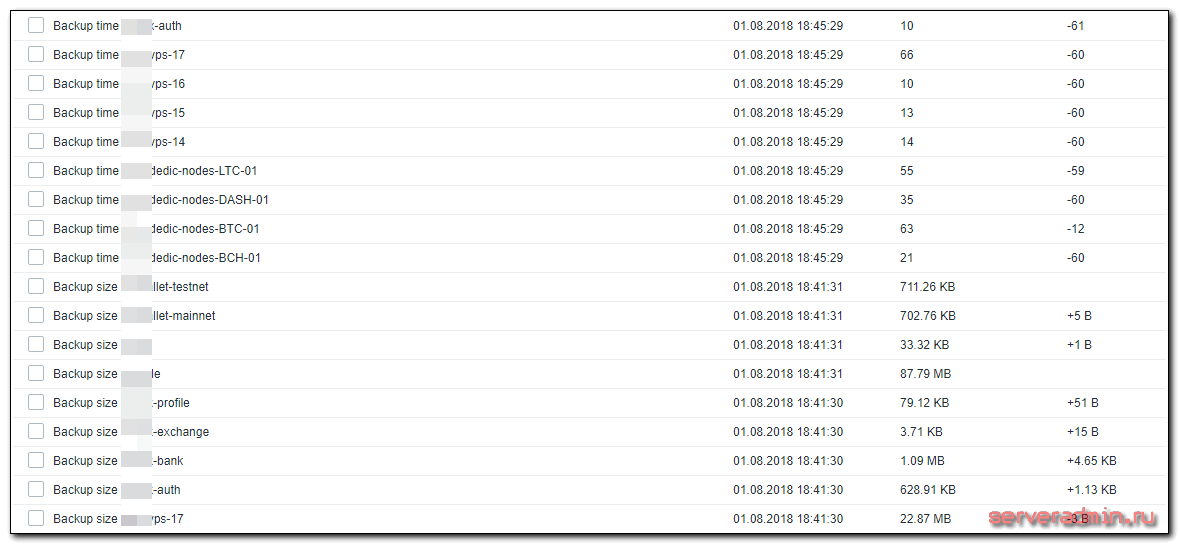
Заключение
Данный функционал можно использовать не только для мониторинга бэкапов, но и других актуальных данных. Например, какая-то программа должна выгружать данные с определенной периодичностью. Мы можем следить за тем, как она это делает. В данной статье мы рассмотрели несколько параметров, по которым заббикс может анализировать файлы и каталоги. Но таких возможностей много. Он может, к примеру, проверять конкретный размер файла и предупреждать, если он сильно меньше или больше предыдущей версии. Настраивается это примерно так же, как здесь.
На углубленном курсе "Архитектура современных компьютерных сетей" вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315

Доброго дня! помогите с созданием элементов данных в zabbix 6.4. Готовый шаблон ожидаемо не подходит, поэтому прописываю Элементы данных вручную. backup.discovery прописал, он отрабатывает. в backup time прописываю ключ backup.time[{#BACKUP}], но zabbix пишет что недопустимые символы в ключе. Если прописываю backup.time[foldername], то возраст папки отображается корректно. Какой ключ прописать будет корректно?
Ребята подскажите пожалуйста, всё работает всё круто но в имени папки вместо название папки вижу Backup size $1 и так же время Backup time $1 версия zabbix 6.0.5
Надо немного изменить шаблон под новую версию Zabbix. Но я сейчас сходу не вспомню, что там надо поменять. Это из-за разницы версий.
Да решил, спасибо. надо было поставить в имени вместо Baskup size $1 -> Backup size {#BACKUP}
Приветствую!
Настраиваю проверку бэкапа по 1-му способу. В моём случае правда я не создавал файл timestamp, а проверяю лог-файл бэкапа (backup.log) созданный в процессе процедуры резервного копирования.
Итем создал, значения с него получаю. А при создании триггера получаю ошибку:
Ошибочный параметр "/1/expression": некорректное выражение начиная с {server-01:vfs.file.time[/mnt/BackUp/backup.log,modify].now(0)}-{server-01:vfs.file.time[/mnt/BackUp/backup.log,modify].last(0)}>172800
Подскажите, пожалуста, в чём кроется проблема? Может кто сталкивался с подобным?
Со времени написания статьи, в Zabbix изменился синтаксис триггеров. В версии 5.4, если не ошибаюсь, это произошло. Изменения не сильные, но все выражения надо переделывать. Я сейчас сразу не скажу, как это же выражение должно выглядеть в новой версии. Как вариант, можно сделать это выражение в старой версии, выгрузить в шаблон и импортировать этот шаблон в новую версию. Синтаксис будет изменён автоматически.
Посмотрел на одном из обновлённых серверов. Синтаксис примерно такой:
now()-last(/srv-backup/vfs.file.time[/mnt/data/BackUp/xb-1Csrv/bases/timestamp,modify])>172800
Исправил ошибку, в случае одинаковых имен папок. например: папка и папка1.
# получаем дату создания архива
do btime=`cat $INFO_FILE | grep -w $a | awk '{print $3,$4}'`
Не могу понять, почему функцию now() используют не как самостоятельную сущность, а как часть проверяемого айтема Host:vfs.file.time["PathToCheckFile",modify].now() Немного с толку сбивает.
Насколько хорош вариант если создавать итем с типом "Траппер"?
Далее создаем для нему триггер, и мониторим, {Node:param.nodata(86460m)}=1 (например если никто не "постучал" более 24 часов)
Ну и в скрипте, который создаем сам бекап, при успешном окончании делать что то наподобие:
zabbix_sender -с -k param -o "1"
Да делать как угодно можно, это не принципиально. Я не привык использовать трапперы. Не пользуюсь ими. Все через агентов настраиваю для едионообразия.
Если стоит задача только лишь оповещать о пустых или старых бэкапах можно сделать намного проще - написать маленький скрипт, который собственно проверяет директорию (рекурсивно) на наличие таких файлов и если они есть, делает запись в лог. А уже этот лог очень просто мониторится заббиксом и в случае появления новых записей срабатывает триггер.
Так тут по сути то же самое и сделано. Скрипт все проверяет и делает запись в текстовый лог, который улетает в заббикс по автообнаружению. Только он пишет всю информацию, а не только, когда просрочен или пустой бэкап. Когда есть вся информация, удобно смотреть историю изменения размера архива, либо отключать наблюдение за отдельными архивами прямо в интерфейсе заббикса, без необходимости правки скрипта.
По сути то же самое, просто ваш подход показался несколько громоздким что-ли. Один простой скрипт легче для понимания и настройки чем 4 простых. Приблизительно в 4 раза =) Но за простоту приходится платить неудобством правки самого скрипта в случае чего, это да.
Я просто не заморачивался, когда делал. Это все можно сделать тоже одним скриптом более элегантно. Обычно, когда делаешь рабочее решение, важно, чтобы работало, потому что рабочий график подразумевает максимально эффективную и быструю деятельность. А когда пишешь статью, уже не хочется заново погружаться в тему и оптимизировать, проверять. Показываешь готовое решение, которое уже работает и его не надо проверять.
А если ошибка бекапа внутри? И даты поменялись, и не пустой?
Бэкапы надо регулярно разворачивать и проверять. Это тоже можно автоматизировать при желании и мониторить в заббиксе. Но решение типовым никак не может быть, так как у всех свои бэкапы и свои приложения.
После этой команды
# cat /etc/zabbix/scripts/backup_time.txt | grep $1 | awk '{print $2}'
выходит ошибка
Использование: grep [ПАРАМЕТР]… ШАБЛОН [ФАЙЛ]…
Запустите «grep --help» для получения более подробного описания.
Как исправить не подскажете ?
Debian 9
Если писать просто
# cat /etc/zabbix/scripts/backup_time.txt | awk '{print $2}'
то при проверки агента
# zabbix_agentd -t backup.time[sto] получаю вывод в таком виде:
backup.time [t|6
12
10
10
11]
Команду:
cat /etc/zabbix/scripts/backup_time.txt | grep $1 | awk ‘{print $2}’
нельзя просто проверить в консоли, как раз и будет ошибка. Там на вход идет значение $1. Если проверяете вручную через консоль, то вместо $1 надо явно указывать какое-то название из файла backup_time.txt
Всё понял, спасибо.
Пошло дело дальше)))
Скажите пожалуйста, а вот эти ключи " backup.size[{#BACKUP}] " они откуда взяты ? Я только начал знакомство с zabbix и не догоняю не много. Сделал всё как в статье, но данные не приходят почему-то... ((
$tmp=""
$folder=[string]$args[0]
$tmp=Get-ChildItem -Path "d:\Backup\$folder\" -Include *.rar,*.zip -Recurse|Sort-Object LastWriteTime|Select-Object -Last 1
$btime = $tmp.LastWriteTime
$rdate = [DateTime]$btime
$tdate = Get-Date
$stime = $tdate - $rdate
$rezulttime = [double]$stime.TotalHours
$rezulttime=$rezulttime -replace ",","."
$rezulttime
Вот мой скрипт на powershell, передается имя папки в которой лежат бекапы, бекапы могут быть rar и zip
"Не очень понимаю, чем отличается время изменения, от времени последнего изменения. Эта информация из документации zabbix."
Modify time - это время, когда файл последний раз изменялся. Change time - это время, когда файл или его атрибуты последний раз изменялись. Похоже, но вещи разные. Увидеть их можно например коммандой stat:
$ stat ~/.bash_history
File: /home/leonid/.bash_history
Size: 37758 Blocks: 80 IO Block: 4096 regular file
Device: 802h/2050d Inode: 2467263 Links: 1
Access: (0600/-rw-------) Uid: ( 1000/ leonid) Gid: ( 1000/ leonid)
Access: 2019-05-09 08:57:22.985396523 +0300
Modify: 2019-05-09 09:04:10.032934845 +0300
Change: 2019-05-09 09:04:10.032934845 +0300
Birth: 2019-05-09 08:57:22.985396523 +0300
Modify time можно изменять руками (например коммандой touch). Change time изменить штатными средствами нельзя. Иногда полезно мониторить modify time - например, в бэкапах. А иногда Change time - например на /etc/passwd, ибо в случаях несанкционированных изменений, всякие гнусы обычно возвращают Modify time на оригинальный. :)
Подробнее про ctime, mtime, atime, итд можно почитаать например тут:
https://www.shellhacks.com/fake-file-access-modify-change-timestamps-linux/
А за весь цикл статей про Zabbix - огромное спасибо. Очень полезно, даже для тех, кто с системой знаком, но трогает редко. :)
Спасибо за информацию. Я постоянно путаюсь в этих понятиях. Когда надо написать скрипт с использованием ctime, mtime, atime, все время приходится лезть в документацию и разбираться.
Access - это последний доступ - его легко запомнить. Change и modify - синонимы, поэтому - да, конфуз. Но тут через аналогии можно: mc (midnight commander), ls -al, и куча других файловых тулзов когда показывают дату, показывают именно mtime. Ибо он гораздо чаще нужен, чем ctime. :)
В скрипте backup-info.sh матерится на функцию stat, может есть предложение как ее иначе обьявить ???
stat это консольная утилита, которая выводит расширенную информацию о файле. Возможно, она просто не установлена.
Установлена, в консоле проверял выдает инфу, а вот в скрипте не отрабатывает
Добрый вечер! Прошёлся по статье, создал всё наподобии Вашего случая, но у меня почему-то не создаются item-ы из прототипов, хотя вывод с файлика корректный.
Значит где-то ошиблись :) Что я могу еще сказать.
Отличная статья, спасибо!
debian 9
1.добавил в начало bash скриптов
LANG=en_US.UTF-8
LANGUAGE=en_US:en
LC_CTYPE="en_US.UTF-8"
LC_NUMERIC="en_US.UTF-8"
LC_TIME="en_US.UTF-8"
LC_COLLATE="en_US.UTF-8"
LC_MONETARY="en_US.UTF-8"
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="en_US.UTF-8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="en_US.UTF-8"
LC_IDENTIFICATION="en_US.UTF-8"
LC_ALL=
иначе не отрабатывал | grep Modify
2. И вот здесь чтобы получить разницу в часах, разделил на 3600, было 60
ctime=`date +"%s"`
# сравниваем 2 даты и переводим в часы
difftime=$[ ($ctime - $stime) / 3600 ]
В начале каких скриптов именно добавил ???
date: invalid date ‘2019-01-20 23:56:29\n2019-01-16 15:01:01’
./backup-time.sh: line 19: (1548081563 — ) / 60 : syntax error: operand expected (error token is «) / 60 «)
вот такая полная ошибка.
понимаю что в файл backup_info.txt после каждой строчки вставлен ентер, но не могу понять как убрать его при чтении
столкнулся с проблемой Unsupported item key.
Сделал все по статье, версия идентична.
В чем может быть проблемка?
В чем угодно. Смотрите информацию в ошибке итема, при наведении мышки на надпись Unsupported.
Спасибо, этот шаг уже решил, теперь новая ошибка в скрипте самом ./backup-time.sh: line 19: (1548073016 - ) / 60 : syntax error: operand expected (error token is ") / 60 ")
date: invalid date ‘2019-01-20 23:56:29\n2019-01-16 15:01:01’
./backup-time.sh: line 19: (1548081563 - ) / 60 : syntax error: operand expected (error token is ") / 60 ")
вот такая полная ошибка.
понимаю что в файл backup_info.txt после каждой строчки вставлен ентер, но не могу понять как убрать его при чтении
две папки с архивами имеют одинаковое название в начале решилось
btime=$(cat $INFO_FILE | grep '$a' | awk '{print $3,$4}') - в грепе должно быть точное соответствие
Спасибо!, вот параметры:
UserParameter=backup.discovery[*],/etc/zabbix/scripts/backup/backup-discovery.sh
UserParameter=backup.size[*],/etc/zabbix/scripts/backup/analize-size.sh $1
UserParameter=backup.time[*],/etc/zabbix/scripts/backup/analize-time.sh $1
пришлось все таки в скриптах:
analize-size.sh и analize-time.sh добавить запуск остальных 2-х скриптов:
backup-info.sh
backup-time.sh
Получилось так:
analize-size.sh:
#!/bin/bash
/etc/zabbix/scripts/backup/backup-info.sh
cat /etc/zabbix/scripts/backup/backup_info.txt | grep $1 | awk '{print $2}'
analize-time.sh:
#!/bin/bash
/etc/zabbix/scripts/backup/backup-time.sh
cat /etc/zabbix/scripts/backup/backup_time.txt | grep $1 | awk '{print $2}'
Таким образом перед каждым опросом итемов обновляется информация о дате и размеров файлов.
Да, можно и так сделать. Я в предыдущем совете ошибся :) Скрипты:
backup-info.sh
backup-time.sh
запускаются по крону. Неужели забыл об этом упомянуть в статье?
В целом, так как вы сделали тоже можно. Но нужно учитывать такой момент. Если выполнение скриптов по какой-то причине будет задерживаться, то итемы заббикса могут становиться неактивными из-за превышения таймаута ожидания данных от агента. По-умолчанию, это 3 секунды. Можно этот параметр увеличить. Но по мне, так лучше тяжелые запросы от заббикса убирать. Например, если так рассчитывать размеры директорий, то в в таймауты можно не уложиться, либо их придется делать огромными - минуту и более. На больших объемах размер рассчитывается очень долго.
Спасибо!
А как запускаются скрипты:
backup-info.sh
backup-time.sh
при настройки запустил в ручную.
Вот так:
После самого скрипта нужно передать какое-то название папки с бэкапом, для которой будет проверка. Если просто запустить, то в выводе будет пусто.
Имел в виду периодичность запуска этих скриптов(через забикс или крон?).
Эти скрипты запускает заббикс сервер при опросе итема агента, где через userparameter описаны эти итемы со скриптами.
а не проще бы было использовать функцию тригера fuzzytime?
Может и проще, раскрой тему.
Есть функция триггера fuzzytime, проверяет разницу между текущим временем сервера и временем из элемента данных. То есть выражение триггера из примера будет выглядеть {xm-backup:vfs.file.time[/mnt/data/BackUp/xb-share/documents/timestamp,modify].fuzzytime(172800)}=0
А если сервер в другом часовом поясе то получим ложные срабатывания. подобны вычисление лучше делать имея время с одного и того же сервера