
В данной статье я расскажу о том, как настроить мониторинг почтового сервера Postfix с помощью Zabbix. В сети много советов и готовых инструкций, и моя в этом плане не будет какой-то уникальной. Попробую более подробно раскрыть тему и дать несколько своих советов и рекомендаций.
На углубленном курсе "Архитектура современных компьютерных сетей" вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Введение
Данная статья по мониторингу будет написана на примере настроенного почтового сервера из другой моей статьи - Настройка Postfix + Dovecot + Postfixadmin + Roundcube + DKIM на Debian. В целом руководство будет универсальное, так как службы, конфигурация и формат логов Postfix одинаковы на всех системах. С небольшой адаптацией названий логов, приложений и путей эта статья будет актуальна и для других систем.
В основе всех примеров мониторинга Postfix лежит набор перловых скриптов pflogsumm для сбора статистики о письмах из лог-файла. У меня уже были несколько вариантов этой же статьи. Перед очередным обновлением я ещё раз бегло поискал в интернете и на сайте самого Zabbix какие-то другие реализации, но не нашёл их. В итоге решил больше не поддерживать свои костыли, а взять то, что предлагает Zabbix в своём репозитории со сторонними шаблонами от сообщества: Applications/Mail_servers/template_postfix. С эти решением больше шансов, что кто-то его будет поддерживать в актуальном состоянии.
Вся настройка мониторинга свелась к тому, чтобы адаптировать предложенный шаблон, набор скриптов и конфигураций под окружение Debian, на базе которой построен мой почтовый сервер.
Подготовка сервера к мониторингу
Установим несколько необходимых для дальнейшей работы пакетов:
# apt install logtail pflogsumm sudo rsyslog
Основное тут - pflogsumm. Именно этот перловый скрипт будет анализировать почтовый лог-файл и собирать про нему статистику, которая потом будет передаваться в Zabbix. Проверим, чтобы он корректно работал:
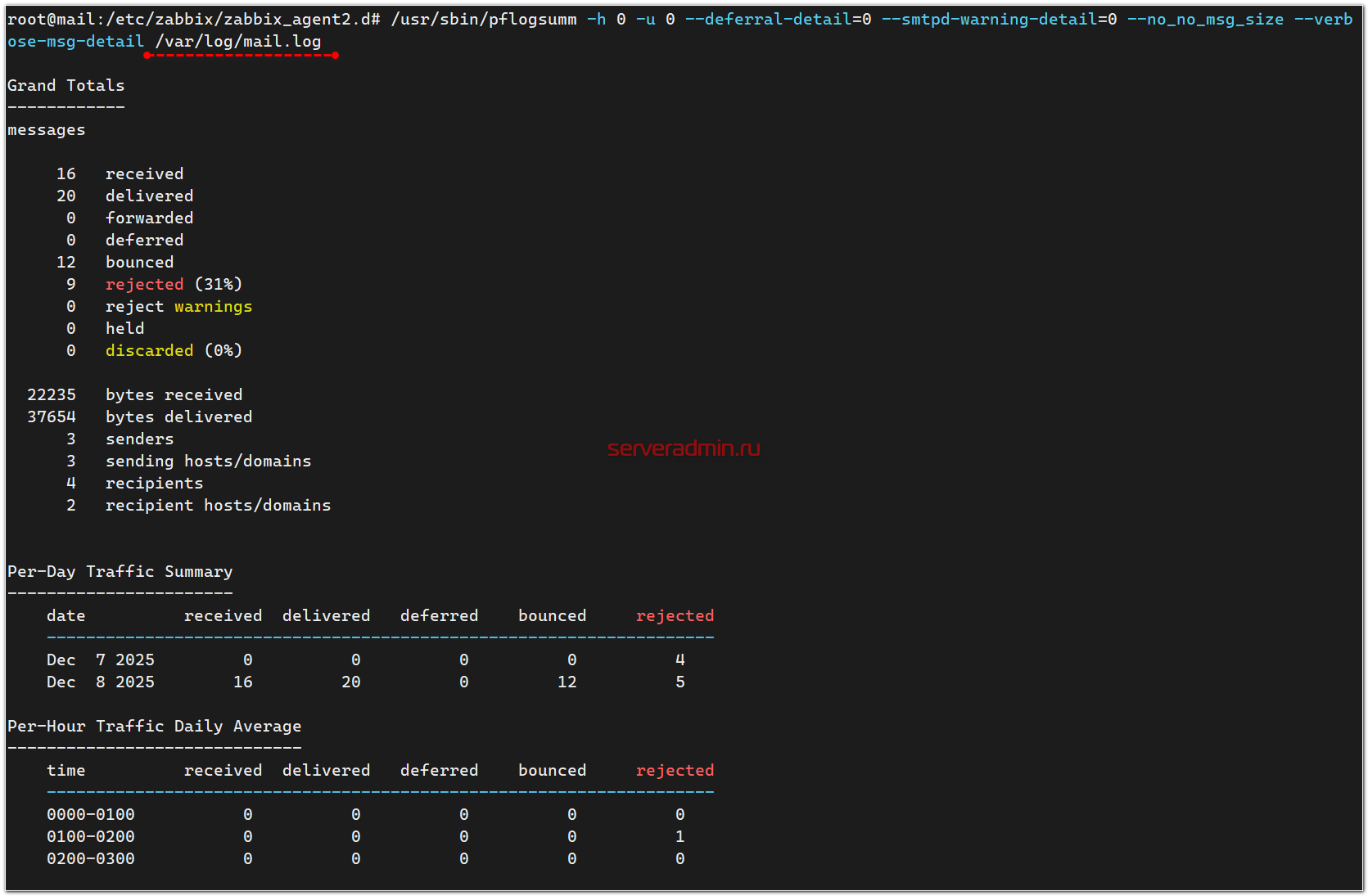
Не забудьте указать свой путь к почтовому логу. Обычно он в deb системах /var/log/mail.log, а в rpm - /var/log/maillog. Это при условии, что используются текстовые логи на базе rsyslog или другого syslog сервера. В современных системах его нужно будет установить отдельно (мы сделали это выше), так как по умолчанию все логи ведутся в systemd (systemctl logs).
Настройка zabbix-agent на почтовом сервере
Можно переходить к настройке непосредственно мониторинга. Первым делом установим агент Zabbix. Нам некритично использовать саму свежую версию агента, поэтому можно поставить его из базового репозитория Debian:
# apt install zabbix-agent2
Я не буду останавливаться на вопросе добавления сервера в мониторинг Zabbix. Подразумеваю, что раз вы используете Zabbix, то уже умеете добавлять в него новые узлы. Далее в инструкции буду считать, что почтовый сервер уже добавлен на сервер мониторинга и нормально с ним взаимодействует.
Скачиваем из репозитория с шаблоном некоторые файлы, которые нам понадобятся для настройки мониторинга. Я на всякий случай приведу их содержание в уже отредактированном виде.
- /etc/zabbix/zabbix_agent2.d/template_app_postfix.conf
UserParameter=postfix.logsummary,sudo /usr/sbin/logtail /var/log/mail.log /tmp/zabbix-postfix-log.offset | /usr/sbin/pflogsumm -h 0 -u 0 --deferral-detail=0 --smtpd-warning-detail=0 --no_no_msg_size --verbose-msg-detail UserParameter=postfix.spool,sudo /etc/zabbix/scripts/postfix_get_spool.sh UserParameter=postfix.queue,sudo /usr/sbin/postqueue -j UserParameter=postfix.version,/usr/sbin/postconf mail_version | sed 's/.* = //'
- /etc/zabbix/scripts/postfix_get_spool.sh
#!/bin/bash
postfix_config=/etc/postfix/main.cf
basedir=$(grep -e ^queue_directory $postfix_config | sed 's/.\+=[[:space:]]\?\(.\+\)/\1/')
[[ $basedir ]] || basedir=/var/spool/postfix
queuedirs="deferred active maildrop incoming corrupt hold"
idx=0
echo -n '{'
for dir in $queuedirs; do
[[ $idx != 0 ]] && echo -n ","
echo -n "\"$dir\":"
if [ -r $basedir/$dir ]; then
echo -n $(find "$basedir/$dir" -type f | wc -l)
else
echo -n "-1"
fi
idx+=1
done
echo -n '}'
- /etc/sudoers.d/zabbix_postfix
User_Alias ZABBIX = zabbix Cmnd_Alias LOGTAIL_MAILLOG = /usr/sbin/logtail /var/log/mail.log /tmp/zabbix-postfix-log.offset Cmnd_Alias GET_SPOOL_SCRIPT = /etc/zabbix/scripts/postfix_get_spool.sh Cmnd_Alias POSTQUEUE = /usr/sbin/postqueue -j ZABBIX ALL= NOPASSWD: LOGTAIL_MAILLOG, GET_SPOOL_SCRIPT, POSTQUEUE
После того, как разложите файлы по директориям, проверьте, чтобы у скрипта postfix_get_spool.sh были права на исполнение:
# chmod +x /etc/zabbix/scripts/postfix_get_spool.sh
После этого перезапустите zabbix-agent:
# systemctl restart zabbix-agent2
На почтовом сервере всё настроили, перемещаемся на Zabbix Server.
Настройка мониторинга Postfix
Скачиваем из репозитория файл с шаблоном template_Postfix_by_Zabbix_agent_active.yaml. Вам нужно скачать непосредственно исходный файл в виде raw файла.
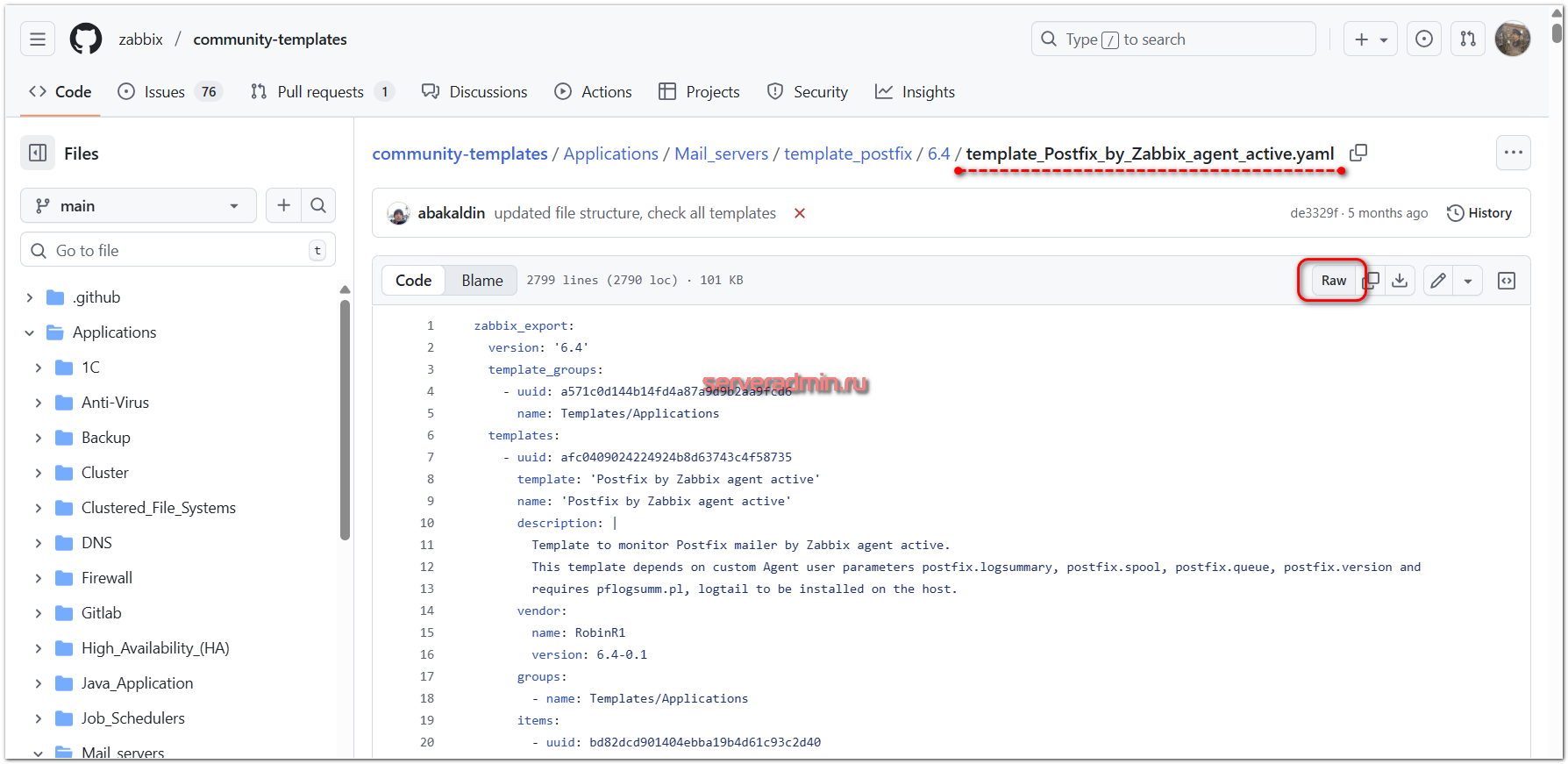
После этого переходите на Zabbix Server в раздел Сбор данных ⇨ Шаблоны и импортируйте скачанный шаблон.
После импорта в шаблоне можно сразу же изменить некоторые макросы:
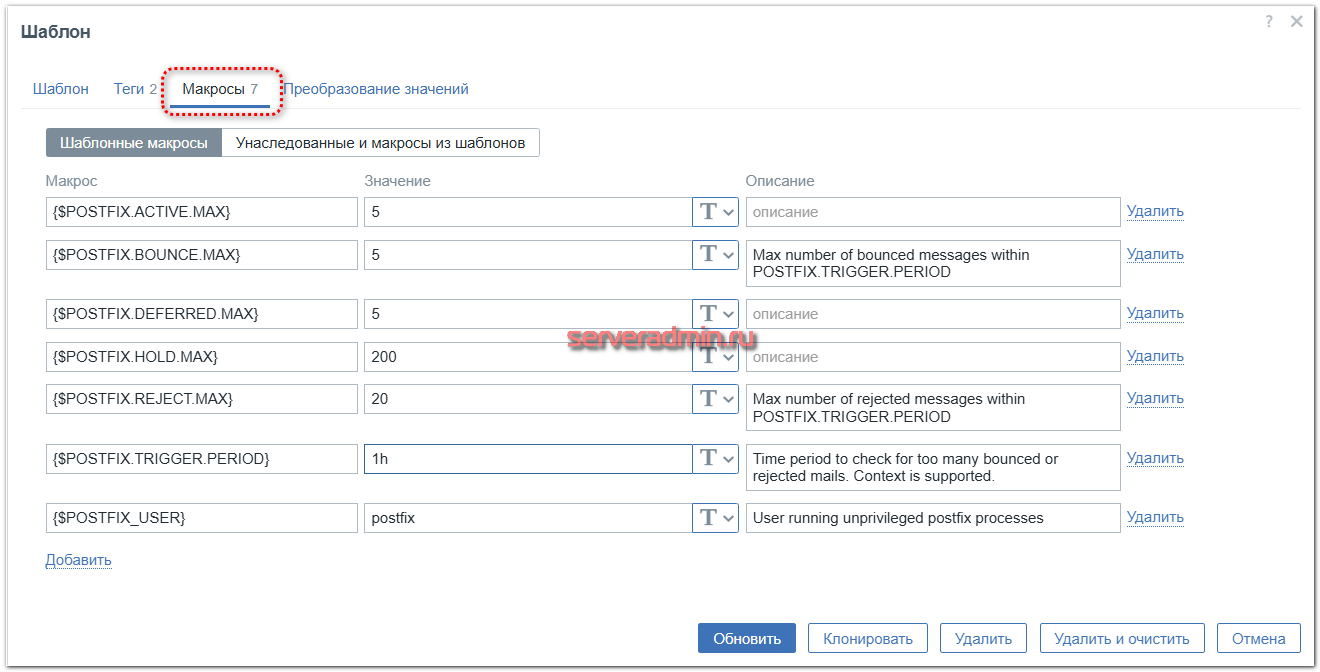
А вот триггеры, к которым они относятся:
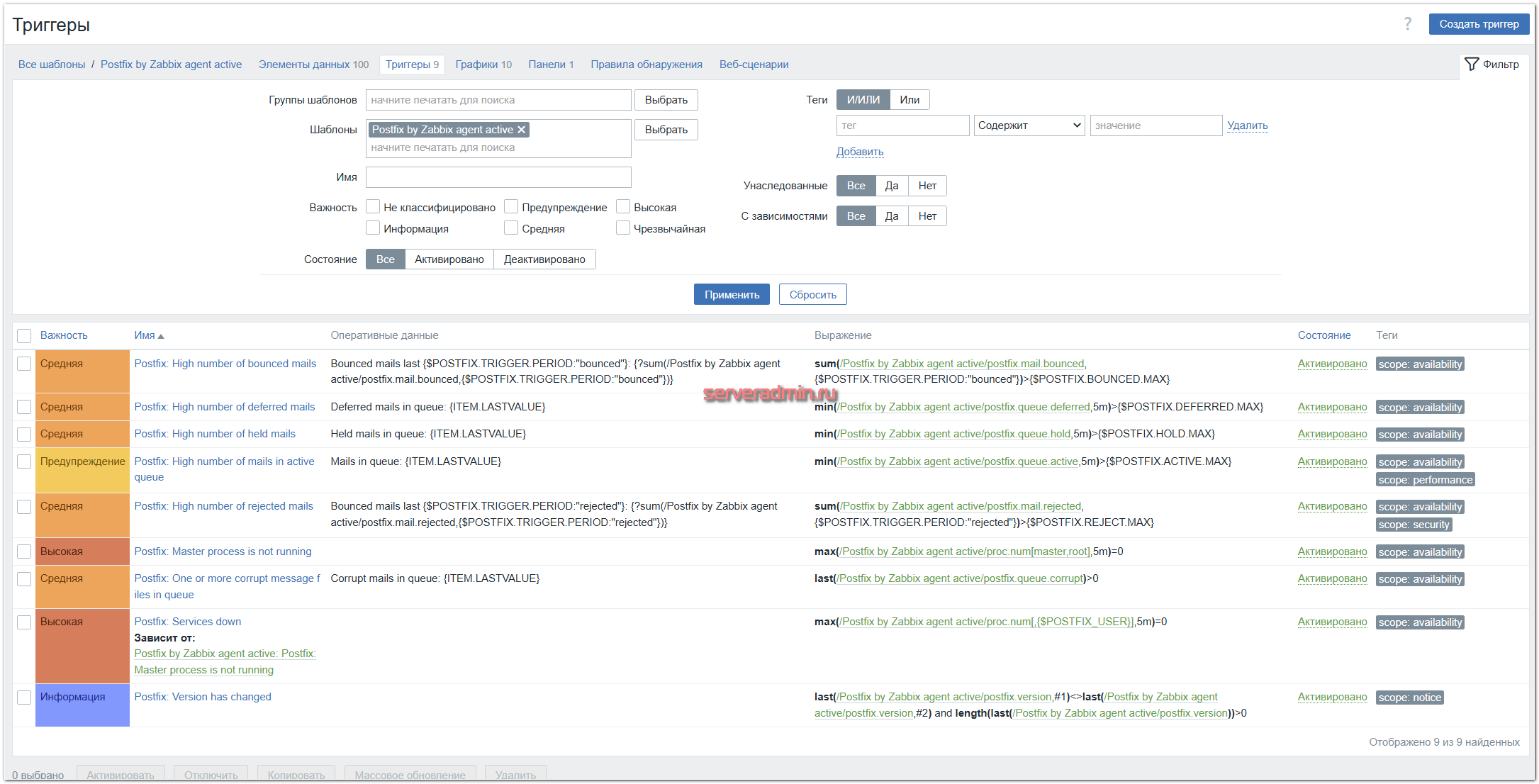
Описание макросов есть в репозитории, но я всё же поясню каждый.
- {$POSTFIX.ACTIVE.MAX}, {$POSTFIX.DEFERRED.MAX} и {$POSTFIX.HOLD.MAX} - количество различных сообщений в очереди отправки. На это значение настроены триггеры, которые срабатывают при превышении. Это одни из самых важных метрик, так как резкий рост очереди сообщений почти всегда означает, что на сервере есть какие-то проблемы, если вы перед этим не делали сами массовых рассылок. При ровной нагрузке на сервер очередь примерно одинаковая. Рост очереди может может быть вызван взломом одного из ящиков и несанкционированной массовой рассылкой с него, попаданием сервера в какие-то чёрные списки, проблем с настройками, которые приводят к отказу других серверов принимать вашу почту. Например, не так давно у одного из обслуживаемых серверов изменился IP адрес. Заменили все DNS записи, а про PTR запись забыли. В результате некоторые сервера стали отклонять от него почту, и она болталась в очереди. По мониторингу заметил эту проблему, стал разбираться и нашёл причину. Данные макросы подбираются под каждый конкретный сервер в зависимости от интенсивности отправки и специфики его работы. Сначала посмотрите, какие у вас средние значения метрик, для которых есть триггеры с этими макросами, а потом настройте их.
- {$POSTFIX.BOUNCE.MAX} и {$POSTFIX.REJECTED.MAX} - количество писем в статусе bounce и rejected на основе анализа лог-файла с помощью pflogsumm. Макрос {$POSTFIX.TRIGGER.PERIOD} определяет за какой период будут рассчитываться допустимые значения определённых выше макросов. Как и в предыдущих макросах, эти значения нужно вычислять экспериментальным путём во время отладки мониторинга. Выставьте какой-то период и посмотрите средние значения bounce и rejected. А потом уже установите пороги в макросах в x3-x5 от средних значений.
- {$POSTFIX_USER} - пользователь, от которого работает почтовый сервер. По умолчанию обычно это postfix.
Шаблон импортировали, с макросами разобрались. Теперь подключаем шаблон к хосту с почтовым сервером и наблюдаем за поступлением данных.
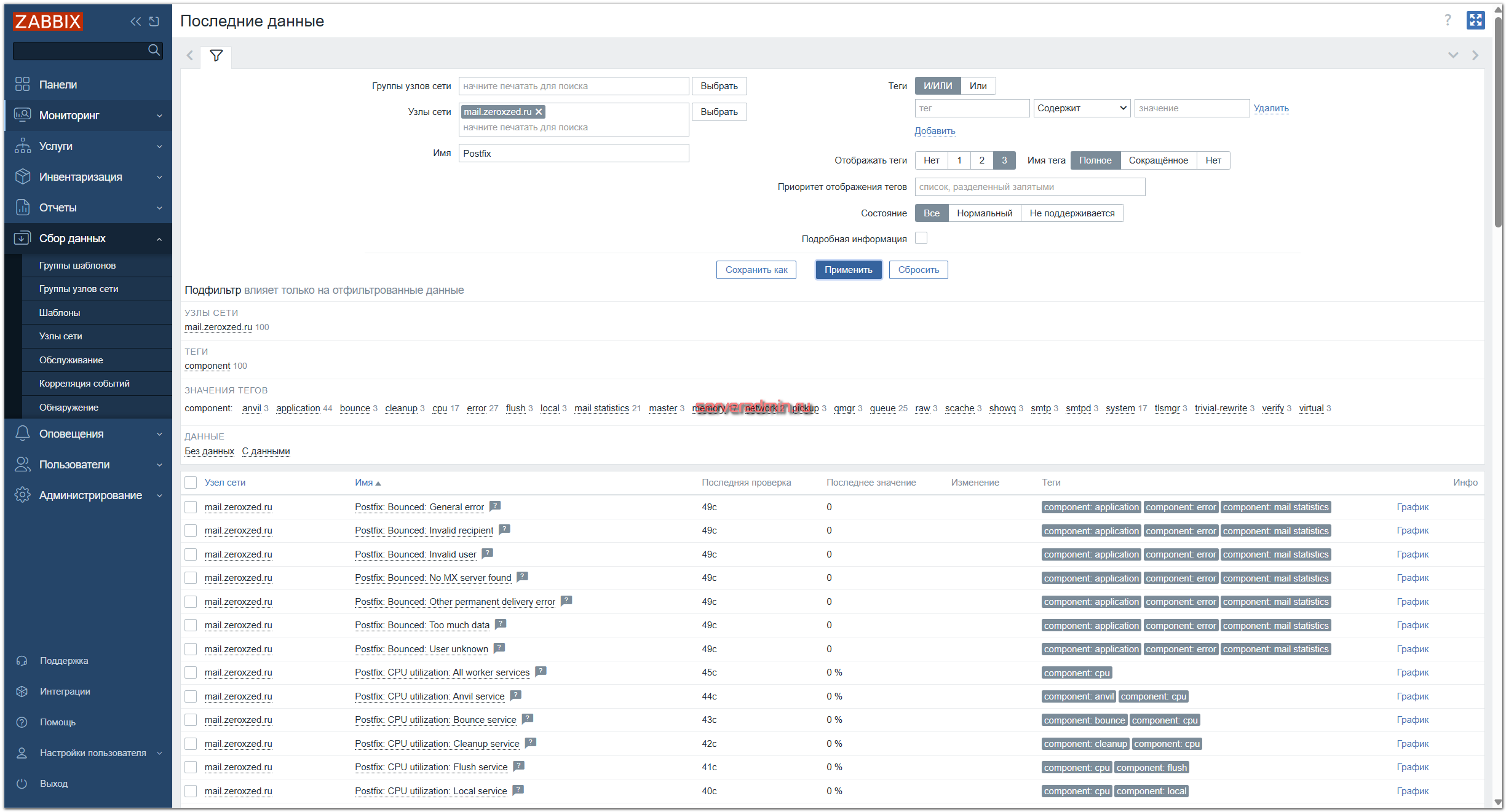
В шаблоне очень много всевозможных метрик, связанных с процессами почтового сервера и потреблением ресурсов. Если у вас не супернагруженный сервер, эти метрики вам вряд ли понадобятся. Можете их отключить. Основное, как по мне, это анализ лог файла, очереди и все метрики, что от них зависят. В шаблоне это базовые айтемы postfix.logsummary и postfix.queue.
В шаблоне присутствуют несколько графиков и панель. Панель выглядит информативно, но адаптирована под большие мониторы. У меня с разрешением 2К некоторые элементы перекрывают друг друга и смотрятся неаккуратно:
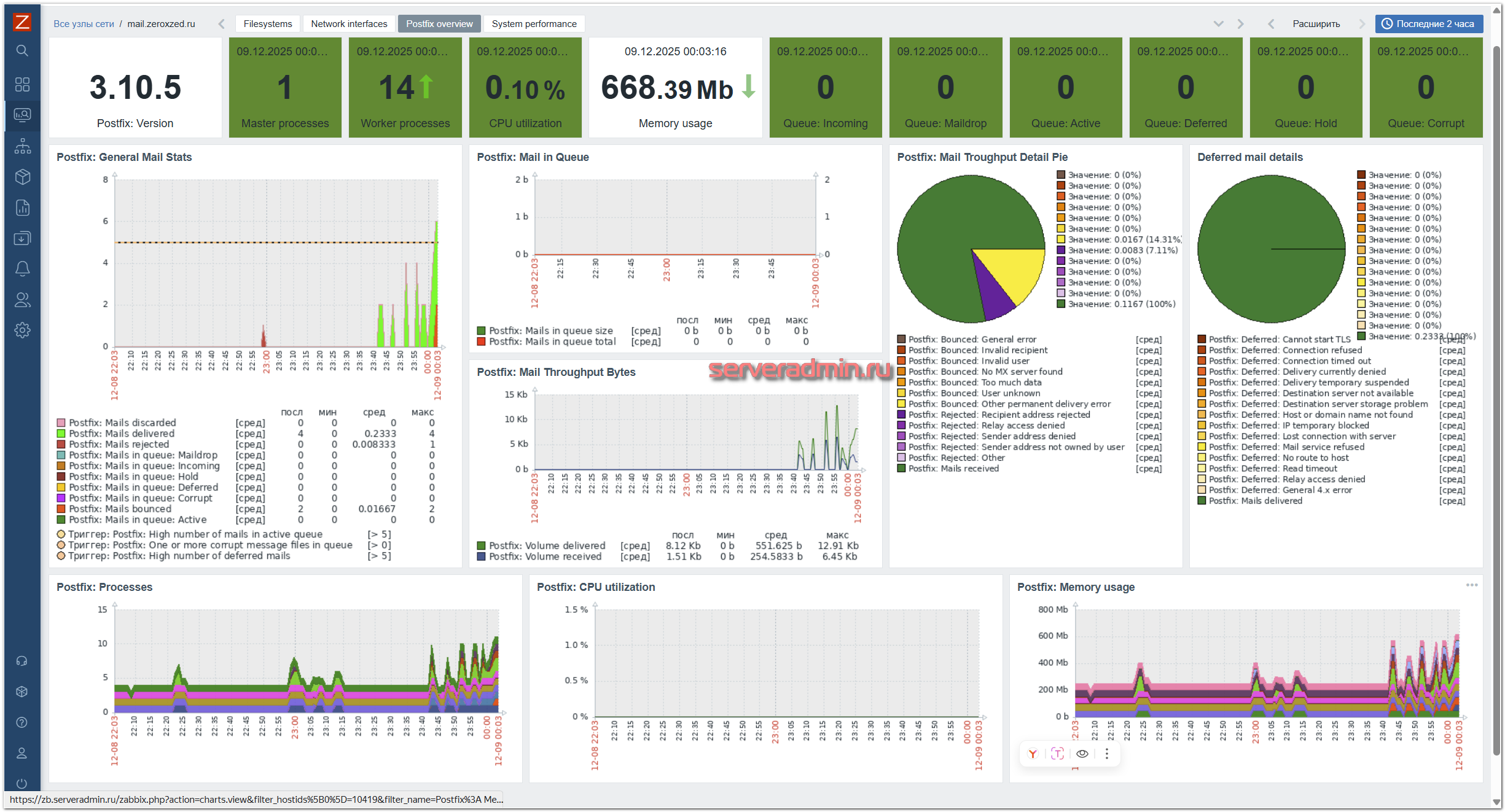
Но в целом панель собрана хорошо. Если сработает какой-то триггер по bounce, rejected или очереди, с помощью панели можно будет быстро оценить состояние сервера.
Единственное, чего мне не хватает в этом шаблоне - триггера на доставленные письма. Если доставленных писем внезапно стало очень много, то это тоже подозрительно. Я в своих шаблонах обычно делал такой триггер с порогом в x5 от среднего числа писем за прошлый час. Сюда нетрудно его добавить, если вам будет нужна эта метрика. Ключ postfix.mail.delivered собирает эти значения.
Заключение
Если вам интересна тема мониторинга Postfix с помощью Zabbix, и вы хотите в ней разобраться получше, можете посмотреть мою прошлую статью по этой теме. Я сохранил её в виде отдельного файла. Не стал публиковать тут же на сайте, чтобы не было разного материала на одну и ту же тему. В той статье больше практики в виде скриптов и теории в виде самодельного шаблона, айтемов и триггеров к нему с подробным описанием каждого. Я там сам собирал шаблон и добавлял в него триггеры по своему усмотрению, которые считал наиболее актуальными для почтового сервера. Плюс, я там собираю сводную статистику по полученным и отправленным письмам за сутки. Возможно вам будут нужны эти данные.
Странно, что команда Zabbix до сих пор не сделала свой шаблон для Postfix. Это самый популярный почтовый сервер в экосистеме Linux. Мне кажется, он наравне с другими службами, типа Apache или Nginx заслуживает своего шаблона. Альтернативой предложенному шаблону может служить Prometheus exporter for Postfix. Он есть в репозитории Debian. Из него легко передать метрики в Zabbix через встроенную предобработку метрик Prometheus.
На углубленном курсе "Архитектура современных компьютерных сетей" вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315

>>в котором указано расписание запуска скриптов hourly
01 * * * * root run-parts /etc/cron.hourly
>>То есть каждую минуту.
То есть каждый час
CentOS 8, Zabbix server 6.2.0 - настроил, под свои задачи адаптировал, все замечательно.
Владимир, спасибо большое!
Благодарю за статью!
CentOS 8, после ротации maillog ведется в старый переименованный/удаленный файл, новый maillog пустой. После перезапуска службы syslog (systemctl restart syslog.service) лог начинает вестись. Вообщем, как выяснилось, вставил из статьи блок касающийся ротации maillog целиком и не глядя. Закоментированная строка причина некорректной работы
-------
cat /etc/logrotate.d/syslog
/var/log/cron
/var/log/messages
/var/log/secure
/var/log/spooler
{
missingok
sharedscripts
postrotate
/usr/bin/systemctl -s HUP kill rsyslog.service >/dev/null 2>&1 || true
endscript
}
/var/log/maillog
{
daily
missingok
sharedscripts
rotate 10
compress
postrotate
# для CentOS8
/usr/bin/systemctl -s HUP kill rsyslog.service >/dev/null 2>&1 || true
# для CentOS7
# /bin/kill -HUP `cat /var/run/syslogd.pid 2> /dev/null` 2> /dev/null || true
endscript
}
Добрый день!
Только начал изучать zabbix, решаю небольшие задачи. Сервер Ubuntu на нем сайт с формой обратной связи, данные с нее приходят на почтовый ящик, установлен postfix. Zabbix должен будет проверять наличие почты, отправленной через форму обратной связи. Записывать её в файл и загружать на FTP. Нашел вашу статью, но пока для меня сложно. Направьте в нужном направлении. Спасибо!
Замечательная статья, автору респект.
Пробую прикрутить на openSUSE. Проблема в том, что логи пишет journalctl.
Пробую реализовать journalctl --since=today -u postfix | pflogsumm -h 0 -u 0 --bounce_detail=0 …….
Есть вопрос к автору. Pflogsumm считает одно письмо за 3. т.к. к постфиксу прикручен spamassassin и amavis. НЕ могу придумать как это побороть.
Сталкивался с проблемой задваивания и затраивания писем из-за дополнительных обработчиков. В свое время так ее и не решил. Простого способа не знаю. Каким-то образом предобработку на bash надо делать, а потом уже обработанный лог отдавать pflogsumm.
Спасибо за статью.
При реализации столкнулся с такой проблемой:
# zabbix_agentd -t postfix.delivered-full
postfix.delivered-full [t|Unknown option: bounce_detail
Unknown option: deferral_detail
Unknown option: reject_detail
Unknown option: smtpd_warning_detail
usage: pflogsumm.pl -[eq] [-d ] [-h ] [-u ]
[--verp_mung[=]] [--verbose_msg_detail] [--iso_date_time]
[-m|--uucp_mung] [-i|--ignore_case] [--smtpd_stats] [--mailq]
[--problems_first] [--rej_add_from] [--no_bounce_detail]
[--no_deferral_detail] [--no_reject_detail] [--no_no_msg_size]
[--no_smtpd_warnings] [--zero_fill] [--syslog_name=name]
[file1 [filen]]
Не подскажете в чем может быть проблема?
Так трудно сказать. Что-то напутано в настройках или скриптах. Попробуйте все отладить сначала без zabbix, в bash. А потом уже в мониторинг переносить.
Статья актуальна. Только что по ней настроил мониторинг почтового сервера на Centos 8.
Практичней испльзовать https://github.com/aadz/mlogtail который работает в реальном времени и не надо постоянно запускать pflogsum, чтобы вычитать хвост лога.
Хорошая статья, все получилось кроме пары нюансов.
Тригеры которые отвечаю за проверку работы smtp и imap в ответ на запрос получают 0 тем самым вылазит проблемачтоэти сервисы не запущенны.
Вот что я получаю если делаю запрос с zabbix сервера:
# zabbix_get -s agent.host -k net.tcp.service[smtp]
0
# zabbix_get -s agent.host -k net.tcp.service[imap]
0
SELinux на сервер почты отключен. срабатывает только если заменить service на listen и соответственно вместо [smtp] писать порт [465]:
# zabbix_get -s agent.host -k net.tcp.listen[465]
1
Подскажите куда копать?
Оставьте так, как работает. Я не помню точно, какие порты в Zabbix указаны в качестве smtp и imap порта. Скорее всего 25 и 143. Если у вас другие порты, то укажите их вручную, как вы и сделали.
То что порт другие это не проблема. Меня куда больше интересует почему на запрос допустим (порты неважно какие):
# zabbix_get -s agent.host -k net.tcp.service[465]
Возвращает 0
А вот при запросе (тут тоже неважно какие порты):
# zabbix_get -s agent.host -k net.tcp.listen[465]
Возвращает 1
Сделал проверку работы https:
# zabbix_get -s 195.54.14.68 -k net.tcp.service[https]
Возвращает 1
Т.е. конструкция net.tcp.service не срабатывает как для smtp и imap. А вот конструкция net.tcp.listen работает.
Правильно проверку на нестандартном порту в общем случае делать вот так:
zabbix_get -s agent.host -k net.tcp.service[smtp,,465]
Подробнее тут - https://www.zabbix.com/documentation/4.0/ru/manual/config/items/itemtypes/simple_checks
Там же по ссылке есть пометка:
"Проверка шифрованных протоколов (таких как IMAP на 993 порту или POP на 995 порту) в настоящее время не поддерживается. Как решение, пожалуйста, для подобных проверок используйте net.tcp.service[tcp,,порт]."
Подозреваю, что для шифрованного smtp проверка тоже не будет работать. Проверять надо так:
zabbix_get -s agent.host -k net.tcp.service[tcp,,465]
В случае локальных проверок через агента на том же сервере, я так понимаю, что разницы между net.tcp.service[tcp,,465] и net.tcp.listen[tcp,,465] не будет.
После безуспешных попыток докопаться до истины, решил для обоих проверок запросы для imap и smtp написать так:
net.tcp.listen[993]
net.tcp.listen[465]
Еще раз огромное спасибо за статью!
Лучше просто лог тэйлить и считать/показывать счетчики, которые насчитались - https://github.com/aadz/mlogtail
Можно и так, но сходу не могу оценить, как будет удобнее. Это совсем другой подход. Разные метрики получаются. Можно комбинировать.
Те же метрики получаются, что и у pflogsumm, плюс еще и трафик входящих/доставленных байтов считается так же. на pflogsumm и тестировалось, хотя подход и регулярные выражения - разные. Это да. Просто файл не дергают постоянно, порождая кучу процессов, а просто читают и отдают счпетчикию
А вот комбинировать - я бы вряд ли стал. :)
Спасибо. Отличная статья. Настроил без особых проблем. Debian 8.
Приветствую, отличная статья. сделал все как написано затык случился на скрипте. при параметре queue выдает 65535. это я так понимаю ошибка. подскажите как исправить? centos 7/ zabbix 4/
Смотреть скрипт надо и проверять команду напрямую в консоли, которая очередь показывает, смотреть, что выводит.
Сегодня вот осенила у меня одна мысль) А можно ли заставить zabbix мониторить размер писем. Никто не озадачивался?
В каком виде это должно быть в заббиксе? А главное, зачем это? Через почтовый сервер проходят тысячи и десятки тысяч писем в сутки. Если информацию о них хранить в заббиксе, то его база будет огромных размеров и для нормальной работы понадобятся большие мощности. Заббикс для этой задачи не подходит совершенно. А так, конечно, это реально.
Можно написать скрипт, который будет проверять размер каждого письма, а затем передавать эту информацию в ELK Stack - https://serveradmin.ru/ustanovka-i-nastroyka-elasticsearch-logstash-kibana-elk-stack/
В таком виде это имеет право на жизнь.
У меня идет война с моими юзверами(( Не хотят почту чистить, сервер забит в ноль. Устал уже ругаться в кабинете директора со всеми. Хочу более развернуто мониторить почтовик, во первых статистику по получателям и адресатам, т.е. куда и откуда более всего по конкретному пользователю ходит почта. Так же вчера подумал, а можно ли ткнуть их носом в размер писем, т.е. сколько за день у каждого забивается почтовик. Можно сделать скрипт который будет каждый день срезать размер директории с письмами и собирать ее, но это не совсем то. В общем думаю что еще можно накрутить в мониторинг что бы было чем заставить их чистить почтовик
Странная ситуация. У вас что, директор неадекват? Первый раз такое вижу. Если места для почты нет, то надо что-то сделать. У меня никогда не было ситуации, когда нельзя убедить руководителя в проблеме. Если только вы сами что-то недоговариваете. И ругаться, конечно, нет смысла, это неконструктивно.
Статистику по переписке можно получить с помощью pflogsumm. Посмотрите на него внимательно, он даст почти всю информацию, которую вы хотите получить.
Я, в принципе, вижу проблему и она у вас не технического характера. Вам зачем-то нужно убеждать руководство, пользователей, делая для этого отдельный мониторинг. Не для себя, а для того, чтобы других убеждать. По какой-то причине ваши слова пустое место для всех остальных. Просто советую подумать об этом и сделать выводы.
У меня Гос.унитарное предприятие и экономим на всем, в общем на железо денег не дают. А вот с пользователями из-за нового директора стало совсем худо. Как он говорит ему надо чтобы сотрудникам было удобно работать и если что-то надо то я должен делать, даже если это физически не реально. В общем он полный бардак у нас навел. У нас тех службу и хоз службу держат за пустое место и это вина руководства, при предыдущем директоре таких проблем не было.
pflogsumm действительно дает, но визуализировать надо, он же в текст пишет в основном.
Те данные, что дает pflogsumm, можно передавать в zabbix для визуализации. Текущая статья как раз об этом. Но реально, это все пустое. Вы заморочитесь, но физическую проблему с местом это не решит.
Я бы поступил так в вашем случае:
1. Первым делом ограничил бы максимальный размер письма 20-ю мегабайтами. Это нормальная, общераспространенная практика. По-моему опыту без этого невозможно ограничить почтовые архивы разумными рамками. Пользователи начинают пересылать большие файлы и это не остановить.
2. Написал понятную инструкцию с картинками по очистке почтового ящика самим пользователем. В инструкции бы обратил внимание на сортировку писем с вложениями по объему. Рассказал бы, как сохранить вложение на сетевой диск, где оно будет в полной сохранности, так как диски бэкапятся, в отличии от почтового ящик (маленькая хитрость).
3. Собрал размер всех ящиков и посмотрел на самых больших. Что занимает больше всего места. Настроил бы еженедельную проверку размера ящиков, чтобы следить за динамикой, а так же чтобы понимать, кто больше всего занимает места.
4. Настроил на сервере регулярную автоочистку папок для спама и корзин. У меня тоже есть статья на эту тему.
5. Написал бы письменно директору с обозначением проблемы и списком мер для решения проблемы (очистка ящиков, ограничение на размер ящика, покупка дисков и т.д.). Если меры приняты не будут, то ты не можешь гарантировать стабильную работу почтового сервера
В общем, тут надо подходить комплексно и с головой, а не воевать с пользователями. Худой мир лучше доброй войны. Можно разок плановый коллапс устроить и ручками аккуратно поломать почту, а потом сказать, что это будет происходить регулярно, если ничего не предприянть.
Добрый день. Не могу шаблон загрузить.
Детали
Не удалось прочитать XML: (68) StartTag: invalid element name [Строка: 939 | Колонка: 62].
Версия Zabbix-server какая?
С заббикс-сервера возвращает ноль:
$ zabbix_get -s postfix -k postfix.received-full
0
копаю дальше
Template Postfix: Postfix: Received Day postfix.received-full 600 90d 365d Zabbix агент Postfix Активировано
Template Postfix: Postfix: Delivered Day postfix.delivered-full 600 90d 365d Zabbix агент Postfix Активировано
В какую сторону копать, если
$ zabbix_agentd -t postfix.received-full
postfix.received-full [t|2543]
$ zabbix_agentd -t postfix.delivered-full
postfix.delivered-full [t|5365]
а в заббиксе в Последних данных Postfix: Received Day и Postfix: Delivered Day нулевые?
Начать с того, что посмотреть на сами итемы в узле сети. В каком они состоянии. Возможно, там будет указано, что итем не активен и сама ошибка будет названа.
Один триггер криво работает в шаблоне и вроде я понял почему)
{post:postfix[delivered].sum(3605)} > {post:postfix[delivered].sum(3605,3605)}*5
Если я правильно понял, то правая часть считает кол-во писем за предыдущий час, т.е. отматывает 3605 секунда назад и считает кол-во за 3605 секунд (предыдущий час). И всё бы хорошо, но если писем было ноль в предыдущем часу, то помноженный он на 5 - это никак не в 5 раз больше писем за прошедший час, в котором, к примеру, было только одно письмо.
Да, верно, я это не учел. У меня нет почтовых серверов, где за час не было ни одного письма :) Все никак не прикручу мониторинг, который будет раз в 5 минут отправлять реальное письмо и проверять, появилось ли оно в папке. А то уже не раз бывали ситуации, когда по мониторингу все ОК, но почта не ходит по какой-то причине. Увидеть это можно только, если отправляешь живое письмо. Тогда наверняка будешь знать, работает почта или нет. Все остальное не так надежно. Тогда проблемы с нулем писем в этом триггере не будет, так как мониторинг сам писем наотправляет.
Проверять в папке "Отправленных" имеется в виду?
Можно сделать триггер аналогично, если отправленных писем в принципе не будет за какое-то время.
Не обязательно в отправленные. Оно может отправиться, но не прийти на сервер по какой-то причине. Нужно отправлять и проверять письмо именно во входящих адресата. Тогда точно можно знать, что почта доходит. Хотя можно отдельно прием и отправку проверять. В принципе, это два разных процесса и они могут независимо друг от друга сломаться. Имеет смысл и то и другое проверять.
Так отправлять и проверять пришло ли письмо в пределах одного почтового сервера?
В идеале конечно с разных, если есть такая возможность. Но и с одного тоже можно.
Шаблон сделан для zabbix версии 3.2 в 3.0 не импортируется уже. Есть вариант добавления для более старых версий или надо всё вручную вбивать?
Не могу ничего посоветовать. Не осталось версий, ниже 3.2. Проще всего, мне кажется, обновиться. Там нет никаких проблем с обновлением.
Ребят, помогите, может кто сталкивался. Пытаюсь настроить все по мануалу, но в итоге в логах вижу следующее:
1410:20170826:075731.827 item "elektron:postfix[queue]" became not supported: Unsupported item key.
1409:20170826:080322.103 item "elektron:postfix.delivered-full" became not supported: Unsupported item key.
И т.д.
В самом Заббиксе, в последних данных все параметры типа Postfix: bytes delivered серого цвет и данных нет.
Подскажите, куда глянуть, что может быть причиной.
Скрипт не отрабатывает по какой-то причине. Нужно пробовать его запускать от пользователя zabbix, смотреть, чтобы прав на все хватало. Либо в самом скрипте ошибка и в выводе не цифры, а что-то другое.
В общем случае эта ошибка означает, что сервер заббикса получает не цифровые значения, а что-то другое. Нужно разбираться, что конкретно.
Отличная статья.
Все по полкам разложил.
Настроил на своем сервере под Centos 6.4.
Затык произошел при настройке доступа пользователя, от которого запускается Zabbix к лог файлу Postfix'а:
zabbix ALL=(ALL) NOPASSWD: /bin/cat /var/log/maillog - это через sudoers не заработало.
Немного поискав, сделал через доп настройку в logrotate:
postrotate
/bin/kill -HUP `cat /var/run/syslogd.pid 2> /dev/null` 2> /dev/null || true
/bin/chmod 640 /var/log/maillog
/bin/chown :zabbix /var/log/maillog
endscript
Таким образом у юзера zabbix есть права на чтение лога.
Плюс ко всему, при проверке скрипта, postfix.sh результат выдавал только с ключом queue, остальные ключи [received/rejected/...] ничего не возвращали.
Разобрал скрипт и выполнив его покомандно в баше нашел, что строка:
DATA_CACHE=`sudo cat ${MAILLOG} | sed -e 's/^\([a-zA-Z]\{3\}\s\)\s\([0-9]\s\)/\10\2/g' | awk '$2" "$3>=from && $2" "$3&1`
возвращает:
-bash: /usr/sbin/pflogsumm: Нет такого файла или каталога
решилось удалением символа "\" перед ${PFLOGSUMM} -h 0 ...
Да, нюансов может быть много. Я сам постоянно разбираюсь с разными ситуациями на разных серверах. Поэтому постарался расписать все подробно, чтобы можно было самостоятельно дебажить работу. В готовом виде универсальный инструмент тут не подготовить, надо на месте разбираться.
Неплохо, может есть аналог настройки мониторинга для exim ?
Надо смотреть, какой там формат лога, и парсить его. Я не знаком с Exim совсем. Триггеры для примера можно взять из этой статьи, мониторинг сервисов и служб тоже. Статистику только переделывать придется.