
Большие информационные системы генерируют огромное количество служебной информации, которую нужно где-то хранить. Я расскажу о том, как настроить хранилище для логов на базе Elasticsearch, Logstash и Kibana, которое называют ELK Stack. В это хранилище можно настроить отправку практически любых логов в разных форматах и большого объема.
На углубленном курсе "Архитектура современных компьютерных сетей" вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Введение
Я буду настраивать одиночный хост. В данной статье будут самые азы - как сделать быструю установку и базовую настройку, чтобы можно было собирать логи в Elasticsearch и смотреть их в Kibana. Для примера, настрою сбор логов как с linux, так и windows серверов. Инструкция по установке будет полностью основана на официальной документации. Если вы хорошо читаете английские тексты, то можете использовать ее. Неудобство будет в том, что вся информация разрозненно располагается в разных статьях. Если вы первый раз настраиваете ELK Stack, то будет трудно сразу во всем разобраться. В своей статье я собрал в одном месте необходимый минимум для запуска Elasticsearch, Logstash, Kibana и агентов Filebeat и Winlogbeat для отправки логов с серверов.
Что такое ELK Stack
Расскажу своими словами о том, что мы будем настраивать. Ранее на своем сайте я уже рассказывал о централизованном сборе логов с помощью syslog-ng. Это вполне рабочее решение, хотя очевидно, что когда у тебя становится много логов, хранить их в текстовых файлах неудобно. Надо как-то обрабатывать и выводить в удобном виде для просмотра. Именно эти проблемы и решает представленный стек программ:
- Elasticsearch используется для хранения, анализа, поиска по логам.
- Kibana представляет удобную и красивую web панель для работы с логами.
- Logstash сервис для сбора логов и отправки их в Elasticsearch. В самой простой конфигурации можно обойтись без него и отправлять логи напрямую в еластик. Но с logstash это делать удобнее.
- Beats - агенты для отправки логов в Logstash или Elasticsearch. Они бывают разные. Я буду использовать Filebeat для отправки данных из текстовых логов linux и Winlogbeat для отправки логов из журналов Windows систем.
К этой связке еще добавляется Nginx, который проксирует соединения в Kibana. В самом простом случае он не нужен, но с ним удобнее. Можно, к примеру, добавить авторизацию или ssl сертификат, в nginx удобно управлять именем домена. В случае большой нагрузки, разные службы разносятся по разным серверам или кластерам. В своем примере я все установлю на один сервер. Схематично работу данной системы можно изобразить вот так: 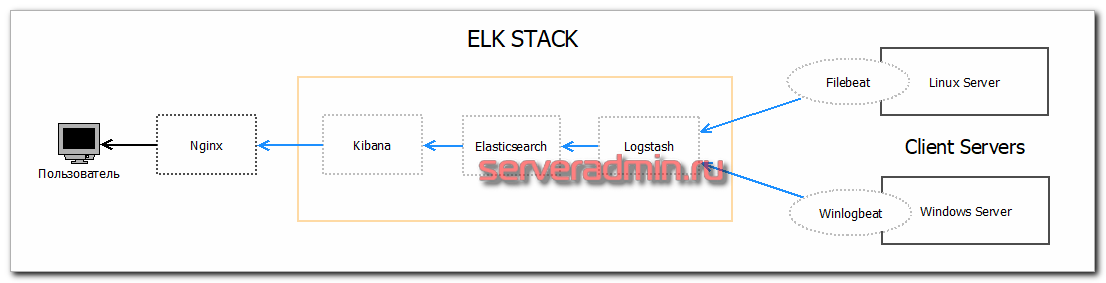 Начнем по этапам устанавливать и настраивать все компоненты нашей будущей системы хранения и обработки логов различных информационных систем.
Начнем по этапам устанавливать и настраивать все компоненты нашей будущей системы хранения и обработки логов различных информационных систем.
Если у вас еще нет своего сервера с CentOS 8, то рекомендую мои материалы на эту тему:
Если у вас еще не настроен сервер с Debian, рекомендую мои материалы на эту тему:
Раньше для установки всех перечисленных компонентов необходимо было отдельно устанавливать Java на сервер. Сейчас в этом нет необходимости, так как Java уже включена в пакеты устанавливаемого ПО.
Системные требования
Для установки одиночного инстанса с полным набором компонентов ELK необходимы следующие системные ресурсы.
| минимальные | рекомендуемые | |
| CPU | 2 | 4+ |
| Memory | 6 Gb | 8+ Gb |
| Disk | 10 Gb | 10+ Gb |
Некоторое время назад для тестовой установки ELK Stack достаточно было 4 Gb оперативной памяти. На текущий момент с версией 8.17.0 у меня не получилось запустить одновременно Elasticsearch, Logstash и Kibana на одной виртуальной машине с четырьмя гигабайтами памяти. После того, как увеличил до 6, весь стек запустился. Но для комфортной работы с ним нужно иметь не менее 8 Gb и 4 CPU. Если меньше, то виртуальная машина начинает тормозить, очень долго перезапускаются службы. Работать некомфортно. Можно ограничить потребление оперативной памяти в настройках elasticsearch, чтобы он запустился с меньшей доступной памятью. Ниже я покажу как это сделать. Тем не менее, для нормальной работы с нагрузкой ему нужно 6+ Gb.
В системных требованиях для ELK я указал диск в 10 Gb. Этого действительно хватит для запуска стека и тестирования его работы на небольшом объеме данных. В дальнейшем, понятное дело, необходимо ориентироваться на реальный объем данных, которые будут храниться в системе.
Установка Elasticsearch
Устанавливаем ядро системы по сбору логов - Elasticsearch. Его установка очень проста за счет готовых пакетов под все популярные платформы.
Ubuntu / Debian
Копируем себе публичный ключ репозитория:
# wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Если у вас нет пакета apt-transport-https, то надо установить:
# apt install apt-transport-https
Добавляем репозиторий Elasticsearch в систему:
echo "deb https://artifacts.elastic.co/packages/8.x/apt stable main" | tee -a /etc/apt/sources.list.d/elastic-8.x.list
Если у вас нет доступа к репозиторию, то можете воспользоваться моим. Я создал копию репозитория elastic для Debian 11 и 12. Под все остальные системы можно через браузер скачать нужный пакет и установить вручную. Подключаем к Debian 11:
# echo "deb http://elasticrepo.serveradmin.ru bullseye main" | tee /etc/apt/sources.list.d/elasticrepo.list
# wget -qO - http://elasticrepo.serveradmin.ru/elastic.asc | apt-key add -
Подключаем к Debian 12:
# echo "deb http://elasticrepo.serveradmin.ru bookworm main" | tee /etc/apt/sources.list.d/elasticrepo.list
# wget -qO - http://elasticrepo.serveradmin.ru/elastic.asc | apt-key add -
Устанавливаем Elasticsearch на Debian или Ubuntu:
# apt update && apt install elasticsearch
В консоли вы увидите некоторую полезную информацию, которую имеет смысл сохранить.
- Пароль встроенной учётной записи elastic с полными правами.
- Команда на сброс пароля для elastic.
- Команда для генерации токена доступа для Kibana.
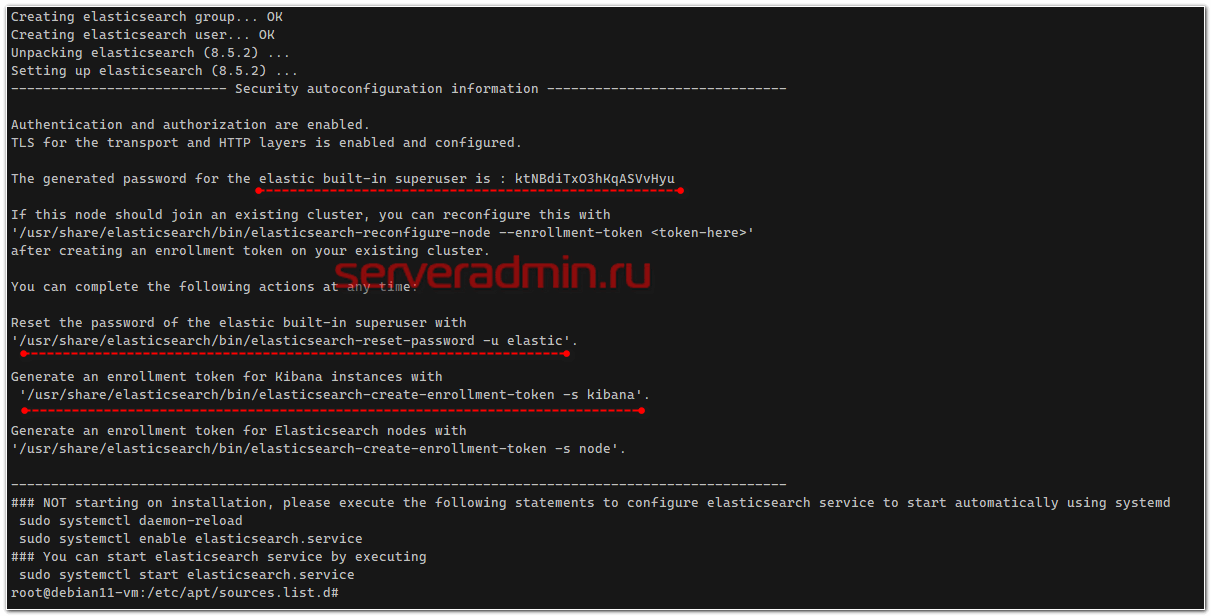
После установки добавляем elasticsearch в автозагрузку и запускаем.
# systemctl daemon-reload # systemctl enable elasticsearch.service # systemctl start elasticsearch.service
Проверяем, запустился ли он:
# systemctl status elasticsearch.service
Проверим теперь, что elasticsearch действительно нормально работает. Выполним к нему простой запрос об его статусе. Здесь нам уже пригодится учётная запись с правами доступа к кластеру. Неавторизованные запросы, а также запросы по HTTP в 8-й версии elasticsearch не принимаются.
# # curl -k --user elastic:'ktNBdiTxO3hKqASVvHyu' https://127.0.0.1:9200
{
"name" : "debian11-vm",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "vuinIS6tRACwasu9nG2kdw",
"version" : {
"number" : "8.5.2",
"build_flavor" : "default",
"build_type" : "deb",
"build_hash" : "a846182fa16b4ebfcc89aa3c11a11fd5adf3de04",
"build_date" : "2022-11-17T18:56:17.538630285Z",
"build_snapshot" : false,
"lucene_version" : "9.4.1",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}
В случае запроса по HTTP, а не HTTPS, в логе Elasticsearch будет ошибка:
received plaintext http traffic on an https channel, closing connection Netty4HttpChannel{localAddress=/127.0.0.1:9200, remoteAddress=/127.0.0.1:39964
Если у вас всё в порядке, то переходим к настройке Elasticsearch.
Centos Stream, Rocky Linux, Almalinux, Oracle Linux
Установка Elasticsearch на rpm операционные системы (Centos, Rocky Linux, Almalinux, Oracle Linux) ничем не отличается от deb систем. Копируем публичный ключ репозитория:
# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
Подключаем репозиторий Elasticsearch:
# mcedit /etc/yum.repos.d/elasticsearch.repo
[elastic-8.x] name=Elastic repository for 8.x packages baseurl=https://artifacts.elastic.co/packages/8.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md
Приступаем к установке еластика:
# yum install --enablerepo=elasticsearch elasticsearch
Если скачали пакет вручную с любого компьютера, скопировали на сервер, то установить можно следующим образом:
# rpm -ivh elasticsearch-8.5.2-x86_64.rpm
В консоли вы увидите некоторую полезную информацию, которую имеет смысл сохранить.
- Пароль встроенной учётной записи elastic с полными правами.
- Команда на сброс пароля для elastic.
- Команда для генерации токена доступа для Kibana.
В в завершении установки добавим elasticsearch в автозагрузку и запустим его с дефолтными настройками:
# systemctl daemon-reload # systemctl enable elasticsearch.service # systemctl start elasticsearch.service
Проверяем, запустилась ли служба:
# systemctl status elasticsearch.service
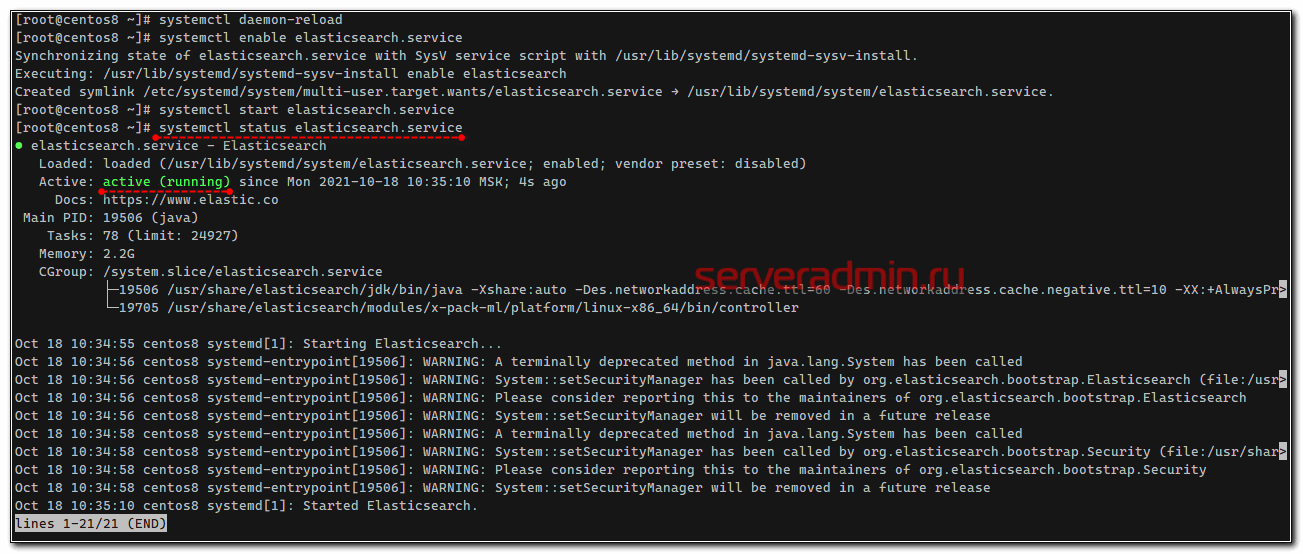
Проверим теперь, что elasticsearch действительно нормально работает. Выполним к нему простой запрос о его статусе, не забывая об аутентификации.
# curl -k --user elastic:'ktNBdiTxO3hKqASVvHyu' https://127.0.0.1:9200
{
"name" : "rockylinux8",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "vuinIS6tRACwasu9nG2kdw",
"version" : {
"number" : "8.5.2",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "a846182fa16b4ebfcc89aa3c11a11fd5adf3de04",
"build_date" : "2022-11-17T18:56:17.538630285Z",
"build_snapshot" : false,
"lucene_version" : "9.4.1",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
},
"tagline" : "You Know, for Search"
}
Все в порядке, сервис реально запущен и отвечает на запросы.
Настройка Elasticsearch
Настройки Elasticsearch находятся в файле /etc/elasticsearch/elasticsearch.yml. На начальном этапе нас будут интересовать следующие параметры:
path.data: /var/lib/elasticsearch # директория для хранения данных network.host: 127.0.0.1 # слушаем только локальный интерфейс
http.host: 127.0.0.1 # слушаем только локальный интерфейс
По умолчанию Elasticsearch слушает localhost. Нам это и нужно, так как данные в него будет передавать logstash, который будет установлен локально. Обращаю отдельное внимание на параметр для директории с данными. Чаще всего они будут занимать значительное место, иначе зачем нам Elasticsearch. Подумайте заранее, где вы будете хранить логи. Все остальные настройки я оставляю дефолтными. После изменения настроек, надо перезапустить службу:
# systemctl restart elasticsearch.service
Смотрим, что получилось:
# ss -tulnp | grep 9200
tcp LISTEN 0 4096 [::ffff:127.0.0.1]:9200 *:* users:(("java",pid=26654,fd=540))
Elasticsearch повис на локальном интерфейсе. Причем я вижу, что он слушает ipv6, а про ipv4 ни слова. Но его он тоже слушает, так что все в порядке. Если вы хотите, чтобы elasticsearch слушал все сетевые интерфейсы, настройте параметр:
network.host: 0.0.0.0
Только не спешите сразу же запускать службу. Если запустите, получите ошибку:
[2021-10-18T10:41:51,062][ERROR][o.e.b.Bootstrap ] [centos8] node validation exception [1] bootstrap checks failed. You must address the points described in the following [1] lines before starting Elasticsearch. bootstrap check failure [1] of [1]: the default discovery settings are unsuitable for production use; at least one of [discovery.seed_hosts, discovery.seed_providers, cluster.initial_master_nodes] must be configured
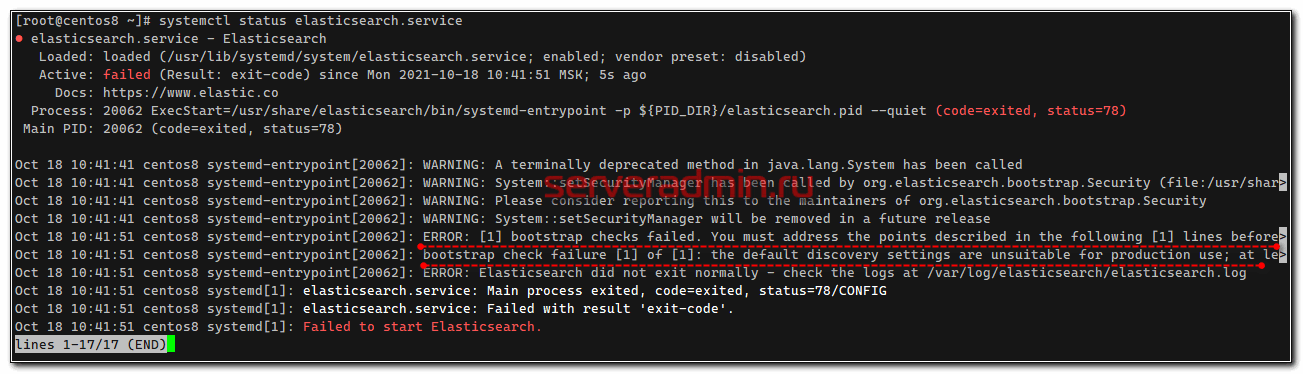
Чтобы ее избежать, дополнительно надо добавить еще один параметр:
discovery.seed_hosts: ["127.0.0.1", "[::1]"]
Этим мы указываем, что хосты кластера следует искать только локально.
По умолчанию в настройках виртуальной машины Java для Elasticsearch указано, что он автоматически выбирает объём использования оперативной памяти в зависимости от того, что есть из доступного в системе. Если вы хотите вручную ограничить его в этом, то отредактируйте соответствующие параметры в файле /etc/elasticsearch/jvm.options, а лучше создайте отдельный корректирующий файл с настройками в папке /etc/elasticsearch/jvm.options.d/mem.options, где укажите параметры:
-Xms2g
-Xmx2g
В данном примере я указал использовать не более двух гигабайт оперативной памяти. Это подойдёт для тестовых установок. Для постоянной работы лучше оставить настройки по умолчанию или указать не менее 4-х гигабайт. После изменения этих настроек, службу надо перезапустить, как мы это делали ранее.
Переходим к установке Kibana.
Установка Kibana
Дальше устанавливаем web панель Kibana для визуализации данных, полученных из Elasticsearch. Тут тоже ничего сложного, репозиторий и готовые пакеты есть под все популярные платформы. Репозитории и публичный ключ для установки Kibana будут такими же, как в установке Elasticsearch. Но я еще раз все повторю для тех, кто будет устанавливать только Kibana, без всего остального. Это продукт законченный и используется не только в связке с Elasticsearch.
Centos Stream, Rocky Linux, Almalinux, Oracle Linux
Импортируем ключ репозитория:
# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
Добавляем конфиг репозитория:
# mcedit /etc/yum.repos.d/kibana.repo
[elastic-8.x] name=Elastic repository for 8.x packages baseurl=https://artifacts.elastic.co/packages/8.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md
Запускаем установку Kibana:
# yum install kibana
Если репозиторий заблокирован, то качаем и копируем файл вручную, запускаем установку:
# rpm -ivh kibana-8.5.2-amd64.deb

Добавляем Кибана в автозагрузку и запускаем:
# systemctl daemon-reload # systemctl enable kibana.service # systemctl start kibana.service
Проверяем состояние запущенного сервиса:
# systemctl status kibana.service
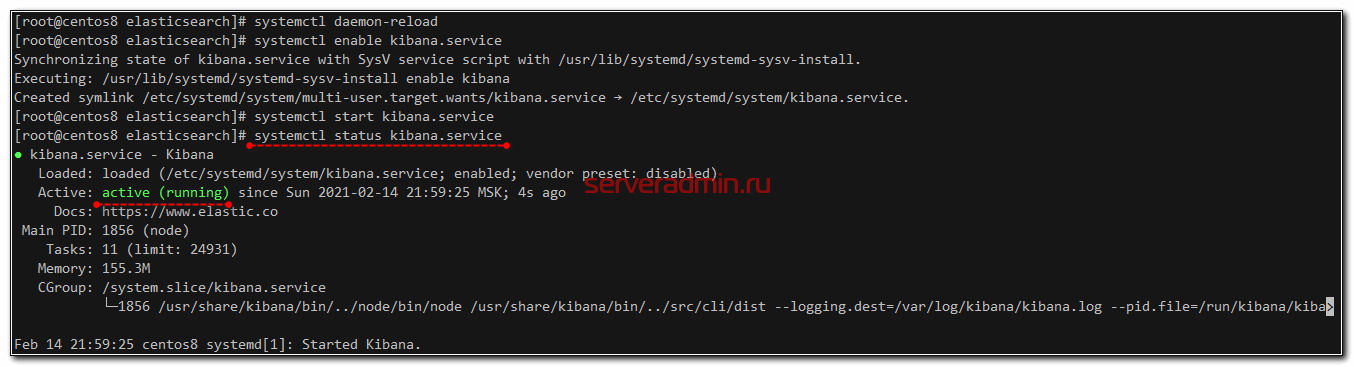
По умолчанию, Kibana слушает порт 5601. Только не спешите его проверять после запуска. Кибана стартует долго. Подождите примерно минуту и проверяйте.
# netstat -tulnp | grep 5601 tcp 0 0 127.0.0.1:5601 0.0.0.0:* LISTEN 20746/node
Ubuntu, Debian
Установка Kibana на Debian или Ubuntu такая же, как и на центос - подключаем репозиторий и ставим из deb пакета. Добавляем публичный ключ:
# wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | apt-key add -
Добавляем репозиторий Kibana:
# echo "deb https://artifacts.elastic.co/packages/8.x/apt stable main" | tee -a /etc/apt/sources.list.d/elastic-8.x.list
Или мой репозиторий:
# echo "deb http://elasticrepo.serveradmin.ru bullseye main" | tee /etc/apt/sources.list.d/elasticrepo.list
# wget -qO - http://elasticrepo.serveradmin.ru/elastic.asc | apt-key add -
Запускаем установку Kibana:
# apt update && apt install kibana
Добавляем Кибана в автозагрузку и запускаем:
# systemctl daemon-reload # systemctl enable kibana.service # systemctl start kibana.service
Проверяем состояние запущенного сервиса:
# systemctl status kibana.service
По умолчанию, Kibana слушает порт 5601. Только не спешите его проверять после запуска. Кибана стартует долго. Подождите примерно минуту и проверяйте.
# ss -tulnp | grep 5601
tcp LISTEN 0 511 127.0.0.1:5601 0.0.0.0:* users:(("node",pid=27166,fd=20))
Настройка Kibana
Файл с настройками Кибана располагается по пути - /etc/kibana/kibana.yml. На начальном этапе нам нужно корректно настроить подключение к серверу elasticsearch. По умолчанию Kibana слушает только localhost и не позволяет подключаться удаленно. Это нормальная ситуация, если у вас будет на этом же сервере установлен nginx в качестве reverse proxy, который будет принимать подключения и проксировать их в Кибана. Так и нужно делать в production, когда системой будут пользоваться разные люди из разных мест. С помощью nginx можно будет разграничивать доступ, использовать сертификат, настраивать нормальное доменное имя и т.д. Если же у вас это тестовая установка, то можно обойтись без nginx. Для этого надо разрешить Кибана слушать внешний интерфейс и принимать подключения. Измените параметр server.host, указав ip адрес сервера, например вот так:
server.host: "10.20.1.56"
Если хотите, чтобы она слушала все интерфейсы, укажите в качестве адреса 0.0.0.0.
Далее нам нужно настроить аутентификацию в elasticsearch. Для этого создадим пароль для встроенного пользователя kibana_system:
# /usr/share/elasticsearch/bin/elasticsearch-reset-password -u kibana_system
Сохраняем пароль и добавляем учётку в конфигурацию kibana:
elasticsearch.username: "kibana_system"
elasticsearch.password: "mtbg5rIwh*E*eWuBCECG"
Теперь нам нужно указать сертификат от центра сертификации, который использовал elasticsearch для генерации tls сертификатов. Напомню, что обращения он принимает только по HTTPS. Так как мы не устанавливали подтверждённый сертификат, будем использовать самоподписанный, который был сгенерирован автоматически во время установки elasticsearch. Все созданные сертификаты находятся в директории /etc/elasticsearch/certs. Скопируем их в /etc/kibana и настроим доступ со стороны веб панели:
# cp -R /etc/elasticsearch/certs /etc/kibana
# chown -R root:kibana /etc/kibana/certs
Добавим этот CA в конфигурацию Кибаны:
elasticsearch.ssl.certificateAuthorities: [ "/etc/kibana/certs/http_ca.crt" ]
И последний момент - указываем подключение к elasticsearch по HTTPS:
elasticsearch.hosts: ["https://localhost:9200"]
Теперь Kibana можно перезапустить:
# systemctl restart kibana.service
Идём в веб интерфейс по адресу http://10.20.1.56:5601. Если не открывается, подождите некоторое время. Kibana долго стартует.
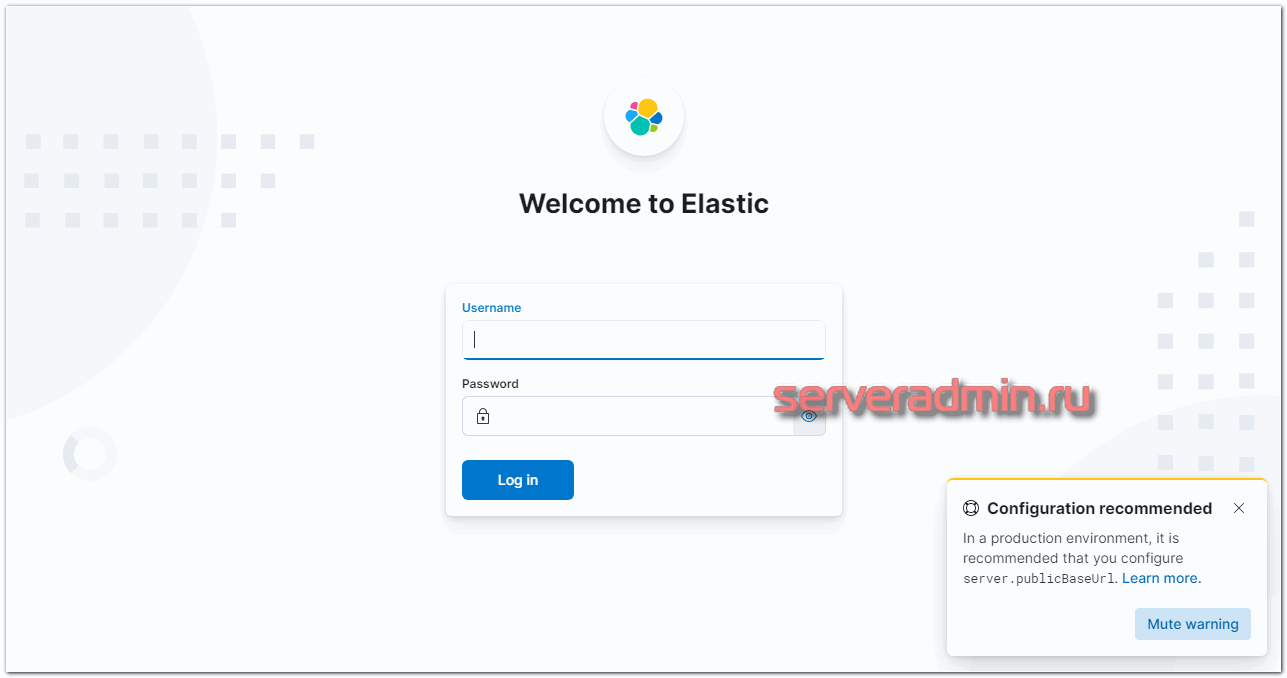
Заходим под учётной записью elastic. Можно продолжать настройку и тестирование, а когда все будет закончено, запустить nginx и настроить проксирование. Я настройку nginx оставлю на самый конец. В процессе настройки буду подключаться напрямую к Kibana. При первом запуске Kibana предлагает настроить источники для сбора логов. Это можно сделать, нажав на Add integrations. К сбору данных мы перейдем чуть позже, так что можете просто изучить интерфейс и возможности этой веб панели
Периодически вы можете видеть в веб интерфейсе предупреждение:
server.publicBaseUrl is missing and should be configured when running in a production environment. Some features may not behave correctly.
Чтобы его не было, просто добавьте в конфиг Kibana параметр:
server.publicBaseUrl: "http://10.20.1.23:5601/"
Или доменное имя, если используете его.
Установка и настройка Logstash
Logstash устанавливается так же просто, как Elasticsearch и Kibana, из того же репозитория. Не буду еще раз показывать, как его добавить. Просто установим его и добавим в автозагрузку. Установка Logstash в Centos:
# yum install logstash
 Установка Logstash в Debian/Ubuntu:
Установка Logstash в Debian/Ubuntu:
# apt install logstash
Добавляем logstash в автозагрузку:
# systemctl enable logstash.service
Запускать пока не будем, надо его сначала настроить. Основной конфиг logstash лежит по адресу /etc/logstash/logstash.yml. Я его не трогаю, а все настройки буду по смыслу разделять по разным конфигурационным файлам в директории /etc/logstash/conf.d. Создаем первый конфиг input.conf, который будет описывать приём информации с beats агентов.
input {
beats {
port => 5044
}
}
Тут все просто. Указываю, что принимаем информацию на 5044 порт. Этого достаточно. Если вы хотите использовать ssl сертификаты для передачи логов по защищенным соединениям, здесь добавляются параметры ssl. Я буду собирать данные из закрытого периметра локальной сети, у меня нет необходимости использовать ssl. Теперь укажем, куда будем передавать данные. Тут тоже все относительно просто. Рисуем конфиг output.conf, который описывает передачу данных в Elasticsearch.
output {
elasticsearch {
hosts => "https://localhost:9200"
index => "websrv-%{+YYYY.MM}"
user => "elastic"
password => "ktNBdiTxO3hKqASVvHyu"
cacert => "/etc/logstash/certs/http_ca.crt"
}
}
Что мы настроили? Передавать все данные в elasticsearch под указанным индексом с маской в виде даты. Разбивка индексов по дням и по типам данных удобна с точки зрения управления данными. Потом легко будет выполнять очистку данных по этим индексам. Для аутентификации я указал учётку elastic, но вы можете сделать и отдельную через Kibana (раздел Stack Management -> Users). При этом можно создавать под каждый индекс свою учётную запись с разрешением доступа только к этому индексу.
Как и в случае с Kibana, для Logstash нужно указать CA, иначе он будет ругаться на недоверенный сертификат elasticsearch и откажется к нему подключаться. Копируем сертификаты и назначаем права:
# cp -R /etc/elasticsearch/certs /etc/logstash
# chown -R root:logstash /etc/logstash/certs
Остается последний конфиг с описанием обработки данных. Тут начинается небольшая уличная магия, в которой я разбирался некоторое время. Расскажу ниже. Рисуем конфиг filter.conf.
filter {
if [type] == "nginx_access" {
grok {
match => { "message" => "%{IPORHOST:remote_ip} - %{DATA:user} \[%{HTTPDATE:access_time}\] \"%{WORD:http_method} %{DATA:url} HTTP/%{NUMBER:http_version}\" %{NUMBER:response_code} %{NUMBER:body_sent_bytes} \"%{DATA:referrer}\" \"%{DATA:agent}\"" }
}
}
date {
match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ]
}
geoip {
source => "remote_ip"
target => "geoip"
add_tag => [ "nginx-geoip" ]
}
}
Первое, что делает этот фильтр, парсит логи nginx с помощью grok, если указан соответствующий тип логов, и выделяет из лога ключевые данные, которые записывает в определенные поля, чтобы потом с ними было удобно работать. С обработкой логов у новичков возникает недопонимание. В документации к filebeat хорошо описаны модули, идущие в комплекте, которые все это и так уже умеют делать из коробки, нужно только подключить соответствующий модуль.
Модули filebeat работают только в том случае, если вы отправляете данные напрямую в Elasticsearch. На него вы тоже ставите соответствующий плагин и получаете отформатированные данные с помощью elastic ingest. Но у нас работает промежуточное звено Logstash, который принимает данные. С ним плагины filebeat не работают, поэтому приходится отдельно в logstash парсить данные. Это не очень сложно, но тем не менее. Как я понимаю, это плата за удобства, которые дает logstash. Если у вас много разрозненных данных, то отправлять их напрямую в Elasticsearch не так удобно, как с использованием предобработки в Logstash.
Для фильтра grok, который использует Logstash, есть удобный дебаггер, где можно посмотреть, как будут парситься ваши данные. Покажу на примере одной строки из конфига nginx. Например, возьмем такую строку из лога:
180.163.220.100 - travvels.ru [05/Sep/2024:14:45:52 +0300] "GET /assets/galleries/26/1.png HTTP/1.1" 304 0 "https://travvels.ru/ru/glavnaya/" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36"
И посмотрим, как ее распарсит правило grok, которое я использовал в конфиге выше.
%{IPORHOST:remote_ip} - %{DATA:user} \[%{HTTPDATE:access_time}\] \"%{WORD:http_method} %{DATA:url} HTTP/%{NUMBER:http_version}\" %{NUMBER:response_code} %{NUMBER:body_sent_bytes} \"%{DATA:referrer}\" \"%{DATA:agent}\"
Собственно, результат вы можете сами увидеть в дебаггере. Фильтр распарсит лог и на выходе сформирует json, где каждому значению будет присвоено свое поле, по которому потом удобно будет в Kibana строить отчеты и делать выборки. Только не забывайте про формат логов. Приведенное мной правило соответствует дефолтному формату main логов в nginx. Если вы каким-то образом модифицировали формат логов, внесите изменения в grok фильтр. Надеюсь понятно объяснил работу этого фильтра. Вы можете таким образом парсить любые логи и передавать их в еластикс. Потом на основе этих данных строить отчеты, графики, дашборды.
Дальше используется модуль date для того, чтобы выделять дату из поступающих логов и использовать ее в качестве даты документа в elasticsearch. Делается это для того, чтобы не возникало путаницы, если будут задержки с доставкой логов. В системе сообщения будут с одной датой, а внутри лога будет другая дата. Неудобно разбирать инциденты.
В конце я использую geoip фильтр, который на основе ip адреса, который мы получили ранее с помощью фильтра grok и записали в поле remote_ip, определяет географическое расположение. Он добавляет новые метки и записывает туда географические данные. Для его работы используется база данных из файла /var/lib/logstash/geoip_database_management/1737033914/GeoLite2-City.mmdb. Она будет установлена вместе с logstash. Впоследствии вы скорее всего захотите ее обновлять. Раньше она была доступна по прямой ссылке, но с 30-го декабря 2019 года правила изменились. База по-прежнему доступна бесплатно, но для загрузки нужна регистрация на сайте сервиса. Регистрируемся и качаем отсюда - https://dev.maxmind.com/geoip/geoip2/geolite2/#Download_Access. Передаем на сервер, распаковываем и копируем в /etc/logstash файл GeoLite2-City.mmdb. Теперь нам нужно в настройках модуля geoip указать путь к файлу с базой. Добавляем в /etc/logstash/conf.d/filter.conf:
geoip {
database => "/etc/logstash/GeoLite2-City.mmdb"
source => "remote_ip"
target => "geoip"
add_tag => [ "nginx-geoip" ]
}
Закончили настройку logstash. Запускаем его:
# systemctl start logstash.service
Можете проверить на всякий случай лог /var/log/logstash/logstash-plain.log, чтобы убедиться в том, что все в порядке. Признаком того, что скачанная geoip база успешно добавлена будет вот эта строчка в логе:
[2021-10-18T12:52:07,118][INFO ][logstash.filters.geoip ][main] Using geoip database {:path=>"/etc/logstash/GeoLite2-City.mmdb"}
Теперь настроим агенты для отправки данных.
Установка Filebeat для отправки логов в Logstash
Установим первого агента Filebeat на сервер с nginx для отправки логов веб сервера на сервер с ELK. Ставить можно как из общего репозитория, который мы подключали ранее, так и по отдельности пакеты. Как ставить - решать вам. В первом случае придется на все хосты добавлять репозиторий, но зато потом удобно обновлять пакеты. Если подключать репозиторий не хочется, можно просто скачать пакет и установить его. Ставим на Centos.
# curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.5.2-x86_64.rpm # rpm -ivh filebeat-8.5.2-x86_64.rpm
В Debian, Ubuntu ставим так:
# curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.5.2-amd64.deb # dpkg -i filebeat-8.5.2-amd64.deb
Или просто:
# yum install filebeat # apt install filebeat
После установки рисуем примерно такой конфиг /etc/filebeat/filebeat.yml для отправки логов в logstash.
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/*-access.log
fields:
type: nginx_access
fields_under_root: true
scan_frequency: 5s
- type: log
enabled: true
paths:
- /var/log/nginx/*-error.log
fields:
type: nginx_error
fields_under_root: true
scan_frequency: 5s
output.logstash:
hosts: ["10.1.4.114:5044"]
xpack.monitoring:
enabled: true
elasticsearch:
hosts: ["http://10.1.4.114:9200"]
Некоторые пояснения к конфигу, так как он не совсем дефолтный и минималистичный. Я его немного модифицировал для удобства. Во-первых, я разделил логи access и error с помощью отдельного поля type, куда записываю соответствующий тип лога: nginx_access или nginx_error. В зависимости от типа меняются правила обработки в logstash.
Запускаем filebeat и добавляем в автозагрузку.
# systemctl enable --now filebeat
Проверяйте логи filebeat в дефолтном системном логе. По умолчанию, он всё пишет туда. Лог весьма информативен. Если все в порядке, увидите список всех логов в директории /var/log/nginx, которые нашел filebeat по маске и начал готовить к отправке. Это события будут от подсистемы input.harvester. Не забудьте проверить свою маску, соответствует ли она той, что указана у меня в конфигурации.
Если все сделали правильно, то данные уже потекли в elasticsearch. Мы их можем посмотреть в Kibana. Для этого открываем web интерфейс и переходим в раздел Discover. Так как там еще нет представления для нового индекса, нам предложат его добавить. Нажимайте Create data view.
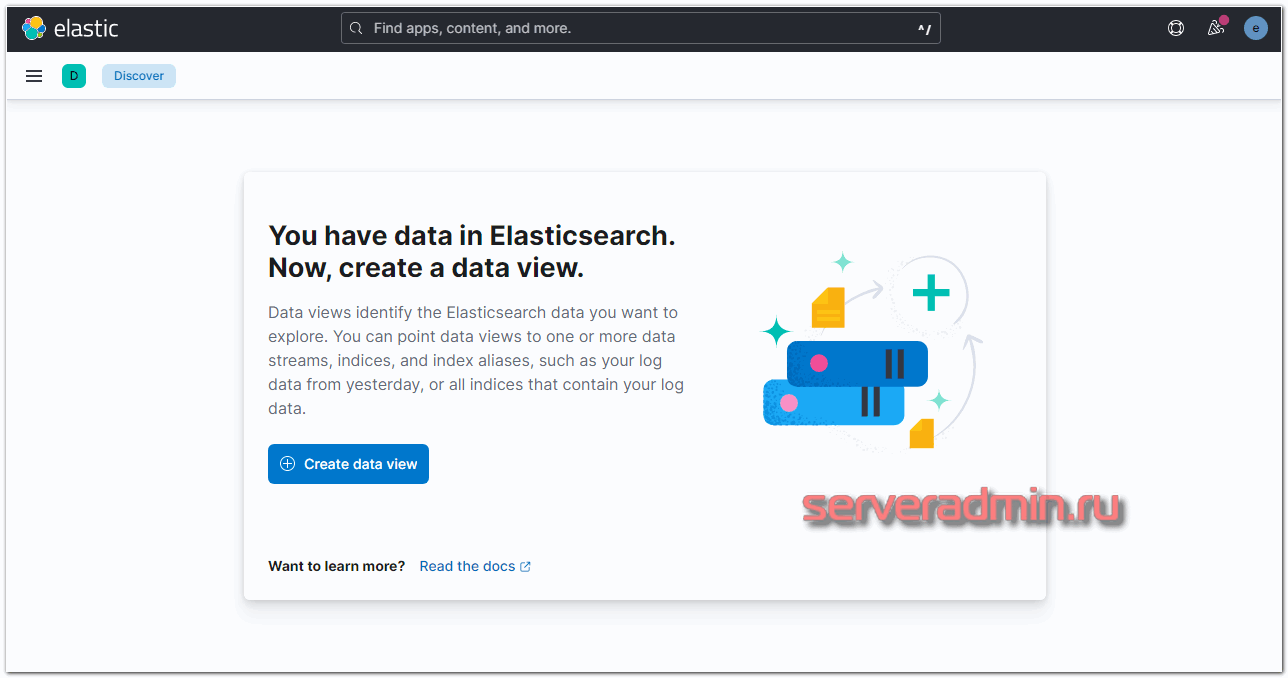
Вы должны увидеть индекс, который начал заливать logstash в elasticsearch. В поле Index pattern введите websrv-* . Выберите имя поля для временного фильтра. У вас будет только один вариант - @timestamp, выбирайте его и жмите Save data view to Kibana.
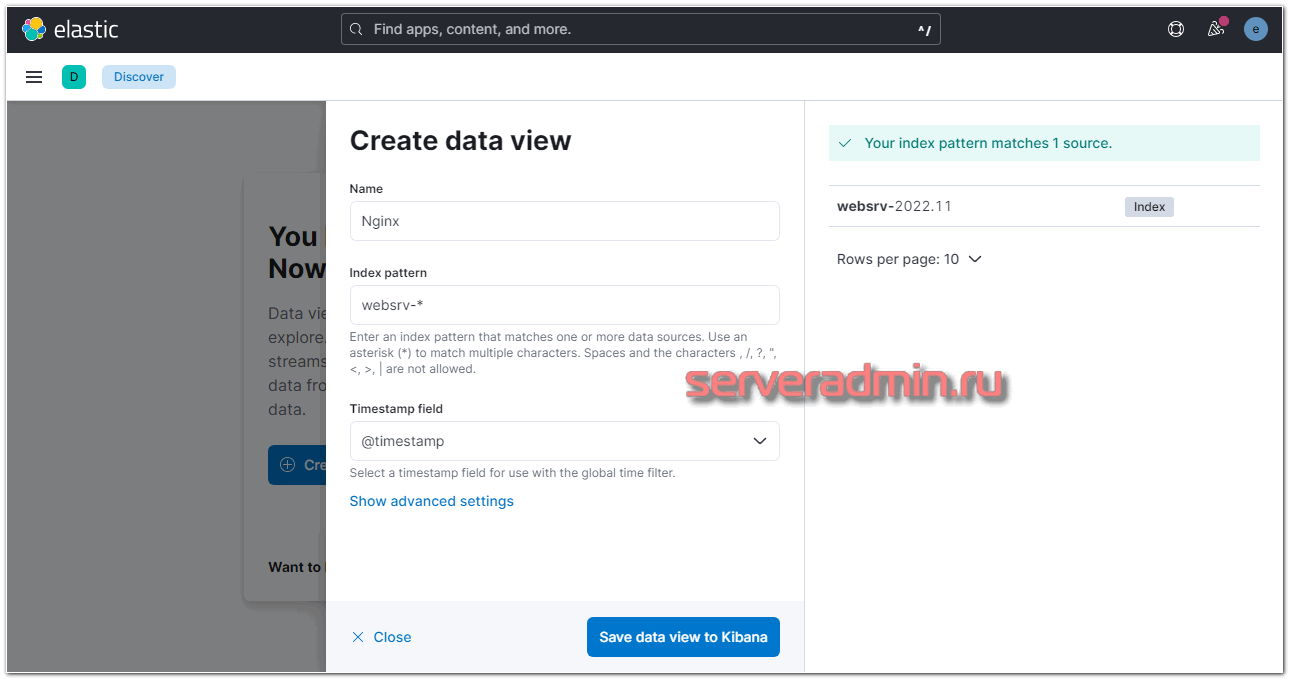
Новый индекс добавлен. Теперь при переходе в раздел Discover, он будет открываться по умолчанию со всеми данными, которые в него поступают.
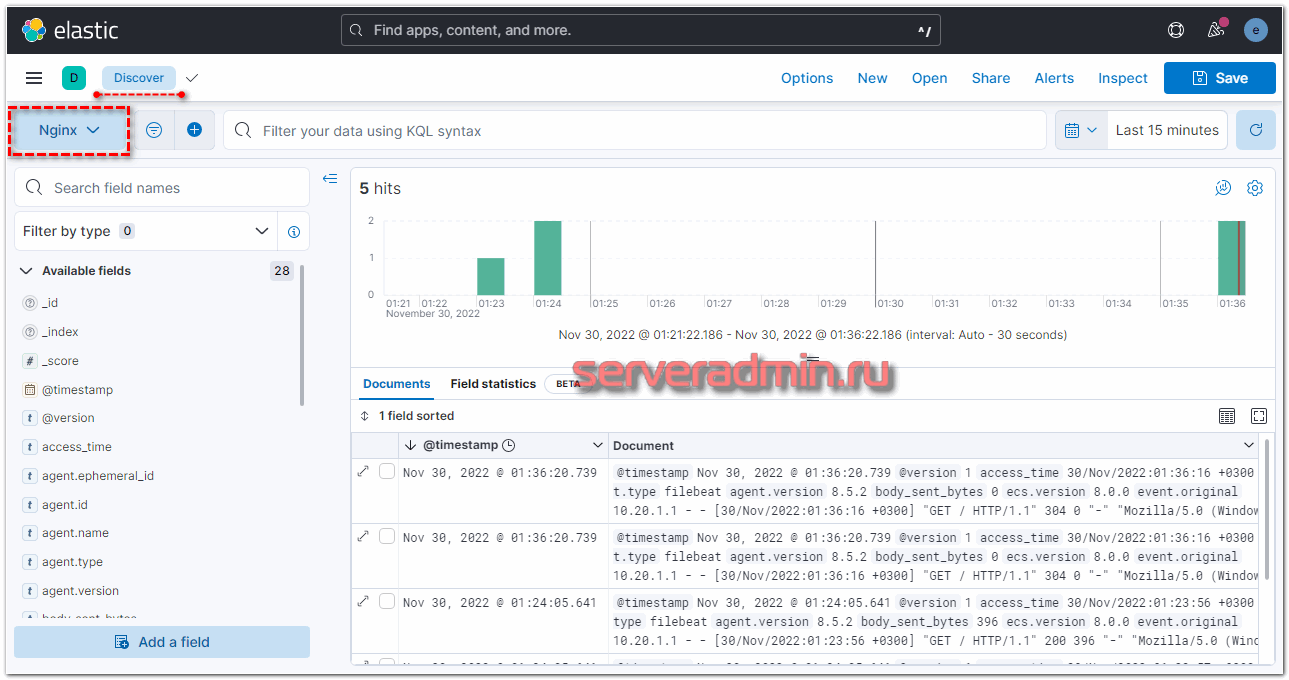
Разворачиваем какую-то запись и смотрим подробности. В том числе работу модуля geoip.
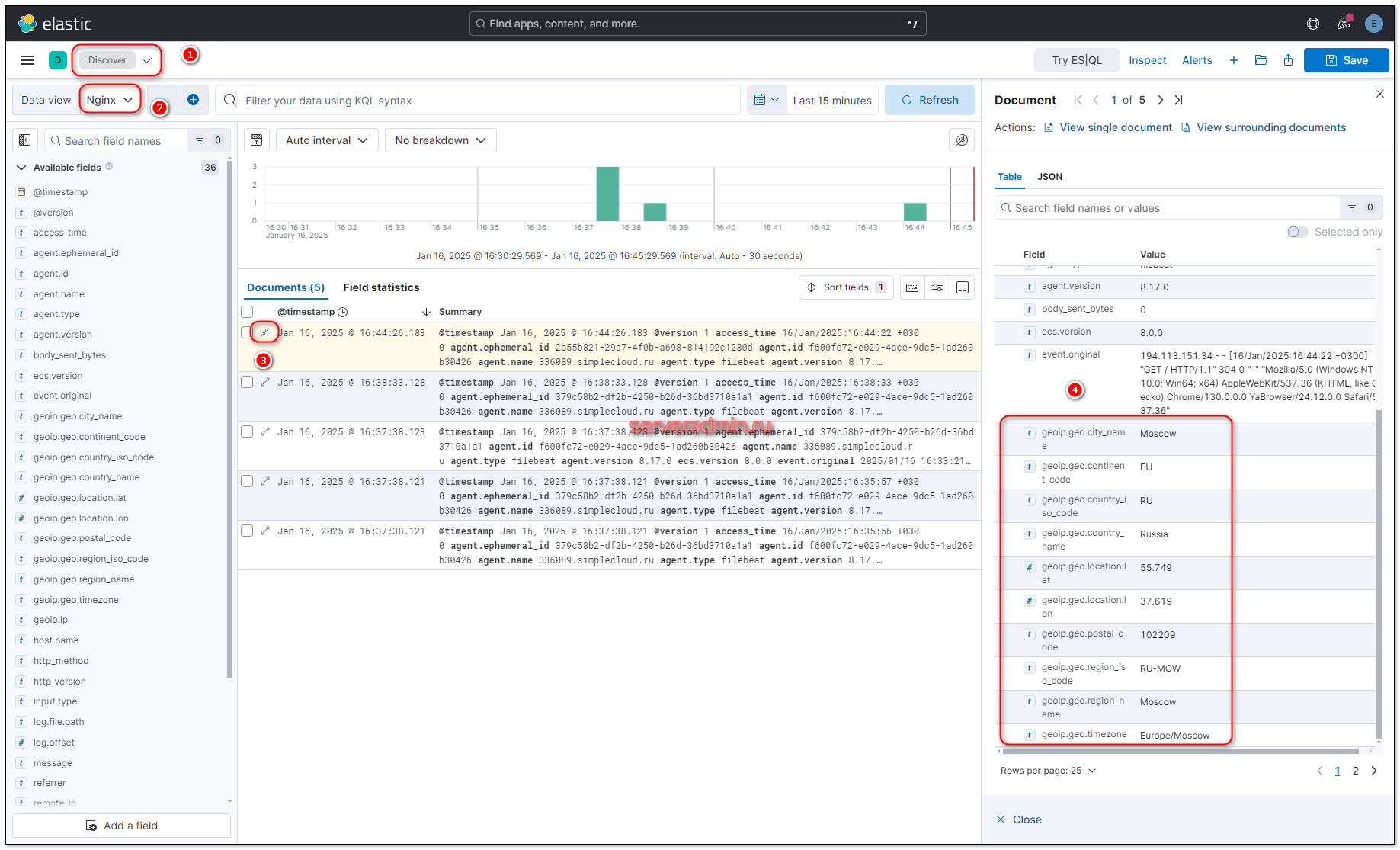
По всем перечисленным полям можно делать поиск, выборки, строить дашборды и т.д.
Получение логов с веб сервера nginx на Linux настроили. Подобным образом настраивается сбор и анализ любых логов. Можно либо самим писать фильтры для парсинга с помощью grok, либо брать готовые. Вот несколько моих примеров по этой теме:
- Мониторинг производительности бэкенда с помощью ELK Stack
- Сбор и анализ логов samba в ELK Stack
- Дашборд для логов nginx
Теперь сделаем то же самое для журналов windows.
Установка и настройка Winlogbeat
Для настройки централизованного сервера сбора логов с Windows серверов, установим сборщика системных логов winlogbeat. Для этого скачаем его и установим в качестве службы. Идем на страницу загрузок и скачиваем msi версию под вашу архитектуру - 32 или 64 бита. Запускаем инсталлятор и в конце выбираем открытие директории по умолчанию.
 Создаем и правим конфигурационный файл winlogbeat.yml. Я его привел к такому виду:
Создаем и правим конфигурационный файл winlogbeat.yml. Я его привел к такому виду:
winlogbeat.event_logs:
- name: Application
ignore_older: 72h
- name: Security
- name: System
tags: ["winsrv"]
output.logstash:
hosts: ["10.20.1.56:5044"]
logging.level: info
logging.to_files: true
logging.files:
path: C:/ProgramData/Elastic/Beats/winlogbeat
name: winlogbeat.log
keepfiles: 7
В принципе, по тексту все понятно. Я беру 3 системных лога Application, Security, System (для русской версии используются такие же названия) и отправляю их на сервер с logstash. Настраиваю хранение логов. Отдельно обращаю внимание на tags: ["winsrv"]. Этим тэгом я помечаю все отправляемые сообщения, чтобы потом их обработать в logstash и отправить в elasticsearch с отдельным индексом. Я не смог использовать поле type, по аналогии с filebeat, потому что в winlogbeat в поле type жестко прописано wineventlog и изменить его нельзя. Если у вас данные со всех серверов будут идти в один индекс, то можно tag не добавлять, а использовать указанное поле type для сортировки. Если же вы данные с разных серверов хотите помещать в разные индексы, то разделяйте их тэгами. Для того, чтобы логи виндовых журналов пошли в elasticsearch не в одну кучу вместе с nginx логами, нам надо настроить для них отдельный индекс в logstash в разделе output. Идем на сервер с logstash и правим конфиг output.conf.
output {
if [type] == "nginx_access" {
elasticsearch {
hosts => "https://localhost:9200"
index => "nginx-%{+YYYY.MM.dd}"
}
}
else if [type] == "nginx_error" {
elasticsearch {
hosts => "https://localhost:9200"
index => "nginx-%{+YYYY.MM.dd}"
}
}
else if "winsrv" in [tags] {
elasticsearch {
hosts => "https://localhost:9200"
index => "winsrv-%{+YYYY.MM.dd}"
}
}
else {
elasticsearch {
hosts => "https://localhost:9200"
index => "unknown_messages"
}
}
}
Думаю, по тексту понятен смысл. Я разделил по разным индексам логи nginx, системные логи виндовых серверов и добавил отдельный индекс unknown_messages, в который будет попадать все то, что не попало в предыдущие. Это просто задел на будущее, когда конфигурация будет более сложная, можно будет ловить сообщения, которые по какой-то причине не попали ни в одно из приведенных выше правил. Я не смог в одно правило поместить оба типа nginx_error и nginx_access, потому что не понял сходу, как это правильно записать, а по документации уже устал лазить, выискивать информацию. Так получился рабочий вариант. После этого перезапустил logstash и пошел на windows сервер, запустил службу Elastic Winlogbeat.
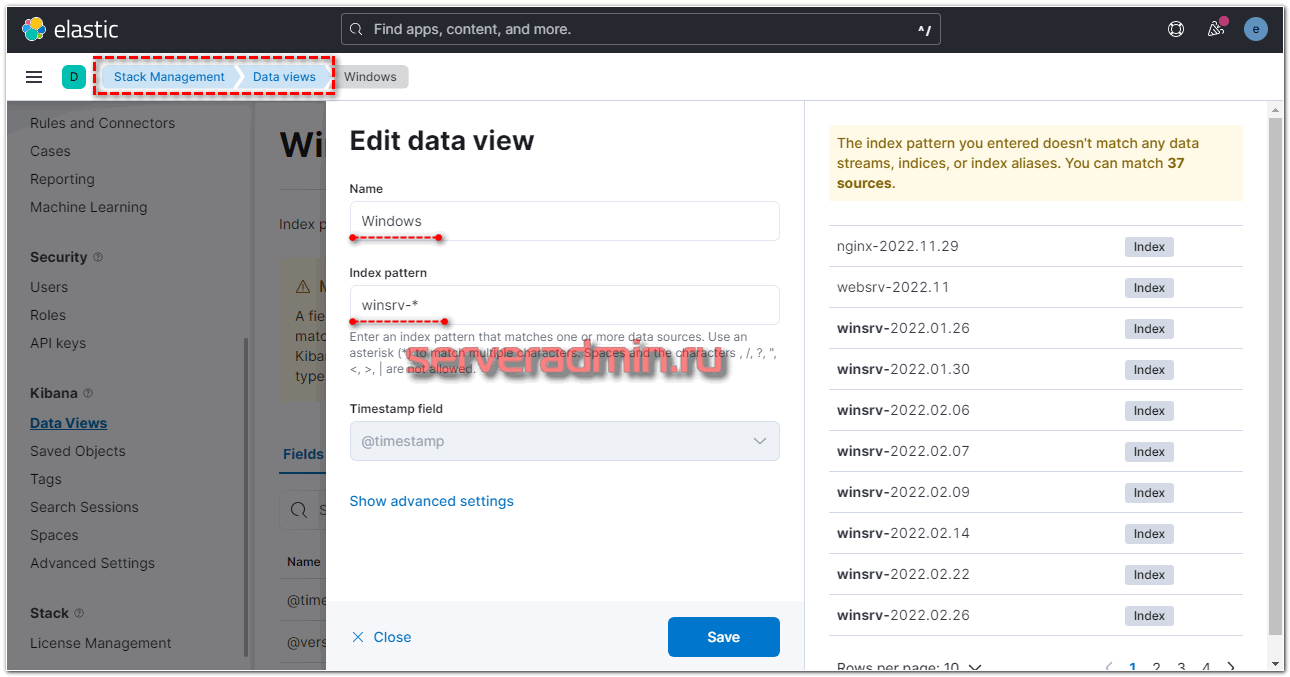
Подождал немного, пока появятся новые логи на виндовом сервере, зашел в Kibana и добавил новые data views. Напомню, что делается это в разделе Stack Management -> Data views. Добавляем новый вид по маске winsrv-*.
Можно идти в раздел Discover и просматривать логи с Windows серверов.
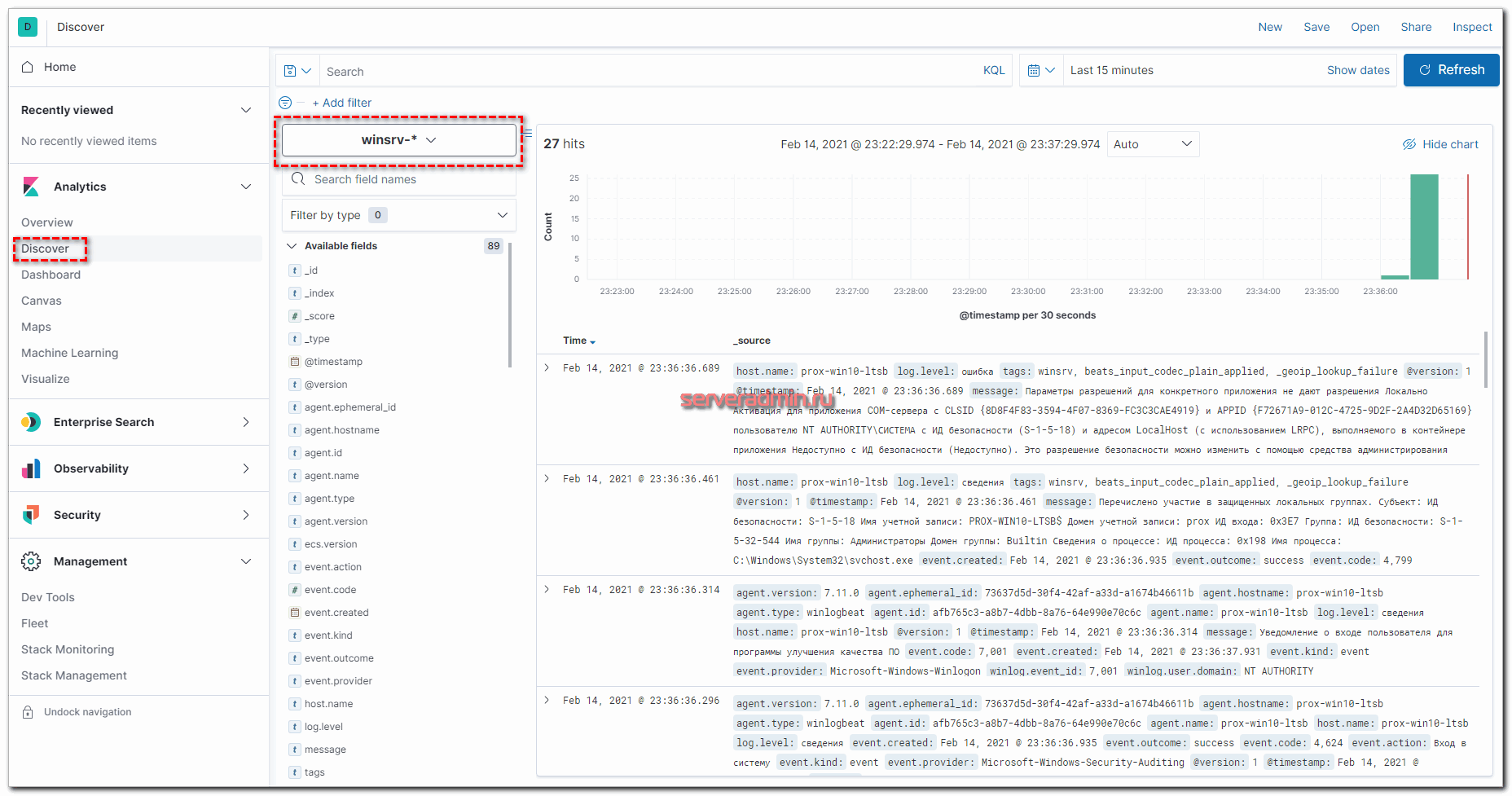
У меня без проблем всё заработало в том числе на серверах с русской версией Windows. Все логи, тексты в сообщениях на русском языке нормально обрабатываются и отображаются. Проблем не возникло нигде. На этом я закончил настройку ELK стека из Elasticsearch, Logstash, Kibana, Filebeat и Winlogbeat. Описал основной функционал по сбору логов. Дальше с ними уже можно работать по ситуации - строить графики, отчеты, собирать дашборды и т.д. В отдельном разделе ELK Stack у меня много примеров на этот счет.
Настройка безопасности и авторизация в Kibana
Мы настроили по умолчанию доступ в Kibana по паролю. Управлять пользователями и ролями можно через веб интерфейс. Делается это в разделе Stack Management -> Users. Там можно как отредактировать встроенные учетные записи, так и добавить новые.
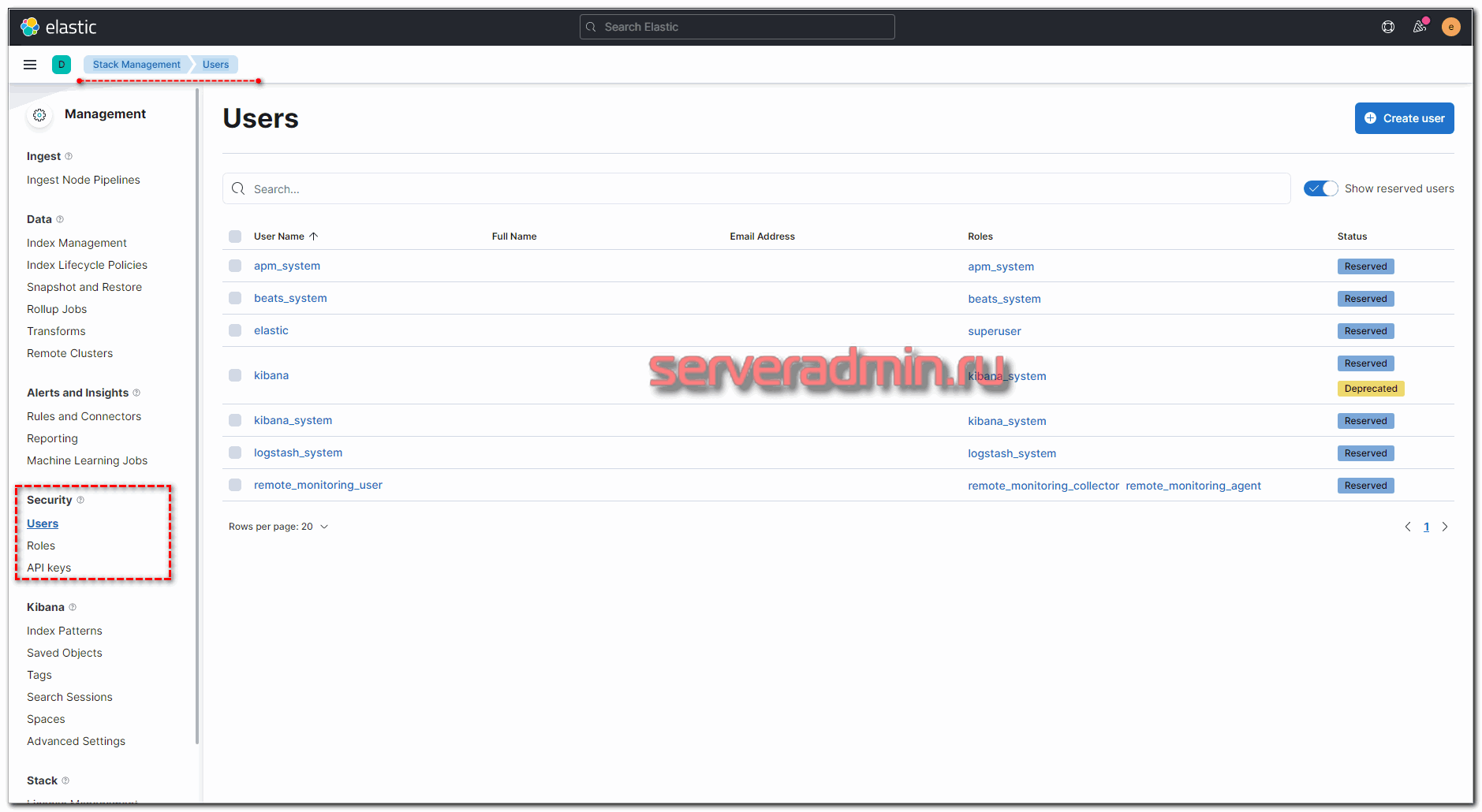
Сделаем это на примере пользователя для Logstash. Создадим отдельного юзера с правами на запись в нужные нам индексы. Для этого сначала создадим роль с соответствующими правами. Переходим в Roles и добавляем новую.
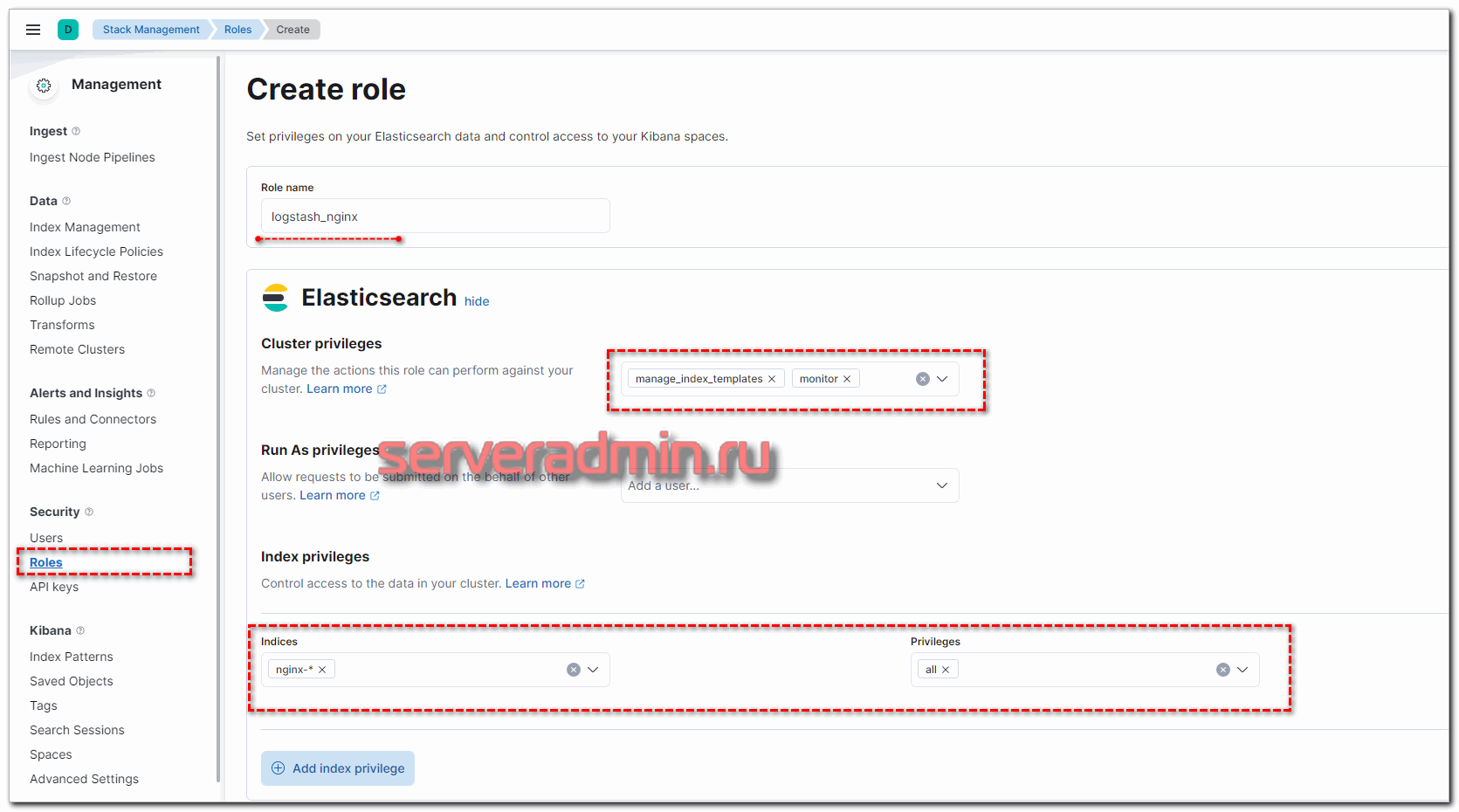
Набор индексов и права доступа к ним вы можете выбрать те, что вам нужны. Можно разделить доступ: одни могут только писать данные, другие удалять и т.д. После создания роли, добавьте пользователя и добавьте ему созданную ранее роль.
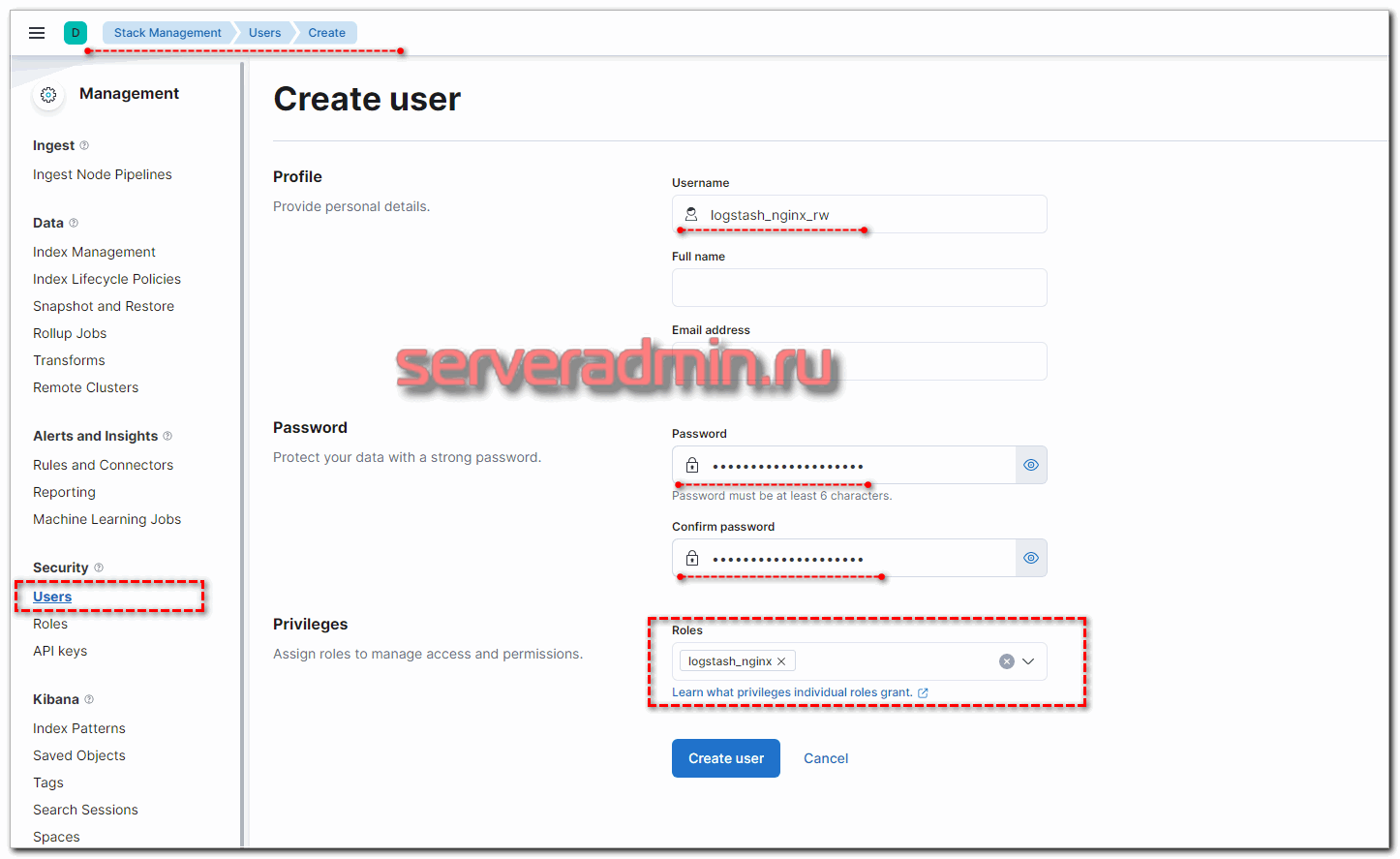
Теперь нам нужно настроить Logstash для аутентификации в кластере. Если это ещё не сделано, он не может отправлять данные. В логе у него будут ошибки, которые явно не указывают, в чем проблема, но мы это знаем и так.
[ERROR][logstash.outputs.elasticsearch][main][f8cdb7a9c640d0ed412a776071b8530fd5c0011075712a1979bee6c58b4c1d9f] Encountered a retryable error (will retry with exponential backoff) {:code=>401, :url=>"http://localhost:9200/_bulk", :content_length=>2862}
Открываем конфиг logstash, отвечающий за output и добавляем туда учетные данные для доступа в кластер. Выглядеть это будет примерно так:
output {
elasticsearch {
user => "logstash_nginx_rw"
password => "gdhsgfadsfsdfgsfdget45t"
hosts => "https://localhost:9200"
index => "nginx-%{+YYYY.MM.dd}"
cacert => "/etc/logstash/certs/http_ca.crt"
}
}
После этого данные как и прежде начнут поступать из logstash в elasticsearch, только теперь уже с аутентификацией по пользователю и паролю.
Проксирование подключений к Kibana через Nginx
Я не буду подробно рассказывать о том, что такое проксирование в Nginx. У меня есть отдельная статья на эту тему - настройка proxy_pass в nginx. Приведу просто пример конфига для передачи запросов с Nginx в Kibana. Я рекомендую использовать ssl сертификаты для доступа к Kibana. Даже если в этом нет объективной необходимости, надоедают уведомления браузеров о том, что у вас небезопасное подключение. Подробная инструкция по установке, настройке и использованию ssl в nginx так же есть у меня на сайте - настройка web сервера nginx. Все подробности настройки Nginx смотрите там. Вот примерный конфиг nginx для проксирования запросов к Kibana с ограничением доступа по паролю:
server {
listen 443;
server_name kibana.site.ru;
ssl_certificate /etc/letsencrypt/live/kibana.site.ru/fullchain.pem;
ssl_certificate_key /etc/letsencrypt/live/kibana.site.ru/privkey.pem;
location / {
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/htpasswd.kibana;
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
Создаем файл для пользователей и паролей:
# htpasswd -c /etc/nginx/htpasswd.kibana kibanauser
Если утилиты htpasswd нет в системе, то установите ее:
# dnf install httpd-tools
# apt install apache2-utils
После этого выйдет запрос на ввод пароля. С помощью приведенной выше команды мы создали файл с информацией о пользователе и пароле kibanauser для ограничения доступа к web панели Кибана. Если у вас настроена внутренняя авторизация в Kibana, то большого смысла делать примерно то же самое через Nginx нет. Но это на ваше усмотрение. Auth_basic позволяет полностью скрыть информацию о том, какой сервис находится за аутентификацией, что может быть очень актуально при прямом доступе к Kibana из интернета.
Автоматическая очистка индексов в Elasticsearch
Некоторое время назад для автоматической очистки индексов в Elasticsearch необходимо было прибегать к помощи сторонних продуктов. Наиболее популярным был Curator. Сейчас в Kibana есть встроенный инструмент для очистки данных - Index Lifecycle Policies. Его не трудно настроить самостоятельно, хотя и не могу сказать, что там всё очевидно. Есть некоторые нюансы, так что я по шагам расскажу, как это сделать. Для примера возьму всё тот же индекс nginx-*, который использовал ранее в статье.
Настроим срок жизни индексов следующим образом:
- Первые 30 дней - Hot phase. В этом режиме индексы активны, в них пишутся новые данные.
- После 30-ти дней - Cold phase. В этой фазе в индексы невозможна запись новых данных. Запросы к этим данным имеют низкий приоритет.
- Все, что старше 90 дней удаляется.
Чтобы реализовать эту схему хранения данных, идем в раздел Stack Management -> Index Lifecycle Management и добавляем новую политику. Я её назвал Nginx_logs. Выставляем параметры фаз в соответствии с заданными требованиями.
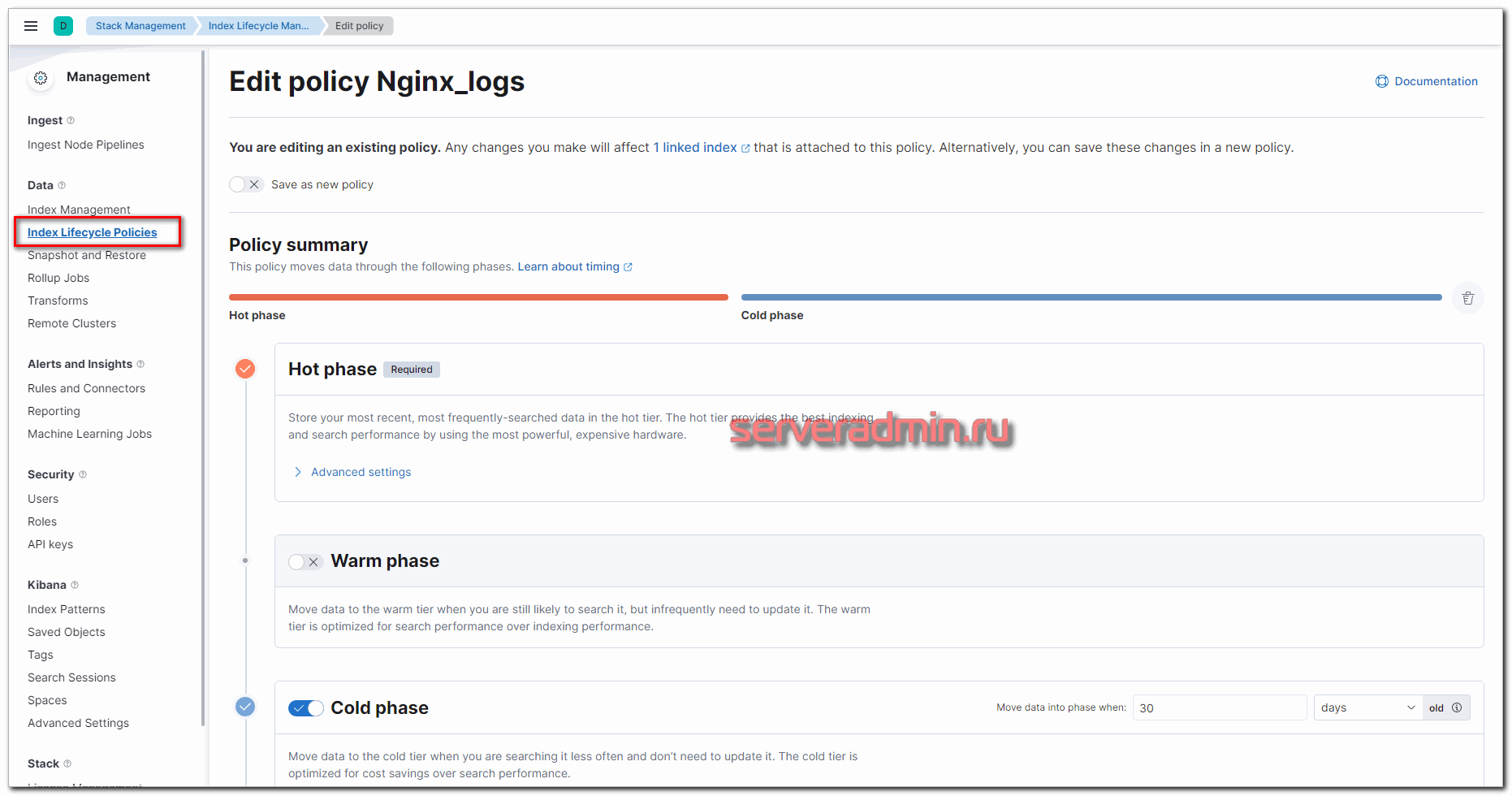
Не уместилось полное изображение настроек, но, думаю, вы там сами разберётесь, что выбрать. Ничего сложного тут нет. Далее нам нужно назначить новую политику хранения данных к индексам. Для этого переходим в Index Management -> Index Templates и добавляем новый индекс. В качестве шаблона укажите nginx-*, все остальные параметры можно оставить дефолтными.
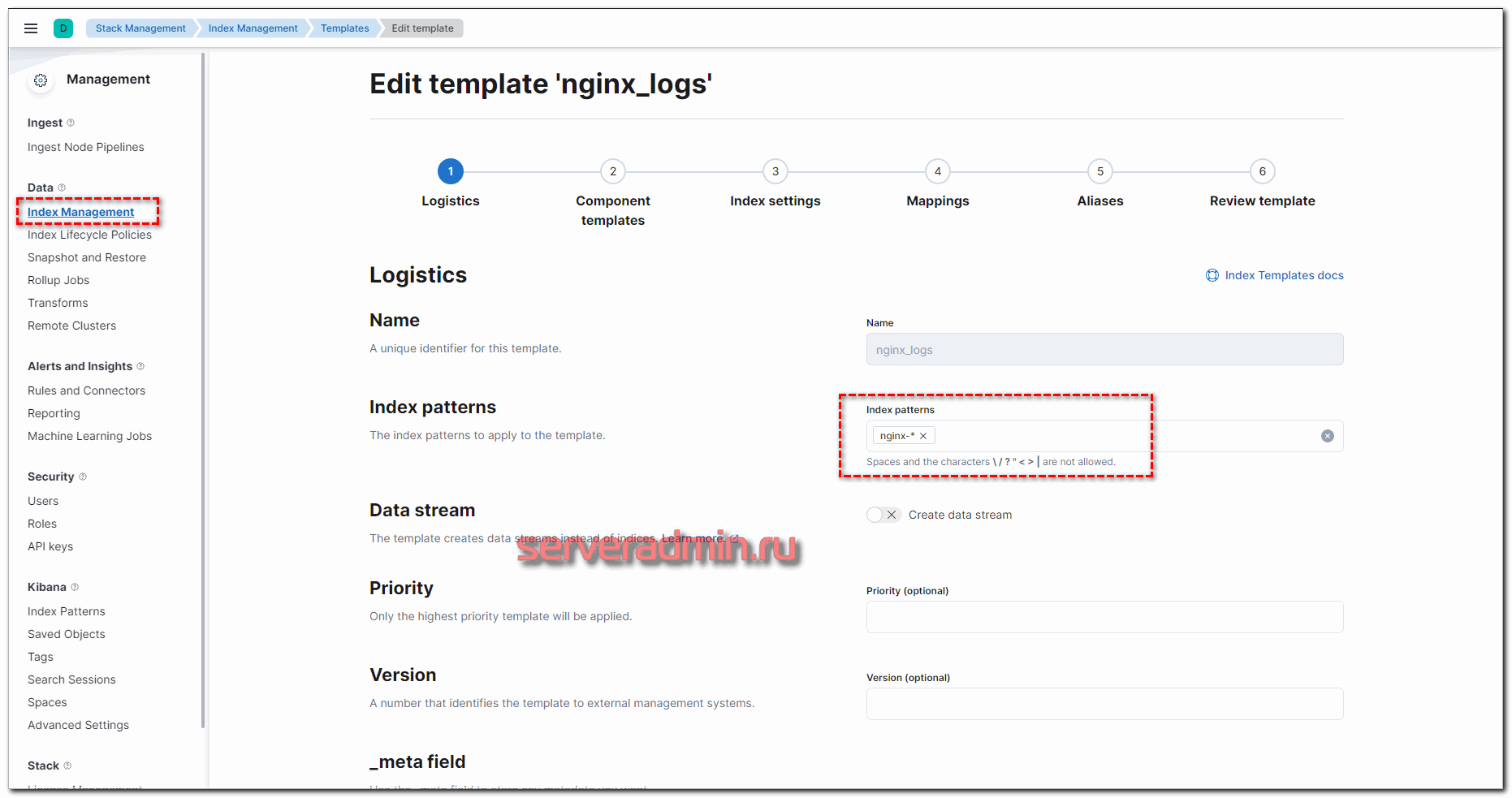
Теперь возвращаемся в Index Lifecycle Policies, напротив нашей политики нажимаем на + и выбираем только что созданный шаблон.
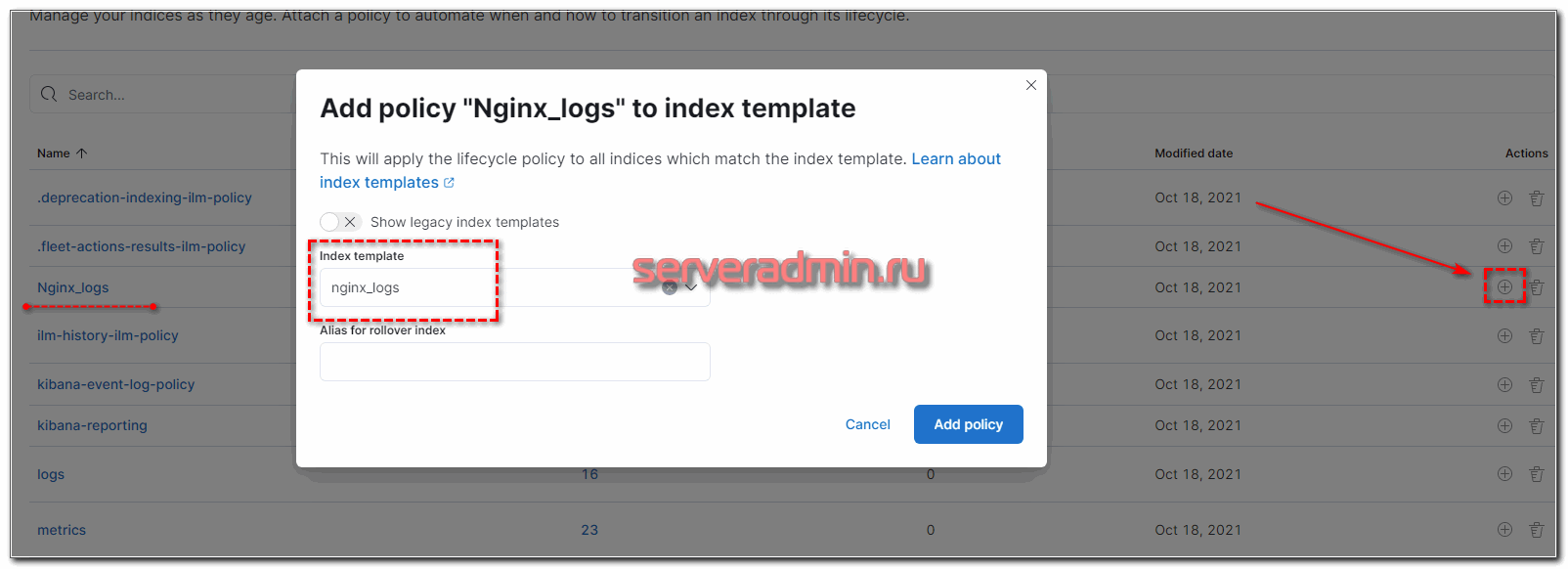
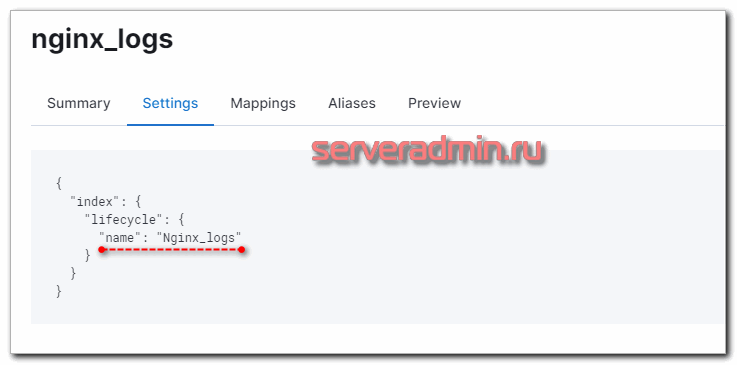
Проверяем свойства шаблона и убеждаемся в том, что Lifecycle Policies применилась.
Теперь ко всем новым индексам, созданным по этому шаблону, будет применяться политика хранения данных. Для уже существующих это нужно проделать вручную. Достаточно выбрать нужный индекс и в выпадающем списке с опциями выбрать нужное действие.
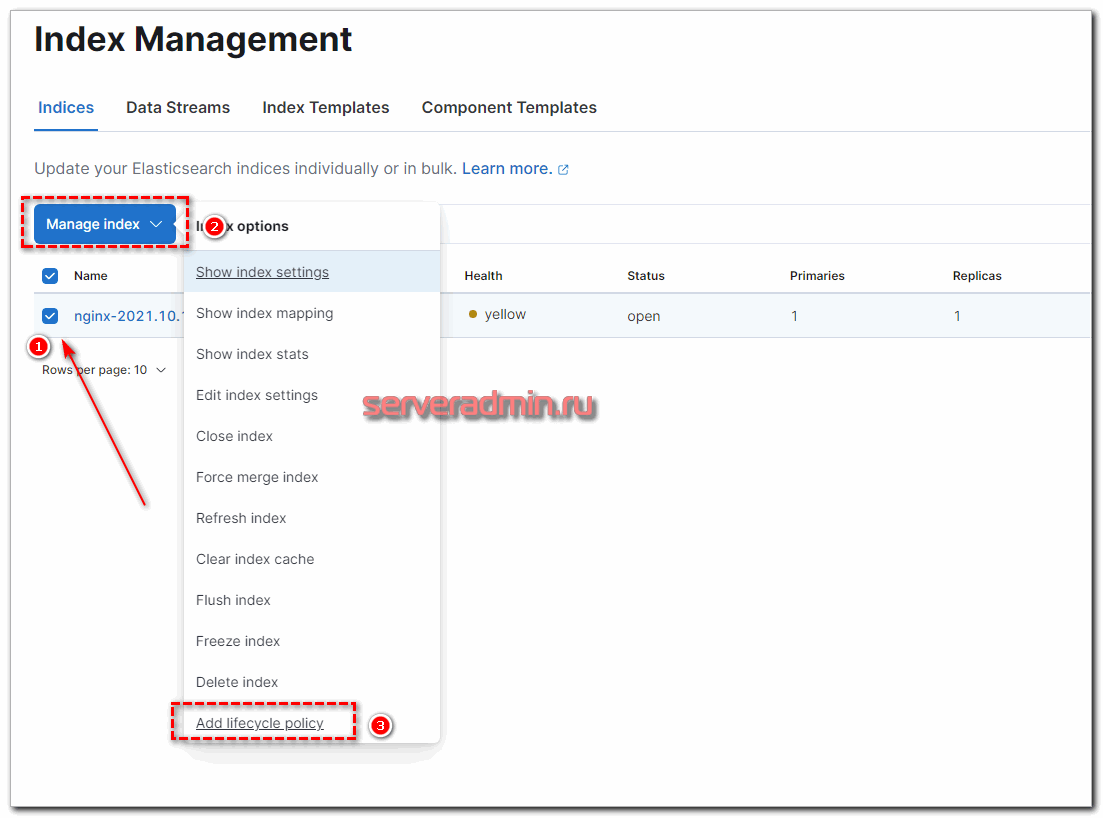
Такими несложными действиями можно настроить автоматическую очистку индексов встроенными инструментами Elasticsearch и Kibana. В некоторых случаях быстрее и удобнее воспользоваться Curator, особенно если нужно быстро реализовать много разных схем. Единый конфиг куратора выглядит более наглядным, но это уже вкусовщина и от ситуации зависит.
Часто задаваемые вопросы по теме статьи (FAQ)
Да, можно. Наиболее популярными заменами Filebeat является Fluentd и Vector. Они более функциональны и производительны. В некоторых случаях могут брать на себя часть функциональности по начально обработке данных. В итоге можно отказаться от Logstash.
Да, если вы просто собираете логи, без предварительной обработки и изменений, можно отправлять данные напрямую в Elasticsearch. На нем их так же можно обработать с помощью grok фильтра в elastic node. Вариант рабочий, но не такой функциональный, как Logstash.
Да, есть такой механизм - Index Lifecycle Policies, который требует отдельной настройки в Kibana. Также можно использовать сторонний софт. Пример такого софта - curator.
Проще всего использовать для этого Nginx в режиме proxy_pass. С его помощью можно без проблем подключить бесплатные сертификаты от Let's Encrypt. В Kibana можно подключить готовые сертификаты через набор параметров server.ssl, но отдельно придётся решать вопрос их обновления и перезапуска службы после этого события.
Начать настройку можно с 2CPU и 6Gb RAM. Но для более-менее комфортной работы желательно 8Gb RAM.
Заключение
Я постарался рассказать подробно и понятно о полной настройке ELK Stack. Информацию в основном почерпнул в официальной документации. Мне не попалось более ли менее подробных статей ни в рунете, ни в буржунете, хотя искал я основательно. Вроде бы такой популярный и эффективный инструмент, но статей больше чем просто дефолтная установка я почти не видел.
В эксплуатации подобного стэка много нюансов. Например, если отказаться от Logstash и отправлять данные с beats напрямую в Elasticsearch, то на первый взгляд все становится проще. Штатные модули beats сами парсят вывод, устанавливают готовые визуализации и дашборды в Kibana. Вам остается только зайти и любоваться красотой. Но на деле всё выходит не так красиво, как хотелось бы. Кастомизация конфигурации усложняется. Изменение полей в логах приводит к более сложным настройкам по вводу этих изменений в систему. Все настройки поступающей информации переносятся на каждый beats, изменяются в конфигах отдельных агентов. Это неудобно.
В то же время, при использовании Logstash, вы просто отправляете данные со всех beats на него и уже в одном месте всем управляете, распределяете индексы, меняете поля и т.д. Все настройки перемещаются в одно место. Это более удобный подход. Плюс, при большой нагрузке вы можете вынести Logstash на отдельную машину.
Я не рассмотрел в своей статье такие моменты как создание визуализаций и дашбордов в Kibana, так как материал уже и так получился объемный. Мне стало трудно всё это увязывать в одном месте. Смотрите остальные мои материалы по данной теме. Там есть примеры. Также я не рассмотрел такой момент. Logstash может принимать данные напрямую от syslog. Вы можете, к примеру, в Nginx настроить отправку логов в syslog, минуя файлы и beats. Это может быть более удобно, чем описанная мной схема. Особенно это актуально для сбора логов с различных сетевых устройств, на которые невозможно поставить агента, например Mikrotik. Syslog поток также можно парсить на ходу с помощью grok.
Подводя итог скажу, что с этой системой хранения логов нужно очень вдумчиво и внимательно разбираться. С наскока ее не осилить. Чтобы было удобно пользоваться, нужно много всего настроить. Я описал только немного кастомизированный сбор данных, их визуализация - отдельный разговор. Сам я постоянно использую и изучаю систему, поэтому буду рад любым советам, замечаниям, интересным ссылкам и всему, что поможет освоить тему. Все статьи раздела elk stack - https://serveradmin.ru/category/elk-stack/.
На углубленном курсе "Архитектура современных компьютерных сетей" вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315

Добрый вечер. Похоже, что время пришло актуализировать статью. =)
Рисуем конфиг output.conf, который описывает передачу данных в Elasticsearch.
output {
elasticsearch {
hosts => "https://localhost:9200"
index => "websrv-%{+YYYY.MM}"
user => "elastic"
password => "ktNBdiTxO3hKqASVvHyu"
cacert => "/etc/logstash/certs/http_ca.crt" ... вместо cacert использовать ssl_certificate_authorities
}
}
Далее в разделе установки и настройки Winlogbeat
Идем на сервер с logstash и правим конфиг output.conf.
output {
if [type] == "nginx_access" {
elasticsearch {
hosts => "https://localhost:9200"
index => "nginx-%{+YYYY.MM.dd}"
}
}
else if [type] == "nginx_error" {
elasticsearch {
hosts => "https://localhost:9200"
index => "nginx-%{+YYYY.MM.dd}"
}
}
else if "winsrv" in [tags] {
elasticsearch {
hosts => "https://localhost:9200"
index => "winsrv-%{+YYYY.MM.dd}"
}
}
else {
elasticsearch {
hosts => "https://localhost:9200"
index => "unknown_messages"
}
}
}
Получается что из конфига output.conf пропадают следующие строки:
user => "elastic"
password => "ktNBdiTxO3hKqASVvHyu"
cacert => "/etc/logstash/certs/http_ca.crt"
Для меня не очевидно почему так происходит и как после этого заработает logstash, он же не сможет подключиться к elasticsearch без этих данных?
Не очень понял комментарий. Конструкция ниже из статьи больше не работает?
output {elasticsearch {
hosts => "https://localhost:9200"
index => "websrv-%{+YYYY.MM}"
user => "elastic"
password => "ktNBdiTxO3hKqASVvHyu"
cacert => "/etc/logstash/certs/http_ca.crt"
}
}
Верно в 9+ версии (свежая установка) вместо cacert используется ssl_certificate_authorities.
Из Вашей статьи в разделе установки и настройки Winlogbeat
Вы приводите пример отредактированного output.conf и в нем отсутствуют следующие строки:
user => "elastic"
password => "ktNBdiTxO3hKqASVvHyu"
cacert => "/etc/logstash/certs/http_ca.crt"
Собственно у меня возник вопрос:
Почему так происходит и как после этого заработает logstash, он же не сможет подключиться к elasticsearch без этих данных?
ДОБРЫЙ ДЕНЬ.
Обновите плз ключ для Debian 12
Вроде всё обновлено. Я на днях без проблем всё установил по статье на Debian 12.
Добрый день. Возможно у вас такая же проблема как и у меня была. Почему-то командой из статьи не скачивался .asc файл в папку trusted.gpg.d. Зашел туда и командой wget http://elasticrepo.serveradmin.ru/elastic.asc скачал файл, после этого update прошел и началась установка.
Можно и даже лучше будет использовать зеркало Яндекса:
https://mirror.yandex.ru/mirrors/elastic/
Я не замечал, либо его раньше не было.
Доброго времени суток!
По ходу ключ для репозитория под Debian 12 просрочился
pub rsa4096 2022-11-29 [SC] [просрочен с: 2024-11-28]
$$$$$$$$
uid [ просрочен ] elastic
Подскажите а важно какую версию Elasticsearch использовать для Debian 11? Можно брать самую последнюю (8.15.3)? И какую версию вы используете?
В каком плане важно? Вы можете использовать любую версию. Обычно во время установки берут самую свежую.
Думал может быть для Debian 12 нужно такую-то версию, а для Debian 11 другую версию. Первый раз просто знакомлюсь с этим стеком). Ох и сложный стек, я решил пропустить логирование nginx. Сразу установил на Windows Winlogbeat, вроде всё настроил по вашим примерам, но ничего нет в Kibana. Ну всё равно спасибо за статью, продолжу разбираться.
Владимир, можете пожалуйста выложить ваш конфиг filter.conf logstash с фильтрами для нескольких сервисов? Делаю по вашей статье, когда фильтр один, все работает. Но как только начинаю добавлять фильтры для других сервисов, например для микротика по второй вашей статье, logstash перестает запускаться ссылаясь на синтаксические ошибки.
Заранее спасибо.
Вот полный конфиг с одного из серверов. Ничего не правил:
https://pastebin.com/2U0SUWdE
Добрый день! не судите строго, опыта у меня не много, возник вопрос:
в конфиге logstash, во входящем трафике, если нужно использовать шифрование, то нужно выпускать отдельный сертификат для этого -pem формата и прописывать пути к *.cer и *.key? если нет, то подскажите пожалуйста, как должен выглядеть конфиг на вх трафик. Спасибо.
Если честно, не знаю. Не настраивал в logstash шифрованную передачу. Думаю, достаточно в конфигурации указать сертификат и ключ. В документации надо посмотреть, как это сделать. Не думаю, что там есть какие-то сложности.
Будем искать, спасибо)))
А чего там искать, вот оно: https://www.elastic.co/guide/en/logstash/8.13/plugins-inputs-elasticsearch.html Смотрим параметры с ssl. Вот пример конфига https://discuss.elastic.co/t/logstash-input-tcp-with-tls-and-handshake/70126
Добрый день,
ELK настроил два года назад для сбора логов с synology, работал проблем не было.
Захожу вчера там логи за 4 дня уже не пишутся.
Вылезает ошибка
190 of 490 shards failed
The data you are seeing might be incomplete or wrong.
no_shard_available_action_exception at shard 0index synology-2023.05.02
Подскажите пожалуйста как исправить?
В логах logstash нашел
[2024-04-03T15:44:21,323][INFO ][logstash.outputs.elasticsearch][main][ac6f3ec32f5738ab7bb4303613a937b9e788acf95f4cfeb11e592b9fa2935845] Failed to perform request {:message=>"Connect to localhost:9200 [localhost/127.0.0.1] failed: Connection refused (Connection refused)", :exception=>Manticore::SocketException, :cause=>org.apache.http.conn.HttpHostConnectException: Connect to localhost:9200 [localhost/127.0.0.1] failed: Connection refused (Connection refused)}
[2024-04-03T15:44:21,332][WARN ][logstash.outputs.elasticsearch][main][ac6f3ec32f5738ab7bb4303613a937b9e788acf95f4cfeb11e592b9fa2935845] Marking url as dead. Last error: [LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError] Elasticsearch Unreachable: [http://localhost:9200/_bulk][Manticore::SocketException] Connect to localhost:9200 [localhost/127.0.0.1] failed: Connection refused (Connection refused) {:url=>http://logstash_rw:xxxxxx@localhost:9200/, :error_message=>"Elasticsearch Unreachable: [http://localhost:9200/_bulk][Manticore::SocketException] Connect to localhost:9200 [localhost/127.0.0.1] failed: Connection refused (Connection refused)", :error_class=>"LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError"}
[2024-04-03T15:44:21,335][ERROR][logstash.outputs.elasticsearch][main][ac6f3ec32f5738ab7bb4303613a937b9e788acf95f4cfeb11e592b9fa2935845] Attempted to send a bulk request but Elasticsearch appears to be unreachable or down {:message=>"Elasticsearch Unreachable: [http://localhost:9200/_bulk][Manticore::SocketException] Connect to localhost:9200 [localhost/127.0.0.1] failed: Connection refused (Connection refused)", :exception=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError, :will_retry_in_seconds=>2}
[2024-04-03T15:44:22,936][WARN ][logstash.outputs.elasticsearch][main] Attempted to resurrect connection to dead ES instance, but got an error {:url=>"http://logstash_rw:xxxxxx@localhost:9200/", :exception=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::BadResponseCodeError, :message=>"Got response code '401' contacting Elasticsearch at URL 'http://localhost:9200/'"}
[2024-04-03T15:44:23,349][ERROR][logstash.outputs.elasticsearch][main][ac6f3ec32f5738ab7bb4303613a937b9e788acf95f4cfeb11e592b9fa2935845] Attempted to send a bulk request but there are no living connections in the pool (perhaps Elasticsearch is unreachable or down?) {:message=>"No Available connections", :exception=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::NoConnectionAvailableError, :will_retry_in_seconds=>4}
[2024-04-03T15:44:27,353][ERROR][logstash.outputs.elasticsearch][main][ac6f3ec32f5738ab7bb4303613a937b9e788acf95f4cfeb11e592b9fa2935845] Attempted to send a bulk request but there are no living connections in the pool (perhaps Elasticsearch is unreachable or down?) {:message=>"No Available connections", :exception=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::NoConnectionAvailableError, :will_retry_in_seconds=>8}
[2024-04-03T15:44:28,095][WARN ][logstash.outputs.elasticsearch][main] Restored connection to ES instance {:url=>"http://logstash_rw:xxxxxx@localhost:9200/"}
Менял пароль пользователя не помогло.
Гуглить ошибку и пробовать предложенные решения. Я бы начал с того, что перезапустил elasticsearch. Потом удалил индекс, на который ругается ошибка в логе, если этот индекс уже не нужен. Возможно на сервере в какой-то момент место закончилось. В общем, тут надо разбираться и пробовать разные решения.
Zerox, подскажите.
Нужно зайти в Index Management и удалить там ?
Вот тут рассказано, как это делать:
https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-delete-index.html
Может кому то пригодится.
Удалил индексы за 2022 год в Index Management и все само собой заработало.
80гб было свободно из 100гб на hdd.
Добрый день. Не подскажете, почему в списке индексов не появляется из output.conf?
присутствует только metrics-endpoint.metadata_current_default
Где-то ошибка, вероятно. Что я ещё могу сказать заочно? Смотрите логи при отправке и на приёме. Судя по всему данные не идут, раз индекс не создаётся. Он в момент поступления первых данных будет создан.
почему то середина неверно вставилась из-за EOF, переписал
из-за блокировки ELK ip адресов из России kibana при попытке посмотреть доступные интеграции начинает зависать, для решения этой проблемы и возможности использовать интеграции elk необходимо развернуть сервис Elastic Package Registry затем собрать из исходников пакеты интеграций и поместить их в локальные хранилище.
все сборки я проводил на debian 12 под root
сначала соберем Elastic Package Registry и сделаем unit
https://github.com/elastic/package-registry
соберем упаковщик пакетов интеграций ELK
https://github.com/elastic/elastic-package
c помощью упаковшика соберем пакеты интеграций и поместим в локальное хранилище
https://github.com/elastic/integrations
Нам понадобится версия go 1.21.4 или выше, у меня установлена 1.19 обновляем ее
apt update && apt upgrade -y
go version #если не стала нужной версии удаляем
apt remove golang -y && apt autoremove -y
cd ~
качаем go https://go.dev/doc/install и установим
wget https://go.dev/dl/go1.21.5.linux-amd64.tar.gz
rm -rf /usr/local/go && tar -C /usr/local -xzf go1.21.5.linux-amd64.tar.gz
rm go1.21.5.linux-amd64.tar.gz
echo export PATH=$PATH:/usr/local/go/bin >> /root/.bashrc && source /root/.bashrc
go version
установим зависимости
apt update && apt install -y media-types zip rsync curl
качаем репозиторий
git clone https://github.com/elastic/package-registry
собираем
cd /root/package-registry/
go build .
создаем каталога для конфига и локального хранилища
mkdir /etc/package-registry
mkdir /opt/local-storage
копируем bin , конфиг , один тестовый пакет без него не запустится package-registry
cp /root/package-registry/package-registry /usr/bin/package-registry
cp "/root/package-registry/testdata/local-storage/nodirentries-1.0.0.zip" "/opt/local-storage/nodirentries-1.0.0.zip"
nano /etc/package-registry/config.yml
package_paths:
- /opt/local-storage/
создаем Unit
nano /etc/systemd/system/package-registry.service
[Unit]
Description=Elastic package-registry.
[Service]
StartLimitInterval=5
StartLimitBurst=10
ExecStart=/usr/bin/package-registry --config /etc/package-registry/config.yml
Restart=always
KillMode=process
RestartSec=120
[Install]
WantedBy=multi-user.target
включаем сервис
systemctl enable package-registry
systemctl start package-registry
удаляем за собой
rm -R "/root/package-registry/"
добавляем в конфиг кибаны наше зеркало
echo xpack.fleet.registryUrl: http://127.0.0.1:8080 >> /etc/kibana/kibana.yml
systemctl restart kibana
собираем упаковщик
cd ~
go install github.com/elastic/elastic-package@latest
cp "/root/go/bin/elastic-package" /usr/bin/elastic-package
убираем за собой
rm -R "/root/go/"
нам потребуется в будущем одна команда
elastic-package build
также возможно напрямую установить пакет в кибана но поскольку мы собрали свое зеркало то будем просто копировать пакеты в local
elastic-package install
собираем пакет интеграции, я заметил что readme на оф. сайте отличается от github но можно ориентироваться по версии и названию пакета
cd ~
git clone https://github.com/elastic/integrations
cd /root/integrations/packages/fortinet_fortigate/
elastic-package build
собранный пакет появляется в /root/integrations/build/packages/
cp "/root/integrations/build/packages/fortinet_fortigate-1.23.0.zip" /opt/local-storage/fortinet_fortigate-1.23.0.zip
systemctl restart package-registry
проверяем
для того чтобы навсегда решить проблему пишем скрипт который будет скачивать репозиторий собирать все пакеты и обновлять локальное хранилище
создадим скрипт и сделаем его исполняемым, кроп будет его запускать раз в месяц
nano /etc/cron.monthly/update_epr.sh
#!/bin/bash
cd /tmp/
git clone https://github.com/elastic/integrations
for i in `find /tmp/integrations/packages/ -maxdepth 1 -type d`
do
cd $i
elastic-package build
done
cp /tmp/integrations/build/packages/*.zip /opt/local-storage/
systemctl restart package-registry
rm -R /tmp/integrations/
chmod u+x /etc/cron.monthly/update_epr.sh
Спасибо за информацию. Нужно будет разбираться с этим вопросом.
Спасибо большое за справку по решению проблемы с репозиторием пакетов!
Добавлю после пункта по сборке и появлению пакета в папке в формате zip, чтобы его установить в kibana, которая установлена по статье, необходимо сделать следующие настройки:
# export ELASTIC_PACKAGE_KIBANA_HOST="http://192.168.1.1:5601" реальный
# export ELASTIC_PACKAGE_ELASTICSEARCH_USERNAME="elastic"
# export ELASTIC_PACKAGE_ELASTICSEARCH_PASSWORD=""
# export ELASTIC_PACKAGE_CA_CERT="" если нет https
Далее установки пакетов выполняются командой # elastic-package install --zip .zip -v
Если делать по справке, то после перемещения собранного пакета в zip и перезагрузки службы package-registry ничего не происходит и пакет не появляется в установленных интеграциях.
Спасибо за инструкцию, все понятно подробно хоть и приходилось совмещать с другими инструкциями что бы добиться работоспособности всего этого.
Единственный из ключевых моментов, будет скорее всего что пункт по настройки "Установка Filebeat для отправки логов в Logstash" стал не потянет от слова совсем. Тут конечно две причины либо я туплю, либо очень много изменилось с написание вашей инструкций. Один из пунктов "Нажимайте Create data view." это я нашел хоть он и не предлагал, а что то встроенное подтянул но при добавление выдает ошибку Типа "Данный не найдены, введите корректные данные" вот до этого момента все шло более менее гладко.
Владимир, добрый день!
Такой вопрос: у MaxMind есть также база с ASN. Можно её как-то прикрутить в выгружаемым к Кибану данным?
Спасибо.
Наверное можно, но я этим не занимался.
Просто добавил:
geoip {
database => "/usr/share/GeoIP/GeoLite2-ASN.mmdb"
default_database_type => "ASN"
source => "remote_ip"
target => "geoip"
add_tag => [ "nginx-geoip-asn" ]
}
Что-то я протупил. Думал по умолчанию какая-то другая база используется. Эта база ставится вместе с logstash и им же используется. Я в статье об этом рассказываю. Забыл просто, что эта база как раз от MaxMind.
Спасибо ещё раз! Все работает и уже очень помогает!
Не помешало бы расширить твой репо с эластиком для debian 10
спасибо, всех благ
А зачем? Уже 12-я версия вышла. К тому же в пакетах elastic нет привязки к версии. Можно скачать deb пакеты и установить в любую версию Debian.
Базу можно не качать, Logstash сам скачает базу, если будет использована в конфиге. Elastic тоже сам качает ежедневно базу, загрузку можно в настройках отключить - качает со своей шары в гугле
geoip {
source => "[source][ip]"
default_database_type => 'ASN'
}
Забыл дополнить. База обновляется исправно ежедневно, проверка базы происходит в тоже время (часы минуты), в которое был ранее запущен Logstash - вся информация есть в логах
Спасибо за информацию. Раньше такого не было. Я по привычке с 6-й версии плюс-минус одинаково настраиваю.
Еще нашел интересную информацию по индексам в Elastic
У меня ELK работает на одной ноде, кластер не собирал
За почти год собрались разные индексы и у них был желтый статус
Для некоторых индексов настраивал время жизни - Hot > Cold > Delete
Но они останавливались на фазе Cold, откладывал все момент поиска информации пока не накопятся разные данные
По итогу выяснил, что если ELK работает на одной ноде, то следует выставлять параметр number_of_replicas = 0
Из за того, что по умолчанию стоит 1 - индекс не может нормально собраться, появляются не распределенные шарды (shards) и статус индекса горит желтым
Нашел статью, как раз описывающую этот момент и пошаговую инструкцию как это исправить
https://community.ibm.com/community/user/ibmz-and-linuxone/blogs/james-porell1/2023/09/22/elasticsearch-index-lifecycle-management-policy-an
После отключения реплики, статус индексов перешел в зеленый и все фазы самостоятельно завершились.
Заметил, что данные с объемных индексов стали быстрее выгружаться
Добрый день!
Большое спасибо за мануал, всё заработало вроде, но: в эластик отправляется раз в несколько минут только первая запись лога (сам лог на данный момент примерно 28Мб), и всё на этом. Что может быть?
Лог, файлбит и логстэш находятся на удалённой машине от эластика и кибаны, вроде все друг друга видят.
Вроде нашёл. Был включен модуль апача в файлбит, из-за него вылетал, т.к. он не был сконфигурирован. Всем спасибо! :)
Что не не совсем понятно почему не срабатывает добавление при Create Data Vew:
Index pattern
Name must match one or more data streams, indices, or index aliases.
"
Если у вас нет доступа к репозиторию, то можете воспользоваться моим. Я создал копию репозитория elastic для Debian 11. Под все остальные системы можно через браузер скачать нужный пакет и установить вручную.
"
Ого! Прям отдельный респект за такое!!!
К сожалению, я не слежу за актуальностью этого репозитория, чтобы не было расхождений в версиях репозитория и статьёй. Это довольно хлопотное занятие. Так что сейчас там те версии, что точно заработают по этой статье. А дальше обновляться вам нужно уже своими силами, если нужна последняя версия.
Вот, кстати, и идея для новой статьи. Опишите как вы это сделали, думаю многим это будет интересно.
Я писал об этом в telegram канале:
https://t.me/srv_admin/2277
Интересен ваш опыт по сборку алертов. Предположим, что хочется иметь выгрузку алертов в красивом виде, с возможностью искать по ним через UI. Если выгружать в Elastic - есть на `github` утилиты типа alertmanager2gelf, alertmanager2es. Но они давно не поддерживаются и не до конца ясно, какую альтернативу себе нашли люди. Поделитесь, пожалуйста, опытом.
Ещё раз: задача - поиск по алертам, как в ES по логам.
лювлю на чистой установке ошибку в web кибаны.
Version: 8.7.1
Build: 61224
Error: Definition of plugin "banners" not found and may have failed to load.
at http://192.168.1.131:5601/61224/bundles/core/core.entry.js:1:342508
at plugin_PluginWrapper.createPluginInstance (http://192.168.1.131:5601/61224/bundles/core/core.entry.js:1:342752)
at plugin_PluginWrapper.setup (http://192.168.1.131:5601/61224/bundles/core/core.entry.js:1:341952)
at plugins_service_PluginsService.setup (http://192.168.1.131:5601/61224/bundles/core/core.entry.js:1:344987)
at core_system_CoreSystem.setup (http://192.168.1.131:5601/61224/bundles/core/core.entry.js:1:350676)
at async Module.Gi (http://192.168.1.131:5601/61224/bundles/core/core.entry.js:1:356895)
AlmaLinux release 9.2, установка через пакетный менеджер. версии кибаны и es одинаковые. В конфиге указано минимум, как и в статье.
Кто-нибудь сталкивался? Решение нагуглить не смог.
По ошибке not found and may have failed to load можно предположить, что установщик пытается что-то загрузить, но из-за блокировки с адресов РФ это не получается.
Я из Казахстана. Доступ к репозиториям имеется. Пробовал удалять все и ставить версии, что указаны в статье. Скачал rpm пакеты с официального сайта. Установил всё как в статье, поменял конфиг и первый же вход в веб морду кибаны - ошибка.
ладно, буду смотреть. Найду проблему отпишусь.
Веб морда стала нормально запускаться после удаления директории со всем содержимым /usr/share/kibana/x-pack/plugins/banners
Объясните нюанс.
Зачем делать в filebeate использовать:
fields:
type: nginx_access
fields_under_root: true
если можно делить верхним type: log
То есть я могу записать в filebeate так :
filebeat.inputs:
- type: nginx_access
enabled: true
paths:
- /var/log/nginx/*-access.log
scan_frequency: 5s
- type: nginx_error
enabled: true
paths:
- /var/log/nginx/*-error.log
Вроде чем меньше строк, тем проще читать. Или в Вашем варианте есть какой-то нюанс, который я не улавливаю
Ужасно кастомный гайд. Не теряйте время, не работает. Зачем пилить костыли когда есть https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-module-nginx.html ?
Я же не заставляю читать. Изучи продукт, напиши статью и обновляй её регулярно вместе с обновлением продукта, которое происходит каждые пол года. Пришли ссылку, я поучусь у тебя и своим подписчикам расскажу про классную статью.
Если у тебя что-то не получается, это не значит, что статья плохая. Я получал десятки отзывов о том, как всё получилось. А в статистике сайта я вижу обратные ссылки на эту статью из внутренней документации очень многих компаний, в том числе крупных.
Раза три пробовал поставить по данному ману, не рабочий вариант для debian 11, не хочите kibana дружить с elastic
Kibana cannot connect to the Elastic Package Registry, which provides Elastic Agent integrations
Ensure the proxy server(opens in a new tab or window) or your own registry(opens in a new tab or window) is configured correctly, or try again later.
За репозиторий спасибо.
Что за высер? Новичек никогда не разберется по твоей ссылке.
Zerox отличные статьи выпускает и помогает сотням - тысячам людей.
Все описал, привел конфиг и все испортил выпиливанием в стек nginx. Зачем ? Неужели нельзя вся поднять и описать из коробки ? Кто захочет разобраться, тот сам допилит так как ему удобно будет. Кнопки Create data view больше нет в разделе дискавер. Что дальше то ? Для новичков просто не статья а потерянное время. Зачем так делать ? Посмотрите сколько комментариев а как это а как то. Очень жаль что потратил время.
Ах вот оно что вот тут и у меня стопор тоже. Что данная кнопка не появляется.
Nginx тут вообще не при чём.
Добрый день
Замечательная статья! Как и многие статьи на этом сайте. Позволяет легко и быстро вкатиться в технологию. Спасибо Автору за труд!
По самой статье есть вопрос, который пока не удалось однозначно разрешить: Есть ли механизм бесплатно прикрутить LDAP авторизацию к реализованному стеку?
Сама установка по статье прошла без проблем. Отдельное спасибо за репу) Прокси Nginx также без проблем прикрутился, но появилась потребность назначать метрики по пользователям и ролям. Пользователей около 100, вручную администрировать это не хотелось бы.
Наткнулся на https://docs.readonlyrest.com/kibana Но так и не понял как это скрутить вместе. Похоже что для Кибана плагин всё равно платный(
Поэтому вопрос: есть ли рабочий способ прикрутить LDAP авторизацию в бесплатной версии стека ELK ?
Возможно есть способ прикрутить LDAP через Keycloack в бесплатной версии?
И если такого пути нет, то хотелось бы услышать Ваше мнение по стеку OpenSearch? (на сколько я понял это по сути форк ELK, так ли это?)
Также в качестве хотелки, конечно, хотелось бы увидеть статью от Автора по OpenSearch тоже :)
Заранее большое спасибо за ответы! )
И извините за глупые вопросы новичка)
С OpenSearch у меня были мысли разобраться, но по факту, он уже довольно сильно отличается от ELK. И настройка там посложнее и дольше. С учётом того, что я хорошо знаю ELK, не вижу смысла распыляться и тратить время на оба продукта. Насчёт LDAP не подскажу, не прорабатывал этот вопрос.
Спасибо за ответ)
Буду разбираться. Но похоже открытого бесплатного способа прикрутить LDAP или SSO к ELK нет (
Здравствуйте. Спасибо за подробную статью.
Уже после установки Elastic стека при обращении к странице Меню -> Management -> Fleet сталкиваюсь с проблемой - возникает ошибка следующего содержания:
Unable to initialize Fleet
[Default policy] could not be added. [system] could not be installed due to error: [RegistryResponseError: '403 Forbidden' error response from package registry at https://epr.elastic.co/search?..
Как понимаю, это снова недоступность репозиториев, откуда подгружается Fleet, из-за ограничений ip из России. Каким способом всё же можно успешно запустить Fleet? Пожалуйста, подскажите
Да, проблема с доступом к репозиторию. Как решить в данном случае, даже не знаю. Надо на сервере VPN настраивать в обход блокировок. Путь прописан явно где-то в веб интерфейсе и так просто подложить скачанный пакет или изменить адрес не получится. Хотя можно попробовать в исходники Kibana зайти и подменить url. Не знаю, насколько это реализуемо.
Было бы не плохо добавить в инструкцию пункт с добавлением портов
Можно так, например:
sudo iptables -A INPUT -p tcp --dport 9200 -j ACCEPT
sudo iptables -A INPUT -p tcp --dport 9300 -j ACCEPT
sudo iptables -A INPUT -p tcp --dport 5601 -j ACCEPT
sudo iptables-save
В конфигах для репозиториев ошибка, name должен с новой строки начинаться, иначе не установится
Спасибо большое за статью, особенно за раздел с безопасной передачей. Ставил по умолчанию ELK, он сразу включил https. Делал по вашей инструкции, нашёл несоответствие.
В файле .conf индекс создаётся в виде index => "websrv-%{+YYYY.MM}"
А в настройке привилегий для роли указываете nginx-*, и логстеш не может создать индекс, прежде чем туда что-то писать.
Либо маску "websrv-*" указывать, либо (проще) "*".
Скорее всего ошибка закралась во время очередного редактирования. Эта статья переписывалась уже раз 5. ELK постоянно обновляется. Приходится то частями, то полностью переписывать статью.
Я посоветовал (настоятельно) автору такого уважаемого сайта-портала рекламу курса OTUS про DevOps убрать от греха подальше. Я был на этом курсе и ушёл от туда почти сразу. Курс сам по себе старый и не проработанный, очень много воды. Постоянно накладки с лекциями. Домашние задания не проработаны и мучительны, в них много ошибок, на устранение которых люди тратят много часов (просто на ошибки в ДЗ, которые ОТУС не исправляет скоро уже как с год). Поддержка преподавателей никакая совсем. Если вы вдруг решили позаниматься на длинных выходных, то ответят вам в лучшем случае через 3-4 дня. Причём ответы на "отвали".
Сам курс не уникальный и идёт тупая нудная начитка лекций. Материал куда полезнее и интереснее (и уже более актуальный) есть бесплатно на ютубе. Оно много лучше и красивее подан. У преподавателей даже нет нормальных микрофонов и иногда проблема с техникой на занятиях.
В общем, это даже самое малое, что я могу написать. Курс - обман и просто высасывание бабла. Ничему не научит, бесполезная трата времени и денег.
ОТУС ещё и обманщики чистой воды. Уверяют, что можно будет вернуть ВСЕ деньги, если курс не понравится. Много подводных камней. ВСЕ деньги мне не вернули, а лишь часть. Да, сам не прочитал что-то мелкими буквами, но лить в уши неправду, чтобы просто заманить на курс - это очень низко.
Этот курс есть на торрентах, можно посмотреть и оценить. Я получал негативные отзывы абсолютно на все курсы, что так или иначе рекламировались, но не все они плохие, так как некоторые я проходил лично. Идеальных нет, где не было бы плохих отзывов. Otus на общем фоне, по моему мнению, делает нормальные курсы. Многие лекторы - публичные люди, которых можно посмотреть или послушать на ютубе или каких-то других публичных записях. Конкретно этот курс я не смотрел.
автору спасибо за работу,
статья старая и кибана уже поменялась а именно начиная отсюда
Если все сделали правильно, то данные уже потекли в elasticsearch. Мы их можем посмотреть в Kibana. Для этого открываем web интерфейс и переходим в раздел Discover. Так как там еще нет представления для нового индекса, нам предложат его добавить. Нажимайте Create data view.
Добрый день.
Споткнулся на этапе настройки Kibana.
Отредактировал конфиг по гайду (IP адрес подставил свой)
В итоге в логе Кибаны получаю ошибку:
This version of Kibana (v8.6.1) is incompatible with the following Elasticsearch nodes in your cluster: v8.5.2 @ 10.3.204.16:9200 (10.3.204.16), v8.5.2 @ 10.3.204.14:9200 (10.3.204.14)","log":{"level":"ERROR","logger":"elasticsearch-service"},"process":{"pid":10019},"trace":{"id":"66c2afff2f75fd758506ba439778afea"},"transaction":{"id":"9329a5b487b613f5"}}
Соответственно на веб интерфейсе получаю сообщение Kibana server is not ready yet.
Вопрос: Что то упустил и не донастроил или в репозитории лежит не та версия кибаны?
Проверьте, какие версии у вас установлены на сервере. По логам видно, что Elastic v8.5.2, а Kibana v8.6.1. У меня в репозитории есть обе эти версии. У вас по какой-то причине установлены разные. Они не совместимы между собой.
Добрый день! Настроил по Вашему мануалу. Отправляю логи с winlogbeat, конфиг:
winlogbeat.event_logs:
- name: Application
ignore_older: 72h
- name: Security
- name: System
tags: ["winsrv"]
output.logstash:
hosts: ["ip:5044"]
logging.level: info
logging.to_files: true
logging.files:
path: C:/ProgramData/Elastic/Beats/winlogbeat
name: winlogbeat.log
keepfiles: 7
Проверкак подключения tnc ip -p 5044 проходит ок.
Конфиг logstash output:
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "winsrv-%{+YYYY.MM}"
}
}
Данных в Index patterns нету. Что может быть?
Может быть всё, что угодно. Так трудно судить. Надо внимательно смотреть логи на обоих сторонах, проверять всю последовательность настройки. Где-то что-то упущено.
ELK 8.5.3
[ERROR][elasticsearch-service] Unable to retrieve version information from Elasticsearch nodes. unsupported certificate purpose
При настройке эластик-кибана
Чаще всего такие проблемы возникают при неправильной настройки ca.crt, из-за которого не может быть проверен сертификат при подключении. Может прав у кибаны нет к этому файлу с сертификатом, ошибка в пути или ещё что-то.
Добрый день, подскажите, пожалуйста, может сталкивался кто. Настроил ELK, чтоб через реверс прокси Nginx кибана грузилась по адресу http://mysite.com/analytics/ . На сайте настроен сертификат от Let's Encrypt. При попытке зайти на HTTPS версию получаю белую страницу.
Через просмотр кода виден код страницы elastic, но все ресурсы в 404, поэтому ничего не грузится. Пытаюсь настроить через конфиг кибаны, копирую сертификаты Let's Encrypt от домена в папку кибаны, выставляю права и разрешения, потом добавляю в конфиг:
server.ssl.enabled: true
server.ssl.certificate: /etc/kibana/certs/fullchain.pem
server.ssl.key: /etc/kibana/certs/privkey.pem
И стабильно получаю ошибку 502 Gateway. Если кто настроил, пните, пожалуйста в нужную сторону.
Вы проксируете запросы на алиас /analytics. Они в таком же виде с /analytics в url приходят ни Kibana, но сама Kibana настроена на работу без этого алиаса. В общем, если не разбираетесь в этом, то посадите Kibana на отдельный поддомен, а не /analytics/ или разберитесь с этим перенаправлением. Ошибка в нём, а не сертификате.
Привет добрый человек. Спасибо, все работает.... Вот только не могу понять... как мне добавить мониторинг iis??? Как работает интеграция через api
Я никогда не настраивал анализ логов IIS. Он вроде бы пишет логи в системный лог Windows. А для сбора логов Windows есть готовый сборщик Winlogbeat. Надо его установить и настроить.
Установил Winlogbeat и настроил.... показывает все кроме IIS )). Видел, что можно мониторить iis более подробно. А не пробовали Вы делать интеграцию через fleet ?
Я не пробовал. Так сами логи iis где находятся?
В папке по умолчанию
Для IIS есть отдельный модуль, который входит в состав Filebeat. В документации показано, как настроить:
https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-module-iis.html
Спасибо за наводку. Решил проблему с ошибкой 509. Вот только осталась одна проблема. вот такая ошибка:
{"log.level":"error","@timestamp":"2023-03-08T12:19:50.986-0800","log.origin":{"file.name":"cfgfile/reload.go","file.line":258},"message":"Error loading configuration files: 1 error: Unable to hash given config: missing field accessing '0.vpcflow' (source:'C:\\Program Files\\Filebeat\\modules.d\\gcp.yml.disabled')","service.name":"filebeat","ecs.version":"1.6.0"}
{"log.level":"info","@timestamp":"2023-03-08T12:19:50.987-0800","log.logger":"load","log.origin":{"file.name":"cfgfile/list.go","file.line":139},"message":"Stopping 68 runners ...","service.name":"filebeat","ecs.version":"1.6.0"}
Loaded Ingest pipelines
Вопрос решен. В кибане в настройках elasticsearch внес отпечаток сертификата и все заработало. Теперь агенты работают через fleet сервер. Теперь все подробно показывает. Всем спасибо
Подскажите,
Failed to fetch https://artifacts.elastic.co/packages/8.x/apt/dists/stable/InRelease 403 Forbidden [IP: 34.120.127.130 443]
Это что, закрыт доступ c российских ip
Да, используйте какой-то другой репозиторий. Например мой. В статье описано, как это сделать.
На зеркале Yandex версия Elasticsearch 8.1.1, тогда как текущая - 8.5.1
Можно вручную скачать пакет через vpn с сайта и положить на сервер. Я последнее время так делал, чтобы поставить свежую версию.
apt install openvpn -y
заходим на https://www.vpngate.net/en/
скачиваем вот скриншот https://ibb.co/nzdJxJN
проверяем ip адрес до этого dig TXT +short o-o.myaddr.l.google.com @ns1.google.com
и стартуем openvpn --config vpngate_public-vpn-64.opengw.net_tcp_443.ovpn
проверяем ip адрес после этого dig TXT +short o-o.myaddr.l.google.com @ns1.google.com
Откройте еще один терминал тк openvpn займет этот
Не редактируются сообщения
Скачиваем
wget https://www.vpngate.net/common/openvpn_download.aspx?sid=1665131364114&tcp=1&host=public-vpn-64.opengw.net&port=443&hid=15094252&/vpngate_public-vpn-64.opengw.net_tcp_443.ovpn
И стартуем
openvpn --config vpngate_public-vpn-64.opengw.net_tcp_443.ovpn
Дошел до этого и встал
root@debiandc:~# systemctl start elasticsearch.service
Job for elasticsearch.service failed because a timeout was exceeded.
See "systemctl status elasticsearch.service" and "journalctl -xe" for details.
root@debiandc:~#
root@debiandc:~# systemctl status elasticsearch.service
● elasticsearch.service - Elasticsearch
Loaded: loaded (/lib/systemd/system/elasticsearch.service; enabled; vendor preset: enabled)
Active: failed (Result: timeout) since Fri 2022-10-07 00:19:43 EDT; 53s ago
Docs: https://www.elastic.co
Process: 948 ExecStart=/usr/share/elasticsearch/bin/systemd-entrypoint -p ${PID_DIR}/elasticsearch.pid --quiet (code=exited, status=143)
Main PID: 948 (code=exited, status=143)
CPU: 27.739s
Oct 07 00:18:23 debiandc systemd[1]: Starting Elasticsearch...
Oct 07 00:19:39 debiandc systemd[1]: elasticsearch.service: start operation timed out. Terminating.
Oct 07 00:19:43 debiandc systemd[1]: elasticsearch.service: Failed with result 'timeout'.
Oct 07 00:19:43 debiandc systemd[1]: Failed to start Elasticsearch.
Oct 07 00:19:43 debiandc systemd[1]: elasticsearch.service: Consumed 27.739s CPU time.
root@debiandc:~#
Памяти 2 гб озу
Стартанул сервис после поднятия VPN вот это поворот !
Надо лог смотреть, чтобы понять, о каком именно timeout идёт речь. Может он что-то скачать собирается и не может. Но вообще 2 гига мало для elasticsearch. Надо хотя бы 4.
Была проблема в следующем
1. Неправильно записал filter.conf
2. Logstash не мог стартануть
3. Логи Logstash смотреть тут - /var/log/logstash/logstash-plain.log
От себя добавлю полезных материалов -
Grok RegExp
https://github.com/hpcugent/logstash-patterns/blob/master/files/grok-patterns
Добрый день, правильно ли я понимаю, что на принимающей стороне, где установлен Logstash, если использовать netstat -tulnp, то должны увидеть порт 5044 ?
До, logstash должен слушать указанный в конфигурации порт.
netstat -tulnp и получаю такой выход, а у Вас показывается 5044 тут?
Да, должно быть тут. Возможно у вас logstash вообще не запущен.
1. Logstash запущен, но не вычитывает конфиг input, странно я уже несколько раз пробовал накатить все одно и тоже
2. Вычитал конфиг посредством
Logstash -f ...input.conf, в таком случае запускается, но процесс остаётся на переднем фоне, т.е пишет стартинг сервер 5044 и так остаётся, так и должно быть или он должен уйти в фон (я конечно его запустил через screen, но все же хочется понять, а как он себя ведёт при вычитывании данной конфигурации напрямую)?
elk@elk:/usr/share/logstash$ sudo /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/input.conf
[sudo] password for elk:
Using bundled JDK: /usr/share/logstash/jdk
OpenJDK 64-Bit Server VM warning: Option UseConcMarkSweepGC was deprecated in version 9.0 and will likely be removed in a future release.
WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults
Could not find log4j2 configuration at path /usr/share/logstash/config/log4j2.properties. Using default config which logs errors to the console
[INFO ] 2022-08-29 21:48:44.631 [main] runner - Starting Logstash {"logstash.version"=>"7.17.1", "jruby.version"=>"jruby 9.2.20.1 (2.5.8) 2021-11-30 2a2962fbd1 OpenJDK 64-Bit Server VM 11.0.13+8 on 11.0.13+8 +indy +jit [linux-x86_64]"}
[INFO ] 2022-08-29 21:48:44.635 [main] runner - JVM bootstrap flags: [-Xms1g, -Xmx1g, -XX:+UseConcMarkSweepGC, -XX:CMSInitiatingOccupancyFraction=75, -XX:+UseCMSInitiatingOccupancyOnly, -Djava.awt.headless=true, -Dfile.encoding=UTF-8, -Djruby.compile.invokedynamic=true, -Djruby.jit.threshold=0, -Djruby.regexp.interruptible=true, -XX:+HeapDumpOnOutOfMemoryError, -Djava.security.egd=file:/dev/urandom, -Dlog4j2.isThreadContextMapInheritable=true]
[WARN ] 2022-08-29 21:48:44.902 [LogStash::Runner] multilocal - Ignoring the 'pipelines.yml' file because modules or command line options are specified
[INFO ] 2022-08-29 21:48:45.685 [Api Webserver] agent - Successfully started Logstash API endpoint {:port=>9600, :ssl_enabled=>false}
[INFO ] 2022-08-29 21:48:46.373 [Converge PipelineAction::Create] Reflections - Reflections took 46 ms to scan 1 urls, producing 119 keys and 417 values
[WARN ] 2022-08-29 21:48:46.906 [Converge PipelineAction::Create] plain - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[WARN ] 2022-08-29 21:48:46.922 [Converge PipelineAction::Create] beats - Relying on default value of `pipeline.ecs_compatibility`, which may change in a future major release of Logstash. To avoid unexpected changes when upgrading Logstash, please explicitly declare your desired ECS Compatibility mode.
[INFO ] 2022-08-29 21:48:46.993 [[main]-pipeline-manager] javapipeline - Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>8, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50, "pipeline.max_inflight"=>1000, "pipeline.sources"=>["/etc/logstash/conf.d/input.conf"], :thread=>"#"}
[INFO ] 2022-08-29 21:48:47.027 [[main]-pipeline-manager] javapipeline - Pipeline Java execution initialization time {"seconds"=>0.03}
[INFO ] 2022-08-29 21:48:47.071 [[main]-pipeline-manager] beats - Starting input listener {:address=>"0.0.0.0:5044"}
[INFO ] 2022-08-29 21:48:47.081 [[main]-pipeline-manager] javapipeline - Pipeline started {"pipeline.id"=>"main"}
[INFO ] 2022-08-29 21:48:47.185 [Agent thread] agent - Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[INFO ] 2022-08-29 21:48:47.246 [[main]<beats] Server - Starting server on port: 5044
Вот так выглядит это, если вычитать конфиг принудительно
Добрый день!
При запросе статуса elasticsearch выдает такую ошибку:
# curl 127.0.0.1:9200
{"error":{"root_cause":[{"type":"security_exception","reason":"missing authentication credentials for REST request [/]","header":{"WWW-Authenticate":["Basic realm=\"security\" charset=\"UTF-8\"","ApiKey"]}}],"type":"security_exception","reason":"missing authentication credentials for REST request [/]","header":{"WWW-Authenticate":["Basic realm=\"security\" charset=\"UTF-8\"","ApiKey"]}},"status":401}
Судя по ошибке "missing authentication credentials for REST request", требуется авторизация для выполнения запроса. По-моему, начиная с какой-то версии запросы без авторизации вообще не проходят.
Владимир, спасибо большое за статью, особенно за зеркало на yandex :)
Поставил elastic и kibana
С kibana столкнулся со сложностью при открытии kibana на доступ извне.
Вы пишите что в файл
/etc/kibana/kibana.yml
надо добавить запись : (ip поменял на свой)
server.host: "51.250.35.236"
где "51.250.35.236" - адрес VPS
systemctl restart kibana.service
Я так и сделал, подождал минуту, даю команду
netstat -tulnp | grep 5601
и вижу пустой вывод
http://51.250.35.236:5601
также ничего не показывает
пробовал
server.host: "0.0.0.0"
kibana также недоступна
несколько раз проверял запись
server.host: "51.250.35.236"
вроде бы все верно написал, но не работает
Посдкажите пожалуйста - почему kibana не отвечает на внешний запрос ?
Надо смотреть лог Кибана. Может она из-за какой-то ошибки вообще не запускается.
Помогла запись:
server.host: "0.0.0.0"
Kibana стала отвечать :)
"пробовал
server.host: "0.0.0.0"
kibana также недоступна"
А почему раньше не помогало?
>А почему раньше не помогало?
Не могу объяснить.
Пробовал server.host: с указанием IP и потом с нулем - не работал.
Пошел по второму разу - завелась.
У меня нет объяснения - делал все то же самое :)
Пост пушка. Долго возился с официальной документацией и подобными "постами" с хабра. Всегда где то маленькая недосказанность вытекала в проблему.
Накатил elastic 8.2.2 на Ubuntu LTS 22 меньше чем за час.
Спасибо.
Добрый день! Хорошая статья, но как я понимаю зеркало на яндексе содержит только deb пакеты, такого же зеркала для yum\dnf не искали?
Я не искал особо. Сам использую Debian, поэтому нет такой задачи.
Владимир, не пробовали использовать вместо Logstash, fluetnd ?
Лично я - нет. Я знаю, что fluetnd более легковесное решение, которое тоже повсеместно используется. Я просто умею настраивать Logstash, поэтому и пользуюсь им. Привык уже.
Публичный ключ репозитория перестал быть доступен (https://artifacts.elastic.co/GPG-KEY-elasticsearch). 403 ошибка. Через ВПН заграничный доступен. Видать и они стали нашу страну блочить.
DEL
P.S. Только потом увидел комментарии ниже.
Добрый день!
Спасибо за Ваш труд!
Было бы интересно почитать статью про обход ограничений репозиториев. Не планируете такого рода статью?
Я уже внёс изменения в эту статью. Просто подключите репозитории от Яндекс. Это копия официального deb репозитория.
Владимир а как яндекс зеркало на centos поставить? Что-то не нашёл там yum установочных.
Я тоже не нашёл. Судя по всему rpm репозитория нету. Не знаю, почему пожадничали и не добавили.
Да я так и понял, что редхат в пролёте, я решил вопрос подняв nordvpn на микротике и через mangle добавил ip репозитория 34.120.127.130 для конкретного моего сервера внутри сети, чтобы он трафик до репозитория через vpn отправлял, а сам не был под vpn. Всё установилось нормально.
Добрый день.
Использую Ubuntu 20.04 , Суриката ставится и запускается нормально, но при попытке скачать Эластик, начиная с импорта gpg ключа вылазит ошибка
"Не найдено данных формата GPG" - бог с ним, качаю вручную с сайте Эластик, импортирую - следом, после добавления репозитория, при скачивании через apt Эластик - вечная, ничем не лечащаяся ошибка 403 Forbidden...
Уже 10 раз переимпортировал ключ - одно и то же - даже при apt-get update репозиторий Эластик игнорируется - отображается так в логах при обновлении. Всё выполняется из под root. Сеть в порядке. В Убунуту, сразу скажу, новичок, но все первоначальные настройки сделал по руководствам системным...
Спасибо!
Если не ошибаюсь, Elastic закрыл доступ к своим репозиториям для российских IP. Где-то видел такую информацию. Возможно с этим связано. Так что либо вручную качать пакеты, либо как-то через прокси или vpn подключать. Либо просто на другой форк перейти. Есть из чего выбирать.
Эх, догадывался об этом. "Какое время - такие песни."
Спасибо.
Так и есть, забанили Россию. Начал установку, наткнулся на эти грабли, после погасил ВМ и перетащил в Хецнер, где 403я ошибка сразу исчезла и всё поставилось.
точно не уверен, но возможно это из-за того, что блочатся запросы с российских ip
Проблема в том, что видимо заблокиравоно скачивание с сайта для пользователей из России, от того и видите 403.
Скачайте deb пакет врукопашную, используя прокси или vpn
Только что сам с этим боролся
В очередной раз спасибо за статью, в конфиге nginx'a для проксирования в кибану поправьте опечатку
```server {
listen 443;
```
не хватает ssl
```
server {
listen 443 ssl;
```
Это уже не нужно в современных версиях. Если настроены сертификаты, то считается, что доступ и так будет по ssl.
Добрый день, странно, но у меня без ssl в конфиге выдавал ошибку в браузере.
Настройка безопасности и авторизации перестали приходить логи хотя везде прописал необходимые логопасы, надо ли в Winlogbeat указывать логопасы? И как проверить получает ли logstash логи от Winlogbeat. Спасибо за ваш труд!
Если Winlogbeat не может подключиться к logstash, то он напишет об этом в логе. То же самое с logstash. Если он не может подключиться к elasticsearch, об этом тоже будет инфа в логах. Если подключения проходят, то логи должны литься. В logstash вообще можно включить логирование всех входящих логов в отдельный текстовый файл. Может помочь при отладке. Главное только не забыть отключить потом.
Коллеги, я что-то запутался.
Хочу внести коррективы и попросить помощи.
И так, до включения авторизации все работает. elastic шлёт логи, все чудесно вижу в kibana (сейчас речь про сбор информации с Windows посредством winlogbeat).
Помимо того, что прописал авторизацию в конфиг logstash, также потребовалось прописать username и pass в конфиг winlogbeat, иначе авторизация, иначе согласно логу winlogbeat не проходила авторизация на 5044. Да, еще лог ругается, что теперь нужно использовать опцию monitoring вместо xpack.monitoring (но это лирика)
Теперь что касается 9200 ....
Прописывая авторизацию на проверку сервиса с логином и паролем, у меня все работает:
# curl --user usr:blabla '127.0.0.1:9200'
{
"name" : "***",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "WOc6lCZpRTOJNtwBJjGR6g",
"version" : {
"number" : "7.16.2",
"build_flavor" : "default",
"build_type" : "rpm",
"build_hash" : "2b937c44140b6559905130a8650c64dbd0879cfb",
"build_date" : "2021-12-18T19:42:46.604893745Z",
"build_snapshot" : false,
"lucene_version" : "8.10.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Если пропишу без авторизации, получу (и тут внимание) - 401ю:
# curl 127.0.0.1:9200
{"error":{"root_cause":[{"type":"security_exception","reason":"missing authentication credentials for REST request [/]","header":{"WWW-Authenticate":"Basic realm=\"security\" charset=\"UTF-8\""}}],"type":"security_exception","reason":"missing authentication credentials for REST request [/]","header":{"WWW-Authenticate":"Basic realm=\"security\" charset=\"UTF-8\""}},"status":401}
И вот эта самая 401я возвращается в лог logstahs и данные не идут:
[2022-01-10T13:53:15,120][WARN ][logstash.outputs.elasticsearch][main] Attempted to resurrect connection to dead ES instance, but got an error {:url=>"http://localhost:9200/", :exception=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::BadResponseCodeError, :message=>"Got response code '401' contacting Elasticsearch at URL 'http://localhost:9200/'"}
Прошу совета. Что делаю не так?
Запутали и меня. Авторизация на logstash c winlogbeat? А зачем, winlogbeat как отсылал ему данные так и шлет. Или у вас winlogbeat шлет еластику напрямую?
Прописывал что автор статьи указывал?
"Открываем конфиг logstash, отвечающий за output и добавляем туда учетные данные для доступа в кластер. Выглядеть это будет примерно так:
output {
elasticsearch {
user => "logstash_nginx_rw"
password => "gdhsgfadsfsdfgsfdget45t"
hosts => "localhost:9200"
index => "nginx-%{+YYYY.MM.dd}"
}
}
Попробуй еще в настройках logstash.yml прописать
elasticsearch.username: "logstash_system"
elasticsearch.password: "пароль"
Почему для авторизации logstash не использовали учетку logstash_system ?
Сейчас не помню уже деталей, но по-моему её не получится использовать. Я пробовал, так как тоже думал, что лучше встроенную использовать и не плодить сущности.
"Включил мониторинг и для этого указал адрес elastichsearch, куда filebeat передает данные мониторинга напрямую."
Т.е. и в elastichsearch, и в logstash.
Цель такого дублирования?
Logstash - это обработка логов. В мониторинге он не участвует.
Но logstash переадает результаты своей работы в elastichsearch, т.е. и то что получит от filebeat. Или нет?
Logstash обрабатывает и преобразовывает логи. Filebeat частично тоже умеет это делать, но функционал сильно меньше. Данные по мониторингу filebeat передаёт напрямую в elasticsearch, минуя logstash.
А как же тогда понимать раздел "Установка Filebeat для отправки логов в Logstash" ?
Добрый вечер.
А elastic agent не пробовали использовать? Совместно с fleet server. Я так понимаю, что на время написания статьи агентов еще не было
Я не пробовал. Текущие beats устраивают полностью.
Добрый день, как распространить winlogbeat через GPO???
Разобрался, спасибо.
Спасибо за статью.
В качестве небольшого уточнения.
У вас так написано: server.publicBaseUrl: "http://10.20.1.23:5601/"
В документации так: This setting cannot end in a slash (/). Отсюда - https://www.elastic.co/guide/en/kibana/master/settings.html
Хотя скорей всего это не на что не влияет.
Здравствуйте, после настройки безопасности данные перестают поступать в logstash. В нем ошибок нет, но есть в elasticsearch.
Authentication of [beats_system] was terminated by realm [reserved] - failed to authenticate user [beats_system]
Думаю из-за нее проблема, но куда нужно вписать данные учетные записи не нашел.
Разобрался))) Ошибка эта в логах есть, но не влияет на данные.
Здравствуйте.
А как настраивать алерты и оповещение на почту?
Как-то :) Документацию надо смотреть и разбираться. У меня нет статьи по этой теме.
Если я правильно понял, это платный функционал.
Помогает очень когда надо специфический фильтр сделать:
Grok Debugger - https://grokdebug.herokuapp.com/
Спасибо. Я тоже именно этим пользуюсь. Где-то в статьях давал ссылку на него.
>>Передаем на сервер, распаковываем и копируем в /etc/logstash файл GeoLite2-City.mmdb.
>>Теперь нам нужно в настройках модуля указать путь к файлу с базой. Делается это так:
Сорри, а где хранятся настройки этого модуля? Куда нужно писать его настройки?
Эта секция добавляется в конфиг logstash.
Приветствую.
А как сделать rконфиги без ngnix, оставить только win и микротик, у меня просто не подключается сервера windows?
https://sysadminwork.com/how-to-install-and-configure-elasticsearch-logstash-kibana-elk-stack/
Здравствуйте. Нужна помощь в настройке ELK, при настройке не пошел через 127.0.0.1. За основу взял эту статью. Когда elastic настроен через 0.0.0.0 без проблем логи собираются в Kibana|discover.
beat стоят на конечных точках, а elastic в виртуалке, тогда 127.0.0.1 работать не будет, поэтому использовал проксирование через nginx
Для elasticsearch: listen 8881, kibana:8882.
HTTP без проблем открываются, через эти порты. Powershell тоже откликается при установлении дашбордов
.\winlogbeat.exe setup -e `
-E output.logstash.enabled=false `
-E output.elasticsearch.hosts=['192.168.0.4:8881'] `
-E setup.kibana.host=192.168.0.4:8882.
Может кто сталкивался с этой проблемой?
может фаервол у меня рубит? Надо завтра глянуть настройки.
Хотя обращения через http к kibana и elasticsearh работают. Ну или просто оставить 0.0.0.0 и все подключения разруливать фаерволом. Единственно смущает, что сам elastic не рекомендует оставлять эти настройки.
Как можно проверить работу logstash->elasticsearh-> kibana чтобы выявить в чем проблема?
Все оказалось банальней. При переходе из тестовой среды в промышленную (использую две виртуалки) забыл в файле winlobeat.yml поменять ip, зато заменил порты )))
Так что все замечательно работает. Возможно сказалось то, что сервак под ухом выдает море децибел и мешает сосредоточится. Перенес его сегодня подальше и вуаля.
Полезные советы в настройке: чтобы в дашбордах Kibana не выходили ошибки надо чтобы индексы в output.conf, например
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
совпадали индексом winlobeat.yml
index: "winlogbeat-%{[agent.version]}-%{+yyyy.MM.dd}"
мне это помогло, для стандартных дашбордов в Kibana. Согласен с мнением высказанным ниже, что лучше самому настраивать дашборды под себя.
Владимир, респект за статью.
спасибо за статью. все заработало. но кибана выдает ошибку "Mapping conflict" и потом поясняет что поле @timestamp в логах винды задано в разных типах, как я понимаю - где-то датой а где-то строкой. и просит "переиндексировать" для разрешения конфликта. у вас случайно нет статьи о том как это все правильно сделать?
Статьи нет. Сам не сталкивался с такой ошибкой.
Добрый день.
Все настроил по статье, при попытке добавить time field выдает ошибку Mapping Conflict, как у человека выше, возможно что-то в пакетах обновилось?
Здравствуйте Владимир!
Поделитесь, пожалуйста, рабочим файлом Logstash input
Например: windows, cisco, mikrotik, linux
Никак не получается одновременно принимать логи с разных устройств.
Спасибо!
httpd-tools ставить не обязательно, htpasswd генерируется с помощью OpenSSL
Здравствуйте! На нашем сервере установлен Logstash.
Также запущено несколько докер-образов с приложениями, логи которых пишутся в консоль.
Можно посмотреть лог с помощью команды kubectl logs [название приложения].
Подскажите, пожалуйста, как нужно описать input для Logstash, а также filebeat.yml,
чтобы можно было получить логи этих приложений.
Я не знаю, как оптимально интегрировать приложения в kubernetes с logstash. Вариантов может быть несколько. В самих докер образах настроить вывод логов в формат syslog и указать в качестве сервера logstash, настроив на нем прием syslog логов. Если логи docker контейнеров пишутся в файлы, можно настроить через filebeat отправку содержимого этих файлов в logstash. Готовых настроек у меня нет. Надо по месту все настраивать.
Спасибо!
Добрый день! я так и не понял из всей инструкции нужно ставить Кибану Эластик и Логстэш на одну виртуальную машину или каждый компонент на разные машины? И если все три компонента на разные машины то на какой должен крутиться nginx? я так понимаю на виртуалке с Эластиком?
Где угодно можете их ставить. Это все самостоятельные продукты. Я обычно сам elk stack ставлю на одну машины, а nginx на другую.
Добрый день или я что-то не понимаю или тут логическая ошибка
1. Вы настроили filebeat на отправку логов доступа и логов ошибок
2. Logstash имеет output - nginx-%{+YYYY.MM.dd}, т.е согласно такому построению выходы, логи доступа и логи ошибок будут слиты в один индекс или как? У меня вообще логи ошибок не подтягиваются.....
Теперь такой вопрос, если скажем серверов откуда тянем логи >1, т.е по сути вот такое называние индексов не годиться, nginx-%{+YYYY.MM.dd}, надо чтобы индекс имел название сервера (хост найм или IP) как такое организовать?
Логи идут в один общий индекс. В чем тут ошибка? Если надо разделить, разделяйте. Мне кажется, удобнее в одном общем держать. Но все от конкретной ситуации зависит. Можно как угодно индексы делить. Для каждого сервера или сайта свой индекс и т.д.
Можно на каждом сервере через filebeate добавлять какую-то свою метку. Потом в logstash в зависимости от этой метки, отправлять в тот или иной индекс. У меня есть подобные примеры в статьях, где я собираю в elasticsearch данные с разных сервисов.
Добрый день! Не подскажите с чем связано?
2021-02-18T11:39:20.437+0400#011ERROR#011[publisher_pipeline_output]#011pipeline/output.go:154#011Failed to connect to backoff(async(tcp://192.168.1.27:5044)): dial tcp 192.168.1.27:5044: connect: connection refused
Все заработало
Удалось решить?
Там явно была сетевая проблема. Либо в адресе ошибка, либо firewall не настроен, либо служба не запущена. Ошибка там вот какая: "connect: connection refused".
В последних версиях Elasticsearch ввели ограничение на максимум шардов (1000).
тут решение.
https://berrynetworks.wordpress.com/tag/max_shards_per_node/
Спасибо за полезную информацию.
1. Добрый день
2. Хочу запустить простейшую конфигурацию logstash, а именно:
logstash -e 'input { stdin { } } output { stdout { } }'
3. Сам исполняемый скрипт logstash у меня в Ubuntu 20 находится
/usr/share/logstash/bin/logstash
4. Находясь в каталоге из пункта 3, запускаю команду из пункта 2 и получаю command not found
PS в чем проблема ?
Попробуйте вот так запустить:
./logstash -e 'input { stdin { } } output { stdout { } }'
Спасибо, все получилось
Добрый день. Спасибо за статью, очень полезная информация. Есть пару вопросов. Предположим есть 2 и более серверов на них установлен LAMP или LEMP и множество virtual hosts. Как это разделить логи, каждый сервер отдельно, каждый vh отдельно??? Есть встроенный Dashboard Apache его можно использовать через logstash, без модуля filebeat apache??
Эту тему я разбираю отдельно - https://serveradmin.ru/monitoring-proizvoditelnosti-bekenda-s-pomoshhyu-elk-stack/
Вообще не стартует с вашим конфигом, и главное логи не пишеь filebeat
Так у вас версия может другая или еще что-то. Надо осмысленно подходить к настройке, а не просто копировать. Все мои примеры взяты с рабочих серверов, а не придуманы гипотетически. На момент публикации они все были рабочие.
Понятное дело, что я не копирую конфиги бездумно!
после добавления этих поле-
fields:
type: nginx_access
fields_under_root: true
отказывается стартовать filebeat
В синтаксисе конфигов важны отступы от начала строки.
Здравствуйте Владимир - POSTGRESQL MSSQL у вас есть готовый фильтр, - фомирования отчет как сделать Кибана
- через rssylog как отправить лог схд, cisco ASA,exsi host и фильтровать logstash
У меня этого нет.
Здравствуйте Владимир logstash filter у меня несколько как нескольких фильтер создать например syslog,nginx,windows,cisco,mikrotik у меня не получается нескольки фильтр сделать
Вот пример нескольких фильтров с рабочего сервера:
filter { if [type] == "nginx_access" { grok { match => [ "message" , "%{COMBINEDAPACHELOG}+%{GREEDYDATA:extra_fields}"] overwrite => [ "message" ] } mutate { convert => ["response", "integer"] convert => ["bytes", "integer"] convert => ["responsetime", "float"] } geoip { source => "clientip" target => "geoip" add_tag => [ "nginx-geoip" ] } date { match => [ "timestamp" , "dd/MMM/YYYY:HH:mm:ss Z" ] remove_field => [ "timestamp" ] } useragent { source => "agent" } } else if [type] == "smb-audit" { mutate { gsub => ["message","[\\|]",":"] gsub => ["message"," "," "] } grok { match => [ "message" , "%{MONTH:syslog_month} %{MONTHDAY:syslog_day} %{TIME:syslog_time} %{HOSTNAME:srv_name} smbd_audit: XS:%{GREEDYDATA:user_name}:%{IP:user_ip}:%{WORD:share_name}:%{WORD:action}:%{DATA:sucess}:%{GREEDYDATA:path}"] overwrite => [ "message" ] } } else if [type] == "smb-audit-xb" { mutate { gsub => ["message","[\\|]",":"] gsub => ["message"," "," "] } grok { match => [ "message" , "%{MONTH:syslog_month} %{MONTHDAY:syslog_day} %{TIME:syslog_time} %{HOSTNAME:srv_name} smbd_audit: %{IP:user_ip}:%{WORD:share_name}:%{WORD:action}:%{DATA:sucess}:%{GREEDYDATA:path}"] overwrite => [ "message" ] } } else if [event_data][AccessMask] == "0x10000" or [event_data][AccessMask] == "0x10080" { mutate { add_field => { "file_action" => "delete" } } } else if [event_data][AccessMask] == "0x2" or [event_data][AccessMask] == "0x6" { mutate { add_field => { "file_action" => "write" } } } else if [event_data][AccessMask] == "0x1" { mutate { add_field => { "file_action" => "read" } } } else if [host] == "10.1.4.19" or [host] == "10.1.5.1" or [host] == "10.1.4.31" { mutate { add_tag => [ "mikrotik", "gateway" ] } } else if [host] == "10.1.4.66" or [host] == "10.1.3.110" or [host] == "10.1.3.111" { mutate { add_tag => [ "mikrotik", "wifi" ] } } else if [host] == "10.1.4.14" or [host] == "10.1.5.33" or [host] == "10.1.3.11" { mutate { add_tag => [ "mikrotik", "switch" ] } } }Здравствуйте Владимир! за логсташ фильтр спасибо! у меня еще вапрос есть winlogbeat фильтер есть?
Да, вот эта часть фильтра обрабатывает данные из winlogbeat с windows серверов.
else if [event_data][AccessMask] == "0x10000" or [event_data][AccessMask] == "0x10080" { mutate { add_field => { "file_action" => "delete" } } } else if [event_data][AccessMask] == "0x2" or [event_data][AccessMask] == "0x6" { mutate { add_field => { "file_action" => "write" } } } else if [event_data][AccessMask] == "0x1" { mutate { add_field => { "file_action" => "read" } } }большое спасибо Владимир
Владимир, добрый день, покажите пожалуйста как выглядит filebeat.yml со стороны сервера с nginx?
filebeat.inputs: - type: log enabled: true paths: - /var/log/nginx/*-access.log fields: type: nginx_access fields_under_root: true scan_frequency: 5s - type: log enabled: true paths: - /var/log/nginx/*-error.log fields: type: nginx_error fields_under_root: true scan_frequency: 5s output.logstash: hosts: ["10.1.4.114:5044"]Добрый день, Владимир. Благодарю за статью.
Установил на VM Ubuntu 18.04, openjdk-8-jre, elasticsearch 7.7.0 из deb-пакета. Однако при попытке запустить службу elasticsearch получаю ошибку:
user1@elastic:~$ sudo systemctl start elasticsearch Job for elasticsearch.service failed because the control process exited with error code. See "systemctl status elasticsearch.service" and "journalctl -xe" for details. user1@elastic:~$ systemctl status elasticsearch.service ● elasticsearch.service - Elasticsearch Loaded: loaded (/usr/lib/systemd/system/elasticsearch.service; enabled; vendor preset: enabled) Active: failed (Result: exit-code) since Fri 2020-05-22 14:55:36 +05; 57s ago Docs: https://www.elastic.co Process: 2039 ExecStart=/usr/share/elasticsearch/bin/systemd-entrypoint -p ${PID_DIR}/elasticsearch.pid --quiet (code=exited, status=1/FA Main PID: 2039 (code=exited, status=1/FAILURE) мая 22 14:55:36 elastic systemd-entrypoint[2039]: at org.elasticsearch.bootstrap.Elasticsearch.execute(Elasticsearch.java:161) мая 22 14:55:36 elastic systemd-entrypoint[2039]: at org.elasticsearch.cli.EnvironmentAwareCommand.execute(EnvironmentAwareCommand. мая 22 14:55:36 elastic systemd-entrypoint[2039]: at org.elasticsearch.cli.Command.mainWithoutErrorHandling(Command.java:127) мая 22 14:55:36 elastic systemd-entrypoint[2039]: at org.elasticsearch.cli.Command.main(Command.java:90) мая 22 14:55:36 elastic systemd-entrypoint[2039]: at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:126) мая 22 14:55:36 elastic systemd-entrypoint[2039]: at org.elasticsearch.bootstrap.Elasticsearch.main(Elasticsearch.java:92) мая 22 14:55:36 elastic systemd-entrypoint[2039]: For complete error details, refer to the log at /var/log/elasticsearch/elasticsearch.log мая 22 14:55:36 elastic systemd[1]: elasticsearch.service: Main process exited, code=exited, status=1/FAILURE мая 22 14:55:36 elastic systemd[1]: elasticsearch.service: Failed with result 'exit-code'. мая 22 14:55:36 elastic systemd[1]: Failed to start Elasticsearch.Надо лог эластика смотреть - For complete error details, refer to the log at /var/log/elasticsearch/elasticsearch.log
Там должна быть видна причина ошибки.
Спасибо. Попробовал на CentOS 8 - та же проблема. В логах вот что написано:
[2020-05-25T12:09:16,647][ERROR][o.e.b.ElasticsearchUncaughtExceptionHandler] [localhost.localdomain] uncaught exception in thread [main]
org.elasticsearch.bootstrap.StartupException: ElasticsearchException[Failure running machine learning native code. This could be due to running on an unsupported OS or distribution, missing OS libraries, or a problem with the temp directory. To bypass this problem by running Elasticsearch without machine learning functionality set [xpack.ml.enabled: false].]
Судя по инфе на сайте эластика, корень проблемы в моём старом Phenom II X4, который не поддерживает инструкции SSE4.2:
Вам не нужно настраивать какие-либо параметры для использования машинного обучения. Это включено по умолчанию.
Машинное обучение использует инструкции SSE4.2, поэтому будет работать только на машинах, процессоры которых поддерживают SSE4.2. Если вы запускаете Elasticsearch на старом оборудовании, вы должны отключить машинное обучение (установив для xpack.ml.enabled значение false).
Все эти параметры могут быть добавлены в файл конфигурации elasticsearch.yml. Динамические настройки также можно обновлять в кластере с помощью API настроек обновления кластера.
Динамические настройки имеют приоритет над настройками в файле elasticsearch.yml.
Собственно прописал в /etc/elasticsearch/elasticsearch.yml строку:
xpack.ml.enabled: false
и служба эластика запустилась.
Спасибо за информацию.
Здравствуйте, если можно более подробно разъяснить момент по сбору логов logstash от winlogbeats. Я не хочу разделять каждый виндовый сервер на свой индекс. И хотел бы чтобы все логи с виндовых серверов сыпались в один индекс. Как сконфигурировать winlogbeat.yml и output.conf в плане тегов. Я так понимаю что в winlogbeat.yml на каждом сервере нужно полностью убрать строку tags: ["winsrv"] а в output.conf
output {
if [type] == "wineventlog" {
elasticsearch {
hosts => "localhost:9200"
index => "wineventlog-%{+YYYY.MM.dd}"
}
}
else {
elasticsearch {
hosts => "localhost:9200"
index => "unknown_messages"
}
}
#stdout { codec => rubydebug }
}
Здравствуйте, Владимир!
Спасибо большое за то, что потратили время и написали этот материал. Лишь благодаря вам удалось понять саму концепцию "как это все работает". После тестовой установки по вашему примеру, появилось полное понимание как я могу построить собственную систему сбора логов из своих источников.
А до вашей статьи, даже с хорошим английским, с официально документацией, это было весьма сложно. Как вы верно написали - я полностью согласен: официальная документация неплохая, но сильно уж она разбросанная и чтобы в ней разобраться человеку, который с ELK никогда не работал - можно мозг сломать.
Благодарю еще раз и желаю удачи в профессиональном направлении!
С уважением
А подскажите по какому принципу ELK удаляет старые данные? Где это настраивается?
Сам он ничего не удаляет. Надо настраивать. Либо самому запросы на удаление формировать, либо использовать какой-то софт. У меня в разделе есть статья по очистке elk с помощью curator.
Cпасибо, как всегда интересно.
В инструкции по установке Elasticsearch на Debian'e (да и на CentOS) на родном сайте написано что OpenJDK уже входит в дистрибутив (
"Elasticsearch includes a bundled version of OpenJDK from the JDK maintainers (GPLv2+CE). To use your own version of Java, see the JVM version requirements"). И я так понимаю что отдельная установка Java не требуется. Сам проверял, работает.
Отлично. Хорошо, что они это сделали. Одной проблемой меньше.
И в дистрибутив Kibana входит OpenJDK. А вот в Logstash его кажись нет :( Вот прикол.
Не стал устанавливать отдельно JAVA, а в вашей инструкции по установке JAVA поменял /usr/lib/jvm/jre1.8.0_231 на /usr/share/elasticsearch/jdk. Т.е. прописал JAVA на JDK, входящий в поставку Elasticsearch. И Logstash пошёл!
Доброго времени суток!
Помогите пожалуйста разобраться
Logstash вываливается с ошибкой:
[2020-03-19T10:46:39,215][DEBUG][logstash.agent ] Converging pipelines state {:actions_count=>1}
[2020-03-19T10:46:39,230][DEBUG][logstash.agent ] Executing action {:action=>LogStash::PipelineAction::Create/pipeline_id:main}
[2020-03-19T10:46:39,637][ERROR][logstash.agent ] Failed to execute action {:action=>LogStash::PipelineAction::Create/pipeline_id:main, :exception=>"LogStash::ConfigurationError", :message=>"Expected one of [ \\t\\r\\n], \"#\", [A-Za-z0-9_-], '\"', \"'\", [A-Za-z_], \"-\", [0-9], \"[\", \"{\", \"]\" at line 5, column 1 (byte 28) after filter\n{\ngrok {\nmatch => [\n", :backtrace=>["/usr/share/logstash/logstash-core/lib/logstash/compiler.rb:47:in `compile_imperative'", "/usr/share/logstash/logstash-core/lib/logstash/compiler.rb:55:in `compile_graph'", "/usr/share/logstash/logstash-core/lib/logstash/compiler.rb:17:in `block in compile_sources'", "org/jruby/RubyArray.java:2580:in `map'", "/usr/share/logstash/logstash-core/lib/logstash/compiler.rb:14:in `compile_sources'", "org/logstash/execution/AbstractPipelineExt.java:161:in `initialize'", "org/logstash/execution/JavaBasePipelineExt.java:47:in `initialize'", "/usr/share/logstash/logstash-core/lib/logstash/java_pipeline.rb:27:in `initialize'", "/usr/share/logstash/logstash-core/lib/logstash/pipeline_action/create.rb:36:in `execute'", "/usr/share/logstash/logstash-core/lib/logstash/agent.rb:326:in `block in converge_state'"]}
[2020-03-19T10:46:39,760][DEBUG][logstash.instrument.periodicpoller.os] Stopping
[2020-03-19T10:46:39,759][DEBUG][logstash.agent ] Starting puma
[2020-03-19T10:46:39,782][DEBUG][logstash.agent ] Trying to start WebServer {:port=>9600}
[2020-03-19T10:46:39,785][DEBUG][logstash.instrument.periodicpoller.jvm] Stopping
[2020-03-19T10:46:39,786][DEBUG][logstash.instrument.periodicpoller.persistentqueue] Stopping
[2020-03-19T10:46:39,787][DEBUG][logstash.instrument.periodicpoller.deadletterqueue] Stopping
[2020-03-19T10:46:39,810][DEBUG][logstash.agent ] Shutting down all pipelines {:pipelines_count=>0}
[2020-03-19T10:46:39,841][DEBUG][logstash.api.service ] [api-service] start
[2020-03-19T10:46:39,842][DEBUG][logstash.agent ] Converging pipelines state {:actions_count=>0}
[2020-03-19T10:46:40,020][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
[2020-03-19T10:46:44,926][INFO ][logstash.runner ] Logstash shut down.
У вас ошибка в конфиге:
at line 5, column 1 (byte 28) after
filter {
grok {
match =>
Вот не понятно в чем именно ошибка...
filter
{
grok {
match => [
%{IP:client_ip} %{NOTSPACE:haproxy_timestamp} %{NOTSPACE:frontend_name} %{NOTSPACE:backend_name} %{NOTSPACE:server_name} %{NUMBER:time_client_req:int} %{NUMBER:time_queue:int} %{NUMBER:time_backend_connect:int} %{NUMBER:time_server_response:int} %{NUMBER:time_duration:int} %{NUMBER:status_code:int} %{NUMBER:bytes_read:int} %{NOTSPACE:captured_request_cookie} %{NOTSPACE:captured_response_cookie} %{NOTSPACE:termination_state_with_cookie_status} %{NUMBER:actconn:int} %{NUMBER:feconn:int} %{NUMBER:beconn:int} %{NUMBER:srvconn:int} %{NUMBER:retries:int} %{NUMBER:srv_queue:int} %{NUMBER:backend_queue:int} %{GREEDYDATA:full_http_request} %{NOTSPACE:captured_response_headers}
]
}
}
Такие штуки муторно диагностировать, согласен :) Сам много времени терял. Но в выражении где-то ошибка 100%. Надо внимательно синтаксис проверять, все закрывающие скобки и т.д. Я всегда в итоге находил ошибку и исправлял.
здравствуйте, нужна Ваша помощь,,, после запуска service kibana start на centos пишет что kibana is running curl -v * About to connect() to мой_сервер port 5601 (#0)
* Trying мой_сервер... connected
* Connected to мой_сервер (мой_сервер) port 5601 (#0)
> GET / HTTP/1.1
> User-Agent: curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.44 zlib/1.2.3 libidn/1.18 libssh2/1.4.2
> Host: мой_сервер:5601
> Accept: */*
>
< HTTP/1.1 302 Found
< location: /spaces/enter
< kbn-name: kibana.local
< kbn-license-sig: bf7bf1883eaa1463bf6d0422ee40fedf779ac9d39b2a32028a9c725472c11133
< kbn-xpack-sig: 7db707bf28764972b882aff76746cc59
< cache-control: no-cache
< content-length: 0
< Date: Wed, 18 Mar 2020 08:39:57 GMT
< Connection: keep-alive
<
* Connection #0 to host мой_сервер left intact
* Closing connection #0
вывод log
{"type":"response","@timestamp":"2020-03-18T08:39:57Z","tags":[],"pid":1452,"method":"get","statusCode":302,"req":{"url":"/","method":"get","headers":{"user-agent":"curl/7.19.7 (x86_64-redhat-linux-gnu) libcurl/7.19.7 NSS/3.44 zlib/1.2.3 libidn/1.18 libssh2/1.4.2","host":"81.95.133.151:5601","accept":"*/*"},"remoteAddress":"81.95.133.151","userAgent":"81.95.133.151"},"res":{"statusCode":302,"responseTime":50,"contentLength":9},"message":"GET / 302 50ms - 9.0B"}
Здравствуйте ! При копиривании публичного ключа репозитория elastica выдает такую ошибку (35) SSL connect error
Zerox, доброго времени суток, хотелось бы выразить Вам большую благодарность за проделанную работу. Вы могли бы оставить счёт WM или альтернативный кошелек?
И еще у меня есть к Вам вопрос. Стоит задача сбора логов с разных типов устройств, свитчи разных производителей, роутеры, принтеры, сервера в конце концов. Возможно ли это реализовать с помощью конфигурации, которая приведена в данной статье? В данный момент получается только собрать логи с windows через агента. Если на порт 5044 отправить логи, например, с микротика, то они не приходят в общий список. Может, у Вас есть конфигурационный файл, который позволил бы принимать логи со всех устройств? Был бы очень признателен за помощь.
Вот пример сбора логов с сетевых устройств - https://serveradmin.ru/tsentralizovannyiy-sbor-logov-mikrotik-v-elk-stack/
Можете сделать по аналогии.
После установки и настройки Kibana а именно после вот этого места (Теперь можно зайти в веб интерфейс по адресу http://10.1.4.114:5601) выдает сообщение "Kibana server is not ready yet". В файле kibana.yml ни каких изменений не вносил кроме server.host: который поменял на адрес своего сервера. Изменения вношу с помощью visual studio code подключаясь по SSH к серверу, так удобнее потому что он показывает синтаксические ошибки в yml файлах. Ни как не могу понять в чем дело, подскажите пожалуйста.
Обычно кибана показывает такое сообщение, когда ее только запустили и она еще не полностью загрузилась. Если сообщение не пропадает, надо смотреть логи кибаны и искать ошибки.
Еще вопрос, возможно глупый. Не могу понять куда кибана пишет свой лог по умолчанию. По стандартному пути "/var/log/kibana" ничего нет, даже деректории kibana нет. И внутри конфигурационного файла не нашел путь до лога. Хотя в документации говориться что логи должны быть там .
Она по умолчанию в системный syslog пишет, так что ее логи надо смотреть в /var/log/messages. Не знаю, зачем они так сделали. Очень неудобно.
В проблеме разобрался, по каким то причинам не стартует служба elasticsearch, поэтому и появлялось данное сообщение.
Вот кстати да. elasticsearch сам не стартует при запуске, пишет: elasticsearch.service: Start operation timed out. Terminating Приходится вручную перезапускать.
Установка : 1:logstash-7.6.0-1.noarch 1/1
Using provided startup.options file: /etc/logstash/startup.options
Errno::ENOMEM: Cannot allocate memory - systemctl
spawn at org/jruby/RubyProcess.java:1636
spawn at org/jruby/RubyKernel.java:1667
popen_run at /usr/share/logstash/vendor/jruby/lib/ruby/stdlib/open3.rb:202
popen3 at /usr/share/logstash/vendor/jruby/lib/ruby/stdlib/open3.rb:98
execute at /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/pleaserun-0.0.30/lib/pleaserun/detector.rb:74
detect_systemd at /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/pleaserun-0.0.30/lib/pleaserun/detector.rb:29
detect_platform at /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/pleaserun-0.0.30/lib/pleaserun/detector.rb:24
detect at /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/pleaserun-0.0.30/lib/pleaserun/detector.rb:18
setup_defaults at /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/pleaserun-0.0.30/lib/pleaserun/cli.rb:153
execute at /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/pleaserun-0.0.30/lib/pleaserun/cli.rb:119
run at /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/clamp-0.6.5/lib/clamp/command.rb:67
run at /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/pleaserun-0.0.30/lib/pleaserun/cli.rb:114
run at /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/clamp-0.6.5/lib/clamp/command.rb:132
at /usr/share/logstash/lib/systeminstall/pleasewrap.rb:12
Unable to install system startup script for Logstash.
chmod: невозможно получить доступ к «/etc/default/logstash»: Нет такого файла или каталога
warning: %post(logstash-1:7.6.0-1.noarch) scriptlet failed, exit status 1
Non-fatal POSTIN scriptlet failure in rpm package 1:logstash-7.6.0-1.noarch
Проверка : 1:logstash-7.6.0-1.noarch 1/1
Установлено:
logstash.noarch 1:7.6.0-1
Установить, установилось, но...
# systemctl enable logstash.service
Failed to execute operation: No such file or directory
Оперативной памяти не хватает на сервере.
Errno::ENOMEM: Cannot allocate memory — systemctl
Хочу собирать логи и анализировать с microtika . Вопрос как его подконектить к ELK стеку? по SMNP?
Есть статья по этой теме - https://serveradmin.ru/tsentralizovannyiy-sbor-logov-mikrotik-v-elk-stack/
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
curl: (7) Failed to connect to 2a04:4e42:400::734: Сеть недоступна
ошибка: https://artifacts.elastic.co/GPG-KEY-elasticsearch: import read failed(2).
как победить?
У вас подключение идет по ipv6, которое судя по всему не работает или не настроено. Отключите ipv6 на сервере.
GeoLite2-City.mmdb.gz недоступен
Да, с 30-го декабря 2019 загрузка по прямой ссылке не доступна. Качать надо отсюда https://dev.maxmind.com/geoip/geoip2/geolite2/#Download_Access Нужна регистрация. Тут рассказано, почему это произошло - https://blog.maxmind.com/2019/12/18/significant-changes-to-accessing-and-using-geolite2-databases/
Дмитрий, добрый день!
На нашем сайте в качестве полнотекстового поиска используется Elastic.
Возможно ли привлечь вас в качестве эксперта для настройки поиска?
Я не эксперт в поиске с помощью elasticsearch. Кроме как хранилища для логов я его никогда не использовал.
есть альтернатива GEOIP.site
Попробуйте скачать оттуда.
Приветствую всех! Может что то упустил в статье и поэтому хотел узнать есть winlogbeat а для Linux Centos какое название? Прям стыдно но не могу найти O_o
Спасибо!
Filebeat.
Добрый день!
Настроил ELK для снятия логов с Suricata. Данные получаю, визуализация есть, но не отображаются карты на дашборде, вообще никакие не работают. Появляется всплывающее сообщение вида:
----
Unable to retrieve manifest from https://catalogue.maps.elastic.co/v7.2/manifest?elastic_tile_service_tos=agree&my_app_name=kibana&my_app_version=7.4.0&license=e1f60445-b8a0-46a1-81b1-4bd37e85f15f: Request to https://catalogue.maps.elastic.co/v7.2/manifest?elastic_tile_service_tos=agree&my_app_name=kibana&my_app_version=7.4.0&license=e1f60445-b8a0-46a1-81b1-4bd37e85f15f timed out
----
Подскажите, пожалуйста, путь для решения данной проблемы.
Разобрался: в Firefox установлены плагины NoScript и AdBlock, они блокировали отрисовку карты. Открыл Kibana в Chrome и IE - все работает отлично.
Наглядный пример, когда блокировщики усложняют жизнь. Поэтому у меня они по дефолту отключены, включаю вручную. Были моменты, когда терял время из-за них на похожих вещах.
А какой context выставлять для SElinux для /etc/postfix/certs/cert.pem. У меня ругается dovecot на него, permission denied. В permissive вот что пишет: type=AVC msg=audit(1571069892.328:103): avc: denied { open } for pid=3372 comm="doveconf" path="/etc/postfix/certs/cert.pem" dev="vda1" ino=4941451 scontext=system_u:system_r:dovecot_t:s0 tcontext=unconfined_u:object_r:postfix_etc_t:s0 tclass=file permissive=1. Пробовал прописать dovecot_cert_t/dovecot_etc_t, не помогло, опять же как бы у postfix не пропал доступ.
Добрый день! А что за плагин вставки кода в WP?
Не понял вопрос.
У вас есть раздел содержание, там якорные ссылки чем реализованы
Это плагин для wordpress - Table of Contents.
После указания 127.0.0.1 в /etc/elasticsearch/elasticsearch.yml служба elasticsearch не запускается:
elasticsearch.service - Elasticsearch
Loaded: loaded (/lib/systemd/system/elasticsearch.service; enabled; vendor preset: enabled)
Active: failed (Result: exit-code) since Sat 2019-08-10 00:06:24 CDT; 16s ago
Docs: http://www.elastic.co
Process: 2782 ExecStart=/usr/share/elasticsearch/bin/elasticsearch -p ${PID_DIR}/elasticsearch.pid --quiet (code=ex
Main PID: 2782 (code=exited, status=1/FAILURE)
Aug 10 00:06:24 debian elasticsearch[2782]: in 'reader', line 55, column 3:
Aug 10 00:06:24 debian elasticsearch[2782]: network.host: 127.0.0.1
И ещё у меня почему то logstash не в какую не хочет слушать порт который я указываю.
(фаервол офф, службу перезапускал , по первому вопросу тоже самое с фаерволом и перезапуском службы)
Доброго времени суток. Может я что-то не понимаю, может что-то делаю не так, но подскажите в чем может быть проблема.
Устанавливаю данный стэк на виртуальную машину Centos 7. После установки Kibana не могу попасть на его веб-интерфейс, прописывал в файле конфигурации localhost, ip данного сервера, внешний ip сервера и делал проброс портов, ничего не помогает. Сервис перезапускал, работает нормально. Фаервол отключен.
p.s. делаю все без ngnix
*Если же у вас это тестовая установка, то можно обойтись без nginx. Для этого надо разрешить Кибана слушать внешний интерфейс и принимать подключения. Измените параметр server.host, указав ip адрес сервера, например вот так:
Доброго времени суток!
Запнулся на запуске logstash - упорно не читает конфиги в conf.d (а также ничего не пишет в лог) при запуске в качестве сервиса.
Гуглил, проблема не нова - но не одно из предложенных решений не подошло (в основном они касались прав доступа или файрвола - эти моменты проверил в первую очередь).
systemctl status logstash пишет, что сервис работает, но порт 5044 не слушается.
Обратил внимание на строку в /etc/systemd/system/logstash.service:
ExecStart=/usr/share/logstash/bin/logstash "--path.settings" "/etc/logstash"
Попытка выполнить /usr/share/logstash/bin/logstash "--path.settings" "/etc/logstash" провалилась.
Исправил на /usr/share/logstash/bin/logstash --path.settings /etc/logstash
В скрине запустилось нормально, порт слушался, в /var/log/logstash/logstash-plain.log запись идет.
Исправил аналогично в /etc/systemd/system/logstash.service и сделал systemctl daemon-reload
При попытке запуска демоном (systemctl start logstash) та же картина: видно, что сервис работает, но порт не слушается и в логе новых записей нет.
ОС - CentOS Linux release 7.6.1810 (Core)
Буду благодарен, если натолкнете на мысль, куда копать :)
Интересно. Я делал несколько установок по этой статье. Все прошли успешно. Возможно, в недавних обновлениях что-то сломали.
Я не понял, что значит попытка выполнить провалилась. Какая ошибка была? В systemd указан неверный путь?
Там просто кавычки неправильно применены были. При ручном запуске такая картина:
[root@elk ~]# /usr/share/logstash/bin/logstash "path.settings" "/etc/logstash"
WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults
ERROR: Unknown command 'path.settings'
See: 'bin/logstash --help'
[ERROR] 2019-07-15 21:07:51.415 [main] Logstash - java.lang.IllegalStateException: Logstash stopped processing because of an error: (SystemExit) exit
Сорри, некорректно команду вставил, но от этого мало что изменилось.
Вариант с кавычками (как было в /etc/systemd/system/logstash.service изначально):
/usr/share/logstash/bin/logstash «--path.settings» «/etc/logstash»
WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using —path.settings. Continuing using the defaults
ERROR: Unknown command ‘path.settings’
See: ‘bin/logstash —help’
[ERROR] 2019-07-15 21:07:51.415 [main] Logstash — java.lang.IllegalStateException: Logstash stopped processing because of an error: (SystemExit) exit
Вариант без кавычек (исправленный мною):
[root@elk ~]# /usr/share/logstash/bin/logstash --path.settings /etc/logstash
Sending Logstash logs to /var/log/logstash which is now configured via log4j2.properties
[2019-07-15T21:12:00,219][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"6.8.1"}
[2019-07-15T21:12:14,783][INFO ][logstash.pipeline ] Starting pipeline {:pipeline_id=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>50}
[2019-07-15T21:12:15,774][INFO ][logstash.outputs.elasticsearch] Elasticsearch pool URLs updated {:changes=>{:removed=>[], :added=>[http://localhost:9200/]}}
[2019-07-15T21:12:16,253][WARN ][logstash.outputs.elasticsearch] Restored connection to ES instance {:url=>"http://localhost:9200/"}
[2019-07-15T21:12:16,399][INFO ][logstash.outputs.elasticsearch] ES Output version determined {:es_version=>6}
[2019-07-15T21:12:16,406][WARN ][logstash.outputs.elasticsearch] Detected a 6.x and above cluster: the `type` event field won't be used to determine the document _type {:es_version=>6}
[2019-07-15T21:12:16,464][INFO ][logstash.outputs.elasticsearch] New Elasticsearch output {:class=>"LogStash::Outputs::ElasticSearch", :hosts=>["//localhost:9200"]}
[2019-07-15T21:12:16,494][INFO ][logstash.outputs.elasticsearch] Using default mapping template
[2019-07-15T21:12:16,552][INFO ][logstash.outputs.elasticsearch] Attempting to install template {:manage_template=>{"template"=>"logstash-*", "version"=>60001, "settings"=>{"index.refresh_interval"=>"5s"}, "mappings"=>{"_default_"=>{"dynamic_templates"=>[{"message_field"=>{"path_match"=>"message", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false}}}, {"string_fields"=>{"match"=>"*", "match_mapping_type"=>"string", "mapping"=>{"type"=>"text", "norms"=>false, "fields"=>{"keyword"=>{"type"=>"keyword", "ignore_above"=>256}}}}}], "properties"=>{"@timestamp"=>{"type"=>"date"}, "@version"=>{"type"=>"keyword"}, "geoip"=>{"dynamic"=>true, "properties"=>{"ip"=>{"type"=>"ip"}, "location"=>{"type"=>"geo_point"}, "latitude"=>{"type"=>"half_float"}, "longitude"=>{"type"=>"half_float"}}}}}}}}
[2019-07-15T21:12:17,713][INFO ][logstash.inputs.beats ] Beats inputs: Starting input listener {:address=>"0.0.0.0:5044"}
[2019-07-15T21:12:17,767][INFO ][logstash.pipeline ] Pipeline started successfully {:pipeline_id=>"main", :thread=>"#"}
[2019-07-15T21:12:18,016][INFO ][logstash.agent ] Pipelines running {:count=>1, :running_pipelines=>[:main], :non_running_pipelines=>[]}
[2019-07-15T21:12:18,055][INFO ][org.logstash.beats.Server] Starting server on port: 5044
[2019-07-15T21:12:18,664][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
Не могу пока разобраться, почему даже исправленный вариант не работает корректно через systemd
Доброго времени суток! Вы разобрались с прослушиванием порта 5044?
Спасибо за сей opus magnum.
Подскажите, настроил все по вами приведенному мануалу. Дошел до создание индексов в kibana. Имеется куча патернов типа nginx-2018.11.15, но Next step не активен
Добрый день.
Настроил стек ELK. В принципе все работает. Но после того как дал на него нагрузку, возникли проблемы с отображением информации в Kibana. В системе следующие серверы: 1 сервер -> мастер-нода (ОЗУ 16 Гб); 2 сервера -> 2 дата-ноды (64 ГБ, 64 Гб), 1 сервер -> Logstash, 1 сервер - Kibana. Связка с winlogbeat.
При поиске (например 7 дней) возникает ошибка:
SearchError: Request Timeout after 30000ms
at http://ХХ.ХХ.ХХ.ХХХ:5601/bundles/commons.bundle.js:4:324908
at processQueue (http://ХХ.ХХ.ХХ.ХХХ:5601/built_assets/dlls/vendors.bundle.dll.js:427:199687)
at http://ХХ.ХХ.ХХ.ХХХ:5601/built_assets/dlls/vendors.bundle.dll.js:427:200650
at Scope.$digest (http://ХХ.ХХ.ХХ.ХХХ:5601/built_assets/dlls/vendors.bundle.dll.js:427:210412)
at http://ХХ.ХХ.ХХ.ХХХ:5601/built_assets/dlls/vendors.bundle.dll.js:427:212944
at completeOutstandingRequest (http://ХХ.ХХ.ХХ.ХХХ:5601/built_assets/dlls/vendors.bundle.dll.js:427:64425)
at http://ХХ.ХХ.ХХ.ХХХ:5601/built_assets/dlls/vendors.bundle.dll.js:427:67267
Из настроек:
-Xms32766m
-Xmx32766m
Есть идеи как полечить?
А что по нагрузке? Может железо не тянет? Я как вижу подобную ошибку, чищу индексы, отпускает.
Добрый день.
Установка java 8 на ubuntu больше не работает через apt install oracle-java8-installer - https://launchpad.net/~webupd8team/+archive/ubuntu/java
Теперь только ручная установка, либо из другого репозитория. После установки еще нужно будет вручную задать JAVA_PATH в elasticsearch.yml
Да, и это печальная история. Вчера намаялся с этой явой на убунте 18. Напишу статью по этой теме, она актуальна. В общем случае все просто, но иногда возникают нюансы.
Написал отдельную статью на эту тему - https://serveradmin.ru/ustanovka-oracle-java-na-ubuntu-i-centos/
Не понял:
"Оказалось, что модули filebeat работают только в том случае, если вы отправляете данные напрямую в elasticsearch.", когда в следующем пункте устанавливаем filebeat для отправки логов в logstash.
Имеется ввиду, когда filebeat установлен на одной машине с elasticsearch?
Что именно не понятно? Модули filebeat работают только с elasticsearch напрямую. Я в своей статье использую logstash для начального сбора и обработки логов с filebeat, поэтому их модули мне не нужны. Они с logstash не работают.
Не понимал, какие именно модули. Из оф доки стало понятнее https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-reference-yml.html.
Спасибо за статью!
Спасибо. Всё отлично. Всё работает.
[root@server ~]# wget https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-6.6.0.noarch.rpm
--2019-03-23 20:33:01-- https://download.elastic.co/elasticsearch/elasticsearch/elasticsearch-6.6.0.noarch.rpm
Resolving download.elastic.co (download.elastic.co)... 151.101.38.217, 2a04:4e42:9::729
Connecting to download.elastic.co (download.elastic.co)|151.101.38.217|:443... connected.
HTTP request sent, awaiting response... 404 Not Found
2019-03-23 20:33:02 ERROR 404: Not Found.
С чем может быть связана ошибка?
404: Not Found
Ссылка битая.
Я конечно извиняюсь за тупой вопрос.
А какие мощнасти сервера нужны чтобы поставить это все?
Напрямую зависит от нагрузки и от суммарного объема логов. Стартануть можно спокойно с 2 CPU, 4 Gb и обычного SATA диска.
Uze 4 den nie mogu reshyt problemku, mozet tut umnye ludi pidskazut, za ranee spasibo:
curl localhost:5044
curl: (56) Recv failure: Connection reset by peer
Сервис на порту 5044 сбрасывает соединение. Причин может быть огромное количество, почему это происходит. Надо логи сервиса смотреть.
в конфиге nginx в параметре "server_name kibana.site.ru" --- нет в конце ;
Спасибо, поправил.
Добавьте пожалуйста в статью:
Необходимой утилиты нет в системе. Установим htpasswd на centos:
# yum install -y httpd-tools
Добавил.
все бы хорошо, но после запуска и добавления 3-х хостов вылезла ошибка
elasticsearch - Attempted to send a bulk request to elasticsearch, but no there are no living connections in the connection pool. Perhaps Elasticsearch is unreachable or down? {:error_message=>"No Available connections", :class=>"LogStash::Outputs::ElasticSearch::HttpClient::Pool::NoConnectionAvailableError", :will_retry_in_seconds=>64}
при запуске elasticsearch выходит такая ошибка
main ERROR RollingFileManager (/logdb/log/elasticsearch/elasticsearch_index_search_slowlog.log) java.io.FileNotFoundException: /logdb/log/elasticsearch/elasticsearch_index_search_slowlog.log (Permission denied) java.io.FileNotFoundException: /logdb/log/elasticsearch/elasticsearch_index_search_slowlog.log (Permission denied)
main ERROR Unable to invoke factory method in class org.apache.logging.log4j.core.appender.RollingFileAppender for element RollingFile: java.lang.IllegalStateException: No factory method found for class org.apache.logging.log4j.core.appender.RollingFileAppender java.lang.IllegalStateException: No factory method found for class org.apache.logging.log4j.core.appender.RollingFileAppender
main ERROR RollingFileManager (/logdb/log/elasticsearch/elasticsearch_deprecation.log) java.io.FileNotFoundException: /logdb/log/elasticsearch/elasticsearch_deprecation.log (Permission denied) java.io.FileNotFoundException: /logdb/log/elasticsearch/elasticsearch_deprecation.log (Permission denied)
main ERROR RollingFileManager (/logdb/log/elasticsearch/elasticsearch_audit.log) java.io.FileNotFoundException: /logdb/log/elasticsearch/elasticsearch_audit.log (Permission denied) java.io.FileNotFoundException: /logdb/log/elasticsearch/elasticsearch_audit.log (Permission denied)
Тут явно какие-то локальные проблемы с правами, под которыми запускается elasticsearch. Разбирайтесь в этом направлении.
Добрый день, с права разобрался, теперь другая проблема
[WARN ] 2019-01-28 16:06:43.907 [Ruby-0-Thread-10: :1] elasticsearch - Attempted to resurrect connection to dead ES instance, but got an error. {:url=>"http://localhost:9200/", :error_type=>LogStash::Outputs::ElasticSearch::HttpClient::Pool::HostUnreachableError, :error=>"Elasticsearch Unreachable: [http://localhost:9200/][Manticore::SocketException] Connection refused (Connection refused)"}
[ERROR] 2019-01-28 16:07:08.271 [Ruby-0-Thread-16: :1] elasticsearch - Attempted to send a bulk request to elasticsearch, but no there are no living connections in the connection pool. Perhaps Elasticsearch is unreachable or down? {:error_message=>"No Available connections", :class=>"LogStash::Outputs::ElasticSearch::HttpClient::Pool::NoConnectionAvailableError", :will_retry_in_seconds=>64}
Доброе утро, оказалось что Elasticsearch не может обработать огромное колличество логов и из за этого уходит в down, я пытался логировать Oracle WebLogic Server установленный на Windows Server 2008 R2. Теперь наверное придется выборку сделать по eventid.
Спасибо за инфу. По идее, перегрузку можно видеть по нагрузке на систему. Если проц и память все заняты, то по-любому, надо что-то делать.
Добрый день, как раз нагрузки на систему не было, а дело решилось тем что необходимо было в файле /etc/elasticsearch/jvm.options изменить параметры -Xms8g -Xmx8g, на моей ОС общей памяти 16Гб, и поэтому поставил 8Гб в параметрах. Так же у меня каталоги были отличные от дефолтных для данных и логов поэтому и другие строчки так же изменил это -XX:HeapDumpPath= , -XX:ErrorFile= , 8:-Xloggc: .
Насколько разумно использовать в этом стеке Grafana вместо Kibana? Первая уже поднята и активно используется и второй фронт кажется избыточным (если конечно настройка графаны внутри стека не займет очень много времени). У вас есть опыт?
Опыта нет, но насколько мне известно, графана не сможет продублировать функционал kibana полностью. Вопрос в том, что вы хотите получить на выходе. Настроить дашборды в графане получится, но в кибана функционал не ограничивается только дашбордами. Мне кажется, разумнее всего поставить таки elk полностью с kibana, все настройки делать в ней. А в графану вывести то, что нужно визуализировать. Сама по себе установка kibana не представляет никакой сложности. Я не вижу ни одной причины, почему бы ее не поставить.
Добрый день, возможно ли данной связкой настроить систему логирования и мониторинга для системной информации. syslog. в крации есть парк машин 150+ серверов. и я хочу реализовать хорошую и удобную систему отслежки логов.
Да, конечно можно. Можно текстовые логи забирать с сервера с помощью filebeat, а можно сразу в logstash передавать напрямую с системного rsyslog, настроив на нем передачу логов на удаленный syslog сервер.
добрый день,
что с местом, сколлько надо под это дело? понимаю, что многое зависит от количества собираемого и т.д., но скажем есть какой-то минимум же...?
спасибо!
Так о каком минимуме речь? Это же база данных. Сама она занимает немного. Занимают места данные, поэтому как можно заранее сказать, сколько они будут занимать? Даже примерно не прикинешь. У меня есть несколько установок, но там везде очень разные данные и информация оттуда будет неактуальна для других систем.
Спасибо за статью. Есть пра предложений в плане удобства. В полях где написаны комманды не писать знак # а то при копировании всей строки попадает иногда. И в тексте где есть какие-то пути конфигов к конце после названия не нужно ставить точку (ну или с пробелом) а то копируя текст попадает и точка на которую не всегда обращаешь внимание, в результате создается не тот файл который должен быть. lof.conf. заменить на log.conf . Как вариант.
Замечания справедливые, особенно первое. Мне самому не нравится, но не знаю, как все это теперь исправить, чтобы во всем сайте было единообразие. К тому же консоль бывает разная. # приветствие в обычной консоли linux, а иногда заходишь в консоль mysql - там будет >, где-то $ и т.д. То есть консоли иногда надо отличать. В идеале знак консоли вынести из самой строки для копирования, но я не знаю, как это сделать. Надо со стилями разбираться и какой-то мод для wordpress писать, чтобы потом в редакторе можно было этим управлять. В общем, пока останется так, как есть :)
Привет! сделал всё по статьи, всё получилось, но только лдокально, чьё то с удалённых linux/win сервера не придут данные, на linux глянул в логах filebeat там есть куча инфо, но в лог файла написано. что в elasticsearch не включено xpack.monitoring, а если мы добавили xpack.monitoring на filebeat на удалённных хостах. а может быть и на самом сервер добавить?
уже несколько дней делаю по разным стстьям много чего получается, но только локально, нучну делать удалённо не получается, а эта может быть связано с https(nginx) ?
xpack.monitoring влияет только на сам мониторинг и больше ни на что. Можно включить, посмотреть на него. Я потестил и выключил, так как использую zabbix везде. Тут лишний мониторинг только ресурсы потреблять будет.
Привет! Сделал как написано, всё чётко получилось, спасибо бро, продолжай!!! :) ты Сепрмен. Сделал с Nginx круто
Будет много статей по этой теме. У меня уже прилично систем заведены на ELK Stack со своими дашбордами. Надо только время свободное на написание статей.
все таки очень хочется анализировать трафик с mikrotika не могу соединить воедино эти две системы
Следующая статья про микротик будет. У меня уже настроено это все и работает.
Тоже разобрался и настроил, но не могу понять как настроить визуализацию
Что визуализировать хочется? Я не парсил логи микротика, так как они очень разные от разных событий. Под все парсинг писать не захотелось. Мне лично достаточно просто текста логов в elk.
Не один день бьюсь над адекватным фильтром, и не могу понять как заставить заменять ip адреса на DNS с серва гугл например и как это происходит, находил только отдаленные сайты что есть такой дашборд NetFlow но как он ставиться и куда не понял, вообще хотел собрать что-то подобное netflow analyzer, у которого при получение netflow v9 происходил разбор по DNS с рабочими ссылками.
Мне кажется, что elk не подходящий для этого инструмент. Но могу ошибаться. В любом случае, тут не будет готового или простого решения. Нужно самому колхозить по месту. Причем много и упорно :)
Если у вас что-то получится или найдете как, могли бы подсказать ?
Исправьте, пожалуйста:
Закончили настройку logstash. Запускаем его:
# systemctl enable logstash.service
на systemctl start logstash.service
Спасибо, поправил.
Тоже недавно стал изучать ELK. Сейчас стоит версия 6.3.2. По статье очень советую не добавлять реппозитории, а использовать rpm\deb пакеты т.к. при обновлении внезапно может появится новая версия и все ваши индексы будут грустить и находится в потерянном времени, так было со мной, когда с версии 6.3.2 все обновилось до 6.4. Для полного дополнения к статье, надо еще добавить один момент, который все упускают, но вспоминают о нем, спустя месяц или 2 (в зависимости от объема данных). Это очистка данных. В официальной документации рекомендуют использовать curator. ставится командой pip install elasticsearch-curator
далее заводим конфиг /etc/curator
файлик /etc/curator/config.yml
client:
hosts:
- 127.0.0.1: 9200
url_prefix:
use_ssl: False
certificate:
client_cert:
client_key:
ssl_no_validate: True
http_auth:
timeout: 30
master_only: False
logging:
loglevel: INFO
logfile:
logformat: default
blacklist: ['elasticsearch', 'urllib3']
файлик /etc/curator/action.yml
actions:
1:
action: close
description: close indices
options:
delete_aliases: False
timeout_override:
continue_if_exception: True
disable_action: False
filters:
-
filtertype: age
source: name
direction: older
timestring: '%Y.%m.%d'
unit: days
unit_count: 45
exclude:
2:
action: delete_indices
description: delete indices
filters:
-
filtertype: age
source: name
direction: older
timestring: '%Y.%m.%d'
unit: days
unit_count: 50
exclude:
и самое главное
crontab -e
0 0 * * * /usr/local/bin/curator --config /etc/curator/config.yml /etc/curator/action.yml
Не стал в комменте писать, что за что отвечает, при желании есть официальная документация. А то слишком большой будет и меня забанит.
Спасибо за полезную информацию. Про curator я сразу нашел инфу, но до чистки еще не дошел, не накопил объем. А по поводу обновлений грустно. Неужели в версиях нет обратной совместимости со старыми индексами? В таком случае можно просто через yum или apt заблокировать обновления elasticsearch.
Разработчики на сайте предупреждают о том, что индексы могут быть разные и могут быть проблемы, поэтому лучше знать это заранее, пока все это не обросло своими доработками и алерт скриптами. По шаблонам и визуализациям, уверен, что вы пробовали встроенные визуализации которые пишутся на kibana. В общем, чтобы долго не искать, есть хороший способ, на сам сервер ставите например тот же filebeat и потом выполняете команду filebeat setup --dashboards, но по мне, проще рисовать самому и поближе поймешь как это делать и потом становиться интереснее. Поэтому по визуализациям, тот кто поймет какие события для него важны и необходимо собирать статистику, сам нарисует таблицы, диаграммы и пироги которые будут необходимы.
Да, согласен. Я пробовал и смотрел готовые дашборды. Не подошло и не понравилось ничего. Для себя сам нарисовал все с актуальной информацией. На эту тему будут статьи. Одна уже в черновиках, ждет публикации.
Пока что бегло просмотрел, но уже возник такой вопрос - это все настраивается на заранее подготовленном на базе web-сервера nginx, php-fpm, php7 или хватит базовой настройки без поднятия web-сервера?
Web сервер как таковой не нужен. Kibana сама по себе веб сервер. Но для удобства используется Nginx. Php-fpm не нужен вообще. Тут все на яве работает.
а можно ли собирать логи с Микротика?
Конечно можно. Я напишу об этом, как руки дойдут. У меня есть микротики, которые надо завести на elasticsearch. В настоящее время бьюсь над ошибками :) Не так то это просто управлять elasticsearch. Очень много нюансов. Уже несколько раз все индексы удалял, чтобы ошибки исправить.
с нетерпением буду ждать статью
Если сильно хочется, ждать не обязательно. Можно собирать логи в обычные файлы и анализировать filebeat. Как отправлять логи микротика в файл я уже писал - https://serveradmin.ru/mikrotik-logirovanie-na-udalennyiy-server-rsyslog/
По микротику, можно просто добавить в /etc/logstash/conf.d/ файл 02-beats-input-mikrotik.conf с следующим содержанием
input {
tcp {
type => "syslog"
port => 54714
}
}
input {
udp {
type => "syslog"
port => 54714
}
}
порт можете выбрать какой захотите. перезапустиьт logstash. И соответственно на самом микротике указать адрес сервера логов с портов. потом появятся новые индексы. Это простой конфиг, возможно будет желание "попилить" на более мелкие шарды, но для типовых задач: кто в какое время залогинился и что изменил в конфиге, логирование на правила, вполне хватит.
Я, кстати, это себе сделал уже. Пытался как-то распарсить логи через grok, но не получилось. Не занимались подобным?
https://mum.mikrotik.com//presentations/RU16/presentation_3767_1475674607.pdf возможно вы уже видели такую презентацию
Тут мнения разбегаются, кто то любит grok, а кто то ruby, поэтому можно посмотреть в сторону ruby, там нет такой жесткой привязки к выстраиванию выражений.
создал файл с указанными параметрами. в кебана у меня так и не появляется файл логов. все дела по инструкции. только без включения nginx. уже все конфиги пересмотрел - не пойму где затык
/etc/logstash/conf.d/40-output.conf
output {
elasticsearch {
hosts => ["localhost:9200"]
sniffing => true
manage_template => false
index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}
Также проверьте файрвол на те порты которые вы открыли и статус netstat -tulpn, там должен быть открыт порт указанный вами в конфиге для получения логов с микротик. Появится новый индекс и будет вам счастье.
Подскажите в чем может быть проблема?
systemctl restart logstash.service && tail -f /var/log/logstash/logstash-plain.log
[2020-07-02T02:25:28,532][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
[2020-07-02T02:25:33,461][INFO ][logstash.runner ] Logstash shut down.
[2020-07-02T02:25:51,277][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"7.8.0", "jruby.version"=>"jruby 9.2.11.1 (2.5.7) 2020-03-25 b1f55b1a40 OpenJDK 64-Bit Server VM 25.252-b09 on 1.8.0_252-8u252-b09-1~deb9u1-b09 +indy +jit [linux-x86_64]"}
[2020-07-02T02:25:52,621][ERROR][logstash.agent ] Failed to execute action {:action=>LogStash::PipelineAction::Create/pipeline_id:main, :exception=>"LogStash::ConfigurationError", :message=>"Expected one of [ \\t\\r\\n], \"#\", [A-Za-z0-9_-], '\"', \"'\", [A-Za-z_], \"-\", [0-9], \"[\", \"{\" at line 3, column 9 (byte 23) after input {\ntcp {\ntype => ", :backtrace=>["/usr/share/logstash/logstash-core/lib/logstash/compiler.rb:58:in `compile_imperative'", "/usr/share/logstash/logstash-core/lib/logstash/compiler.rb:66:in `compile_graph'", "/usr/share/logstash/logstash-core/lib/logstash/compiler.rb:28:in `block in compile_sources'", "org/jruby/RubyArray.java:2577:in `map'", "/usr/share/logstash/logstash-core/lib/logstash/compiler.rb:27:in `compile_sources'", "org/logstash/execution/AbstractPipelineExt.java:181:in `initialize'", "org/logstash/execution/JavaBasePipelineExt.java:67:in `initialize'", "/usr/share/logstash/logstash-core/lib/logstash/java_pipeline.rb:43:in `initialize'", "/usr/share/logstash/logstash-core/lib/logstash/pipeline_action/create.rb:52:in `execute'", "/usr/share/logstash/logstash-core/lib/logstash/agent.rb:342:in `block in converge_state'"]}
[2020-07-02T02:25:52,956][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
[2020-07-02T02:25:57,842][INFO ][logstash.runner ] Logstash shut down.
[2020-07-02T02:26:15,679][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"7.8.0", "jruby.version"=>"jruby 9.2.11.1 (2.5.7) 2020-03-25 b1f55b1a40 OpenJDK 64-Bit Server VM 25.252-b09 on 1.8.0_252-8u252-b09-1~deb9u1-b09 +indy +jit [linux-x86_64]"}
[2020-07-02T02:26:16,946][ERROR][logstash.agent ] Failed to execute action {:action=>LogStash::PipelineAction::Create/pipeline_id:main, :exception=>"LogStash::ConfigurationError", :message=>"Expected one of [ \\t\\r\\n], \"#\", [A-Za-z0-9_-], '\"', \"'\", [A-Za-z_], \"-\", [0-9], \"[\", \"{\" at line 3, column 9 (byte 23) after input {\ntcp {\ntype => ", :backtrace=>["/usr/share/logstash/logstash-core/lib/logstash/compiler.rb:58:in `compile_imperative'", "/usr/share/logstash/logstash-core/lib/logstash/compiler.rb:66:in `compile_graph'", "/usr/share/logstash/logstash-core/lib/logstash/compiler.rb:28:in `block in compile_sources'", "org/jruby/RubyArray.java:2577:in `map'", "/usr/share/logstash/logstash-core/lib/logstash/compiler.rb:27:in `compile_sources'", "org/logstash/execution/AbstractPipelineExt.java:181:in `initialize'", "org/logstash/execution/JavaBasePipelineExt.java:67:in `initialize'", "/usr/share/logstash/logstash-core/lib/logstash/java_pipeline.rb:43:in `initialize'", "/usr/share/logstash/logstash-core/lib/logstash/pipeline_action/create.rb:52:in `execute'", "/usr/share/logstash/logstash-core/lib/logstash/agent.rb:342:in `block in converge_state'"]}
[2020-07-02T02:26:17,298][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9600}
[2020-07-02T02:26:22,194][INFO ][logstash.runner ] Logstash shut down.
[2020-07-02T02:26:54,268][INFO ][logstash.runner ] Starting Logstash {"logstash.version"=>"7.8.0", "jruby.version"=>"jruby 9.2.11.1 (2.5.7) 2020-03-25 b1f55b1a40 OpenJDK 64-Bit Server VM 25.252-b09 on 1.8.0_252-8u252-b09-1~deb9u1-b09 +indy +jit [linux-x86_64]"}
У вас ошибка в конфиге
ConfigurationError», :message=>»Expected one of [ \\t\\r\\n], \»#\», [A-Za-z0-9_-], ‘\»‘, \»‘\», [A-Za-z_], \»-\», [0-9], \»[\», \»{\» at line 3, column 9 (byte 23) after input
в 3-й строке.
не хочешь обновить статью по ELK Stack (Elastic Kibana)
а то нпифигна не робит, и интерфейс у свежей версии совсем другой..
Вроде есть logstash-input-imap, есть ли опыт сним?
Можно ли каким-то образом сделать чтоб этот стек хранил не логи, а письма. Сейчас у меня почти все системы(UTM, Netwrix, Zabbix ect) отправляют на мой ящик тонны писем. Может можно натравить их на ELK Stack, хранить, парсить, и смотреть там?
Думаю можно, но я не улавливаю, в чем тут смысл? Почему не устраивает классический почтовый ящик?
https://www.elastic.co/guide/en/logstash/current/plugins-inputs-imap.html