
Ранее я уже показывал несколько примеров, как можно использовать мониторинг логов, упрощая себе жизнь. Сегодня я расскажу, как с помощью ELK Stack анализировать работу бэкенда на примере web сервера nginx и php-fpm в качестве бэкенда. Я покажу, как логировать информацию о времени ответа бэкенда, передавать ее в elk stack и потом анализировать.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном онлайн-курcе по администрированию MikroTik. Автор курcа – сертифицированный тренер MikroTik Дмитрий Скоромнов. Более 40 лабораторных работ по которым дается обратная связь. В три раза больше информации, чем в MTCNA.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Содержание:
Введение
Схема работы будет следующая:
- Настраиваем в nginx логирование времени ответа бэкенда с помощью переменной $upstream_response_time из параметров логирования.
- Передаем лог nginx в elk stack.
- Создаем визуализации и дашборд для удобного анализа логов.
Прежде чем двигаться дальше, вам необходимо ознакомиться со статьей по установке и настройке elk stack. Руководствуясь статьей, вам следует настроить сам сервер elk stack и сбор логов nginx на этот сервер. Подобный пример как раз рассмотрен в статье. После этого можно приступать к дальнейшим действиям.
Настройка nginx для мониторинга бэкенда
На web сервере nginx нам нужно выполнить несколько подготовительных действий. Во-первых, добавляем дополнительный log_format, который будет собирать полезную информацию, помимо той, что используется в дефолтной настройке. Я предлагаю сразу максимально полный формат, который я называю full и обычно использую. Для этого в /etc/nginx/nginx.conf в раздел http добавляем новый формат лога.
log_format full '$remote_addr - $host [$time_local] "$request" '
'request_length=$request_length '
'status=$status bytes_sent=$bytes_sent '
'body_bytes_sent=$body_bytes_sent '
'referer=$http_referer '
'user_agent="$http_user_agent" '
'upstream_status=$upstream_status '
'request_time=$request_time '
'upstream_response_time=$upstream_response_time '
'upstream_connect_time=$upstream_connect_time '
'upstream_header_time=$upstream_header_time';
Здесь много дополнительной информации, которая может быть полезна для анализа. В данной статье я буду анализировать только время ответа бэкенда - upstream_response_time. Если вам интересны какие-то еще значения, можете их добавлять по аналогии.
Далее идем в виртуальный хост, за которым будем следить и правим его настройки. Я не буду приводить полный конфиг виртуального хоста. Покажу только те параметры, которые нас интересуют в рамках заданной темы.
Задаем формат лога виртуального хоста:
access_log /web/sites/serveradmin.ru/logs/access.log full;
Далее я всю статику добавляю в отдельный location и отключаю для него лог. Доступ к этим файлам мне нет необходимости логировать:
location ~* ^.+.(js|css|png|jpg|jpeg|gif|ico|woff|woff2|swf|ttf|svg)$ {
access_log off;
expires 1y;
add_header Cache-Control public;
}
В отдельный location добавляю php запросы, которые как раз и будут попадать в лог.
location ~ \.php$ {
fastcgi_pass unix:/var/run/php-fpm/php-fpm.sock;
......
}
Перечитывайте конфигурацию nginx и проверяйте лог виртуального хоста. Там должно быть примерно следующее:
5.45.207.63 - serveradmin.ru [05/Jan/2019:17:18:35 +0300] "GET /ustanovka-synology-os-na-obyichnyiy-kompyuter-hp-proliant-n54l-microserver/synology/ HTTP/1.1" request_length=302 status=200 bytes_sent=21246 body_bytes_sent=20644 referer=- user_agent="Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)" upstream_status=200 request_time=0.407 upstream_response_time=0.407 upstream_connect_time=0.000 upstream_header_time=0.401 207.46.13.33 - serveradmin.ru [05/Jan/2019:17:21:22 +0300] "GET /obnovlenie-chasovogo-poyasa-v-xenserver-6-5/ HTTP/1.1" request_length=281 status=200 bytes_sent=23846 body_bytes_sent=23244 referer=- user_agent="Mozilla/5.0 (compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm)" upstream_status=200 request_time=0.397 upstream_response_time=0.396 upstream_connect_time=0.000 upstream_header_time=0.390 5.45.207.63 - serveradmin.ru [05/Jan/2019:17:22:14 +0300] "GET /forum/astersik/ustanovka-free-pbx-13-na-sentos-7/ HTTP/1.1" request_length=267 status=200 bytes_sent=35598 body_bytes_sent=34756 referer=- user_agent="Mozilla/5.0 (compatible; YandexBot/3.0; +http://yandex.com/bots)" upstream_status=200 request_time=0.446 upstream_response_time=0.446 upstream_connect_time=0.000 upstream_header_time=0.435
Если у вас примерно так же, можно двигаться дальше. Смысл в том, что в логе должен быть параметр upstream_response_time и какое-то временное значение в секундах. Обычно меньше секунды, но это зависит от быстродействия бэкенда, за которым мы как раз и будем следить.
Grok фильтр logstash для парсинга лога
Следующим шагом по настройке мониторинга ответа бэкенда является создание grok фильтра для logstash. Приведенный выше формат лога я парсю следующим grok фильтром. Привожу сразу весь конфиг logstash, который за него отвечает:
filter {
if [type] == "nginx_access" {
grok {
match => { "message" => "%{IPORHOST:remote_ip} - %{DATA:virt_host} [%{HTTPDATE:access_time}] \"%{WORD:http_method} %{DATA:url} HTTP/%{NUMBER:http_version}\" request_length=%{INT:request_length} status=%{INT:status} bytes_sent=%{INT:bytes_sent} body_bytes_sent=%{NUMBER:body_bytes_sent} referer=%{DATA:referer} user_agent=\"%{DATA:user_agent}\" upstream_status=%{DATA:upstream_status} request_time=%{NUMBER:request_time} upstream_response_time=%{DATA:upstream_response_time} upstream_connect_time=%{DATA:upstream_connect_time} upstream_header_time=%{DATA:upstream_header_time}" }
overwrite => [ "message" ]
}
mutate {
convert => ["bytes_sent", "integer"]
convert => ["body_bytes_sent", "integer"]
convert => ["request_length", "integer"]
convert => ["request_time", "float"]
convert => ["upstream_status", "integer"]
convert => ["upstream_response_time", "float"]
convert => ["upstream_connect_time", "float"]
convert => ["upstream_header_time", "float"]
}
ruby {
code => 'event.set("request_time_ms",event.get("request_time")*1000)'
}
date {
match => [ "access_time" , "dd/MMM/YYYY:HH:mm:ss Z" ]
remove_field => [ "access_time" ]
}
geoip {
source => "remote_ip"
target => "geoip"
add_tag => [ "nginx-geoip" ]
}
}
Привожу конфиг с рабочего сервера, который настраивал достаточно давно. Здесь выполняются следующие действия:
- grok фильтр парсит строки лога
- mutate конвертирует некоторые числовые поля в нужный формат, чтобы потом было удобнее работать
- ruby фильтр добавляет новое поле request_time_ms просто умножая значение из существующего request_time на 1000. Это делается для более удобной визуализации значений. Целые числа более наглядны для визуализации
- фильтр date берет время из поля access_time и использует его как время поступления лога в систему, заменяя @timestamp. Затем это поле удаляет, так как оно становится не нужно. Делается это для того, чтобы использовать только время из лога nginx, чтобы не было путаницы, когда порядок отправки логов по какой-то причине будет нарушен
- geoip фильтр используется для построения гео карты. Об этом я отдельно рассказывал в статье по настройке дашборда для nginx
Перезапускайте logstash и идите в Kibana проверять поступление логов в указанном формате. Если все сделали правильно, то должно получиться примерно следующее:
Дашборд с временем ответа бэкенда
По сути вся настройка за мониторингом бэкенда сделана. Логи в нужном формате поступают в elasticsearch. Осталось только визуализировать их. Тут каждый может сделать так, как больше нравится ему. Я предложу свой вариант визуализации, но сразу скажу, что он меня не очень устраивает, но лучше не придумал сходу, а потом стало не очень актуально. Все, что надо, видно, а акцента на мониторинг работы web сервера я не делал.
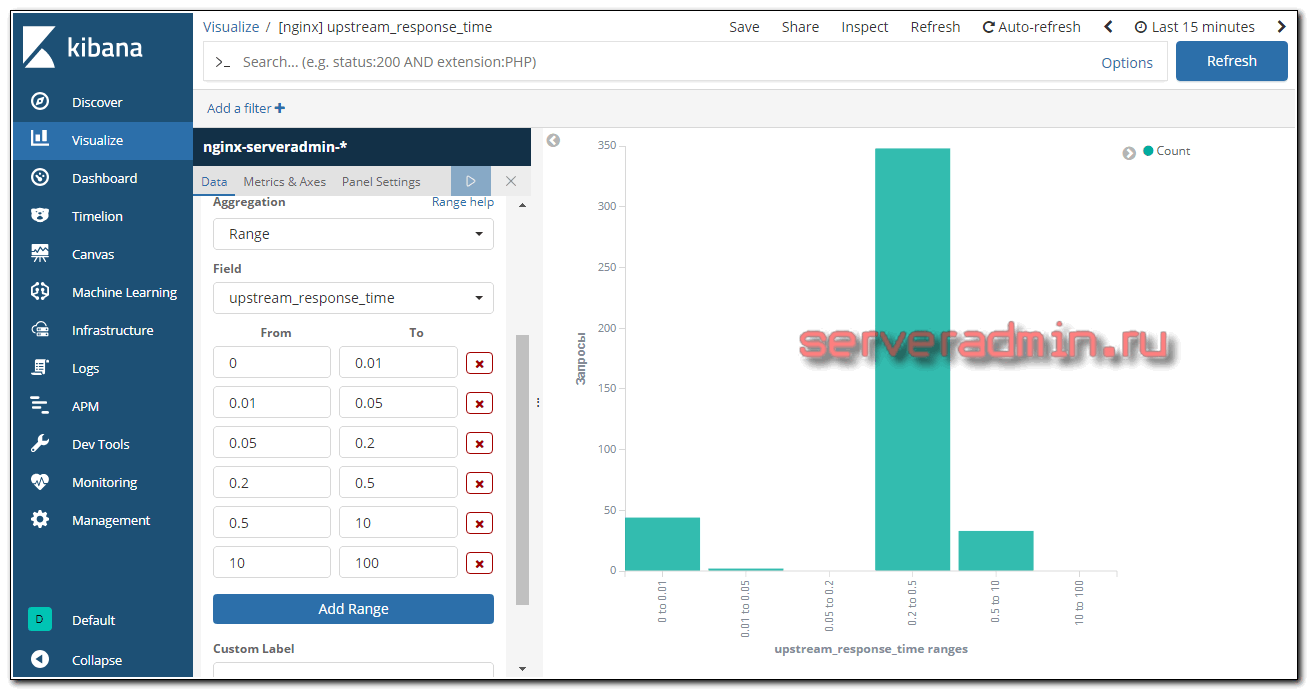
Первая визуализация для upstream_response_time. Все запросы я разбил на несколько интервалов и вывел отдельно каждый интервал в столбец. Получилось примерно так:
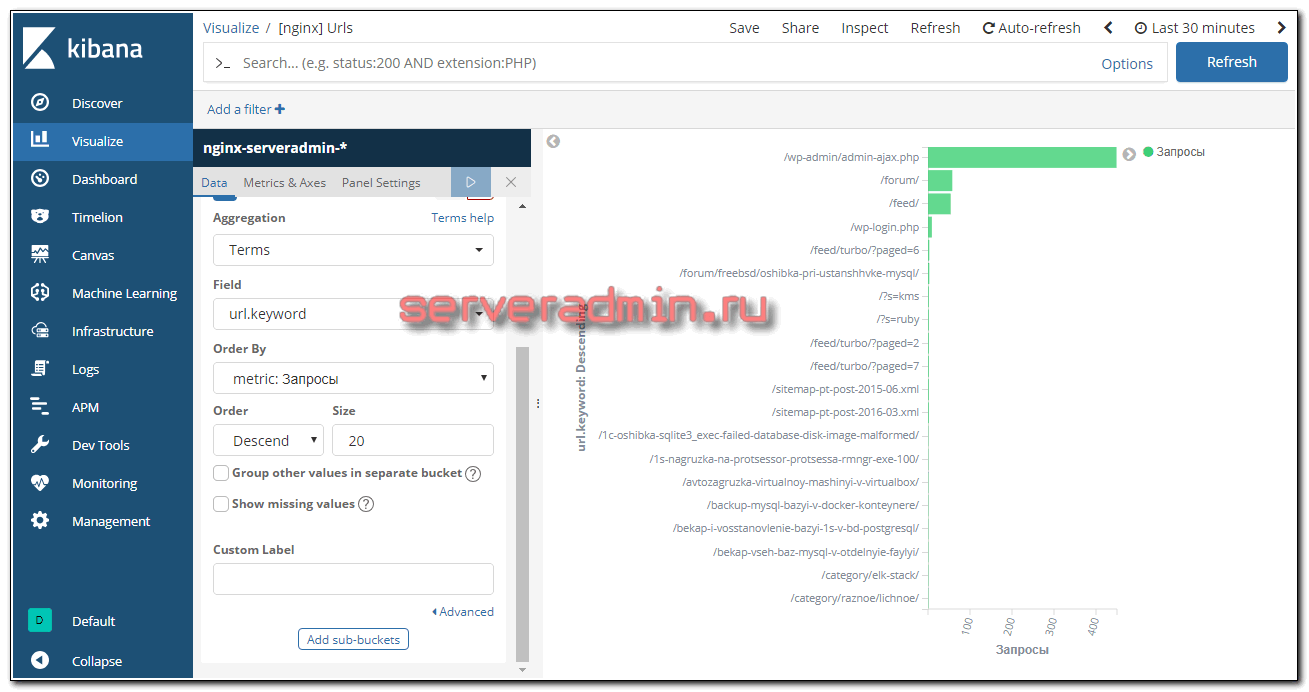
Следующая визуализация показывает адреса запросов. Иногда эта картинка ломается, если какой-то запрос очень длинный и не помещается на экран. Не придумал, что с этим делать.
В следующей визуализации построил график на основе request_time. Напомню, что этот параметр я как раз умножал на 1000, чтобы получились целые значения. С ними нагляднее. Получилось вот так.
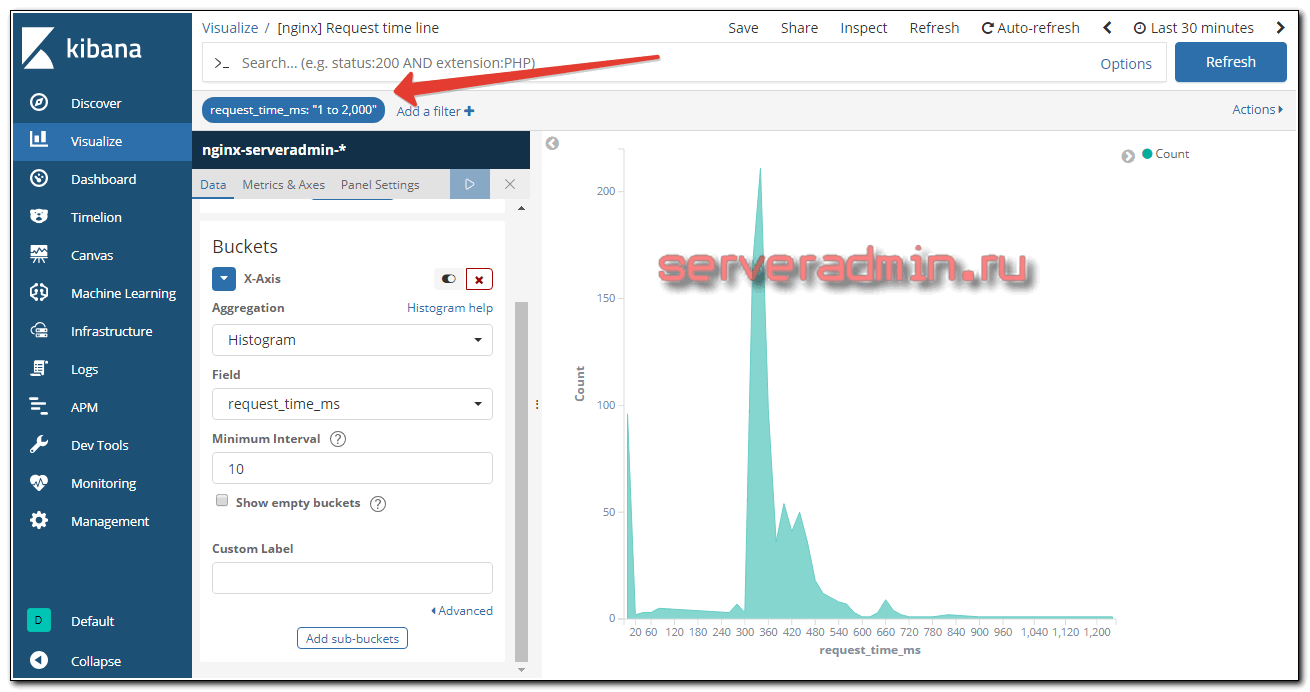
Обращаю внимание, что хвост я ограничил длиной в 2 секунды. Если этого не сделать, то отдельные очень длинные запросы растягивают график. Его становится неудобно анализировать. Вы подгоните этот параметр под свои условия работы. Возможно, вам нужен будет хвост длиннее, а может короче.
Отдельную визуализацию сделал для типов запросов.
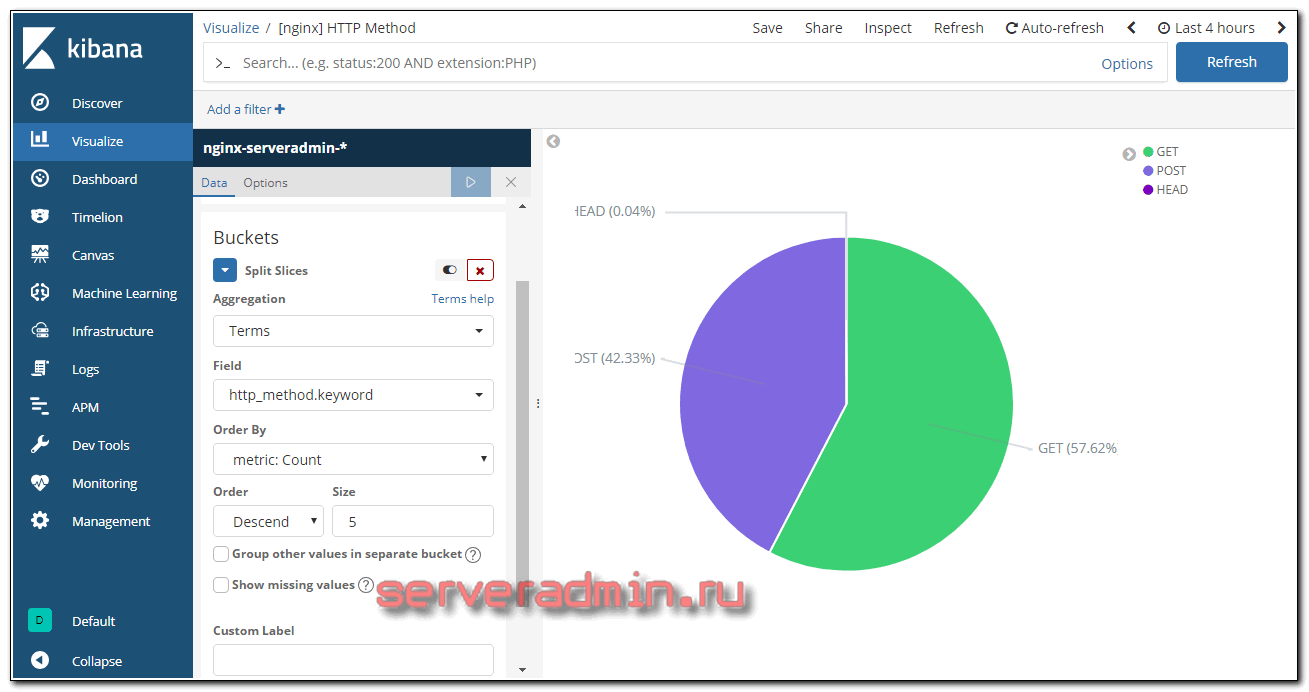
Вот и все. Под графиками идет список самих логов. Весь дашборд получился таким:
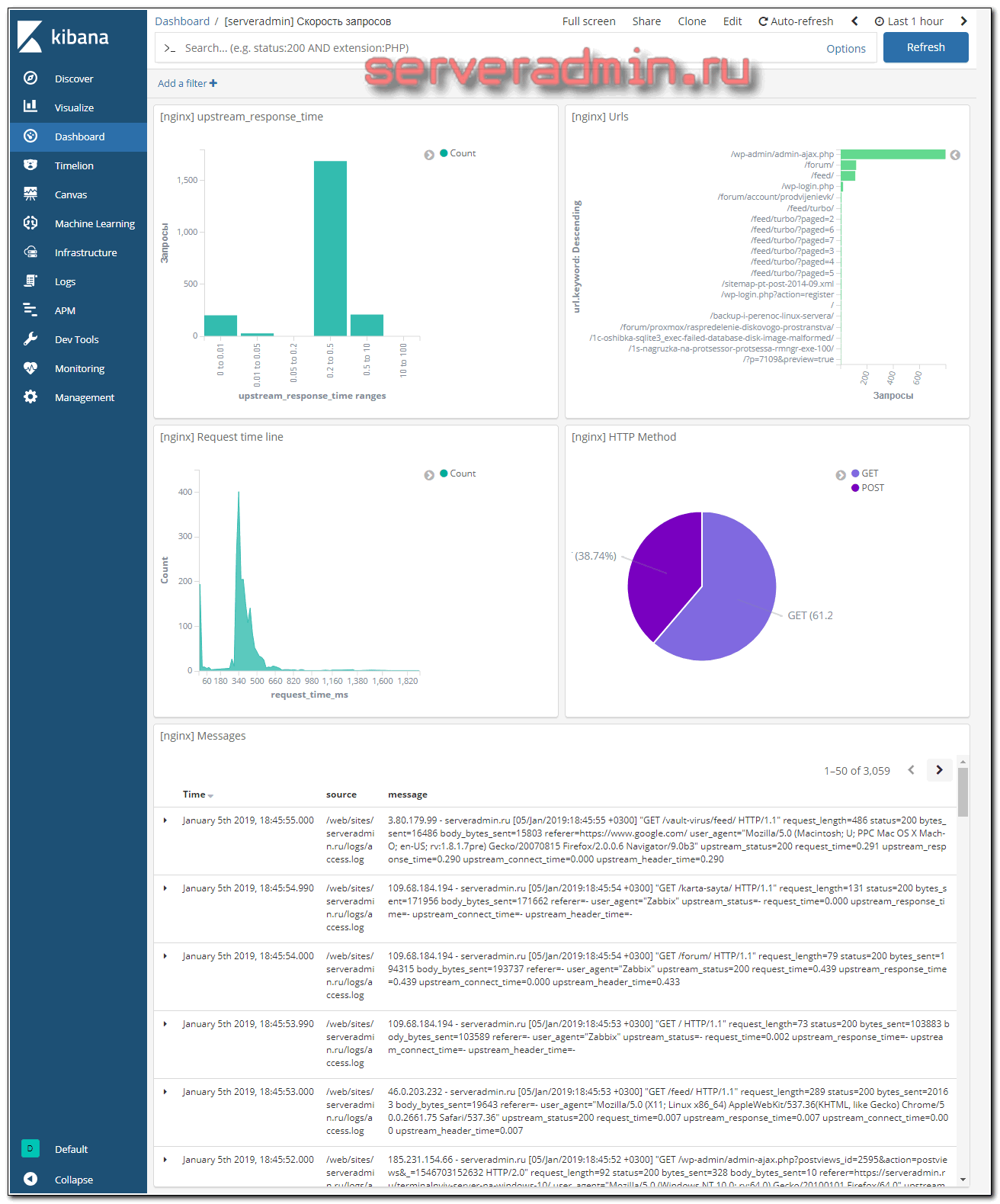
Смотреть не очень удобно, потому что пишу статью на ноутбуке с низким разрешением. Смотреть лучше на большом мониторе.
Заключение
Подобного дашборда вполне достаточно, чтобы беглым взглядом оценить производительность сервера и проверить медленные запросы. В связке с общим дашбордом nginx анализ производительности web сервера выполнять очень удобно. Приведу пример того, как обычно действую я.
Я получаю уведомления от zabbix о том, что превышен средний трафик за интервал времени или высокая нагрузка на процессор. Открываю основной дашборд и сразу же анализирую, не спамит ли какой-то конкретный ip запросами. Далее смотрю по каким урлам идут запросы, есть ли ошибки web сервера.
Если все ок и нет явных нарушителей и ошибок, то смотрю на производительность сервера и время ответа бэкенда. Если в целом все нормально, не выходит за средние значения, значит все в порядке и высокая нагрузка не является проблемой в данный момент.
Заходить на сам web сервер по ssh и смотреть вручную логи нет необходимости. Это существенно экономит время. Не хватает только оповещений из elk stack по превышению каких-то пороговых значений, например количество пятисотых ошибок сервера.
Если грамотно настроить мониторинг логов с помощью elk stack, посадить за систему можно обычного оператора, не системного администратора. Весь первичный анализ он сможет сделать сам и составить подробный тикет для техподдержки с описанием проблемы. Либо можно отдать систему программисту, который будет очень рад возможности смотреть логи не бегая на сервер по ssh.
Получилась система из разряда must have для более ли менее серьезного web сервера. Я сейчас уже не представляю, как без нее администрировать веб сервер. По каждому инциденту надо лезть по ssh и смотреть, что случилось. Обычного мониторинга zabbix не достаточно. В elk stack можно настроить все, что угодно, вывести любые данные, которые актуальны для твоего проекта.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном онлайн-курcе по администрированию MikroTik. Автор курcа – сертифицированный тренер MikroTik Дмитрий Скоромнов. Более 40 лабораторных работ по которым дается обратная связь. В три раза больше информации, чем в MTCNA.
Реклама ИП Скоромнов Д.А. ИНН 331403723315

добрый день! не получается вывести в графике среднее значение времени между запросом и ответом. кто нить пробовал подобное?
Что конкретно не получается? У вас в логах есть эта информация? Парсинг нормально проходит?
Прогнал пример через https://grokdebug.herokuapp.com/. Почему-то значение в самом последнем поле пустое. Почему?
"upstream_header_time": [
[
""
]
]
}
В grok-фильтре ошибка, отсутсвует бэкслэш перед [%{HTTPDATE:access_time}]. Должно быть так \[%{HTTPDATE:access_time}]
Добрый день! хотел спросить у меня dotnet log сохраняет json format как его logstash оправит через filebeat
Точно так же. Если не нужна предобрадотка, то просто как обычную строку отправляете в logstash. Если хотите как-то обрабатывать, то есть фильтр для этого - https://www.elastic.co/guide/en/logstash/current/plugins-filters-json.html
Добрый день! вот мой конфиг файлы
1 client filebeat.yml
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/*_access.log
fields:
type: nginx_access
fields_under_root: true
scan_frequency: 5s
- type: log
enabled: true
paths:
- /var/log/nginx/*_error.log
fields:
type: nginx_error
fields_under_root: true
scan_frequency: 5s
- type: log
enabled: true
paths:
- /var/log/audit/audit.log
fields_under_root: true
fields:
type: linux_audit_logs
- type: log
enabled: true
paths:
- /var/log/audit/secure
- /var/log/messages
fields_under_root: true
fields:
type: linux_system_logs
- type: log
paths:
- /var/log/dotnet/log_prod.json
json:
tags: ["dotnet", "json"]
json:
keys_under_root: true
add_error_key: true
output.logstash:
hosts: ["logstash1.lan:5045", "logstash2.lan:5045"]
loadbalance: true
logstash
input.conf
# vi conf.d/logstash.conf
input {
beats {
port => 5044
}
beats {
port => 5045
#codec => "json"
}
}
filter {
json {
source => "message"
}
}
output {
if [type] == "dotnet" {
elasticsearch {
hosts => ["http://test1.lan:9200", "http://test2.lan:9200", "http://test3.lan:9200"]
index => "dotnet-%{+YYYY.MM.dd}"
}
}
}
index не появляется на кибане
Добрый день. Спасибо за статью. Попытался реализовать у себя ваше решение и наткнулся на ошибку
The given configuration is invalid. Reason: Expected one of [ \t\r\n], "#", "=>" at line 35, column 5
это именно строка где начинается фильтр
filter {
if [type] == "nginx_access" {
Что означает ошибка я знаю, но при этом валидатор переваривает конфиг как валидный.
Вопрос, как бы вы объединили input filter и output в одном отдельном файле конфигурации для этого решения "Мониторинг производительности бэкенда"?
Добрый
Есть еще такой проект https://habr.com/ru/company/yamoney/blog/436512/
Оч. неплохой ресурс по ELK https://logz.io/learn/complete-guide-elk-stack/
Спасибо за последнюю ссылку. Очень крутой сайт по теме, много полезной информации, которой раньше не видел.
Доброго.
Алертинг для ELK
github.com/Yelp/elastalert
github.com/bitsensor/elastalert-kibana-plugin
А можно ли каким-то образом запилить сюда тригеры на оповещение?
Как-то можно. Я не прорабатывал этот вопрос.