
Поймал несколько раз ошибку в работе связки logstash + elasticsearch. Выражается в том, что данные не поступают в определенный индекс. Самое просторе решение - удалить индекс и создать заново. Данные начнут поступать. Если вас не устраивает решение с удалением индекса, то читайте дальше.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном онлайн-курcе по администрированию MikroTik. Автор курcа – сертифицированный тренер MikroTik Дмитрий Скоромнов. Более 40 лабораторных работ по которым дается обратная связь. В три раза больше информации, чем в MTCNA.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Полностью ошибка в логе logstash выглядит следующим образом:
[INFO ][logstash.outputs.elasticsearch] retrying failed action with response code: 403 ({"type"=>"cluster_block_exception", "reason"=>"blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"})
Получил я ее несколько раз, когда оставалось очень мало свободного места на диске с данными elasticsearch. При достижении примерно 5% свободного места, данные переставали поступать в elasticsearch и появлялась эта ошибка. Исправить ее можно следующим образом. Во первых, перенести данные на более емкий диск или почистить его. Потом идем в Kibana -> Dev Tools и выполняем команду:
PUT weblogs-2018.09.10/_settings
{
"index": {
"blocks": {
"read_only_allow_delete": "false"
}
}
}
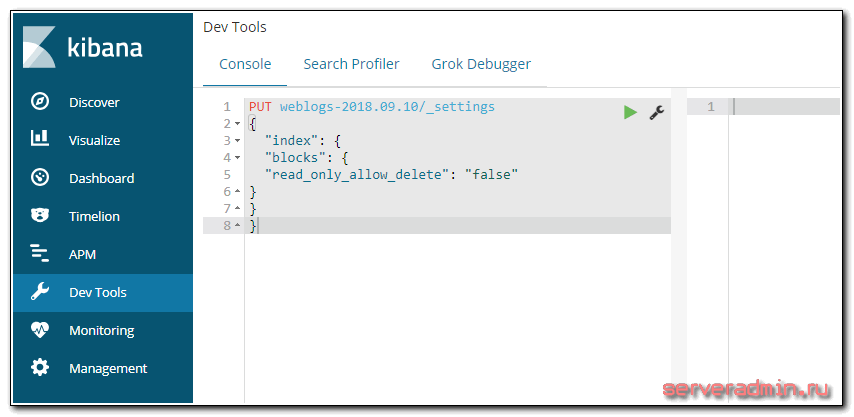
weblogs-2018.09.10 - имя индекса, куда не шли данные. После выполнения команды перезапустил logstash на сервере и данные пошли в текущий индекс.
Скорее всего для записи будут недоступны и системные индексы. Проверьте, какие у вас используются. Точно должен быть .kibana. Если используете мониторинг, то для него тоже свои системные индексы создаются. Они тоже могут быть заблокированы для записи.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном онлайн-курcе по администрированию MikroTik. Автор курcа – сертифицированный тренер MikroTik Дмитрий Скоромнов. Более 40 лабораторных работ по которым дается обратная связь. В три раза больше информации, чем в MTCNA.
Реклама ИП Скоромнов Д.А. ИНН 331403723315

Так происходит из за переполнения жёсткого диска.
https://stackoverflow.com/a/50609418/15045248
Так я же об этом и написал :) Сам словил ошибку от переполнения диска.
Добрейшего утреца всем!
Ребят а у меня эта ошибка возникает при сохранении визуализации на боевом!
На тестовом всё прекрасно все работает даже с учетом того что мало места всего 15 пи поднял в виртуалке .
Может кто нибудь оказать посильную помощь?
Спасибо!
А куратор может как то в этом помочь при отчистке данных с elasticsearch ?
Проблема в том, что данных за сутки собирает более 30 гигов по индексу (Storage size). Уже и на циске оставил только ip flow ingress. Один черт льет просто гигабайты данных. А задача дергать топ 20 ip по загрузке день/неделя/месяц. Даже не знаю что и делать + еще и эта проблема с тем что индекс не отрабатывает.
Куратор конечно может помочь. Он этим и занимается. Закрывает и удаляет старые индексы. Рассчитайте дневное использование, сравните с объемом хранилища и настройте чистку с запасом. Но если льется очень много данных, то рекомендую подумать над тем, как этот поток сократить. В elasticsearch лучше лить как можно меньше, все лишнее отсекая до него. Он очень прожорлив до ресурсов и начинает сильно тормозить, когда много данных.
Так как избежать данной ситуации ?
Следить, чтобы на разделе, где хранятся базы elasticsearch место не заканчивалось.
Спасибо большое.
Может кто знает, почему это могло приключиться, и как избежать этого в будущем?
Плохо читал статью (
Добрый день!
Можно выполнить команду для всех индексов:
PUT _all/_settings { "index": { "blocks": { "read_only_allow_delete": "false" } } }Вместо false можно использовать null.
В документации к Elasticsearch расписано более подробно и есть второй вариант решения данной проблемы:
https://www.elastic.co/guide/en/elasticsearch/reference/6.4/disk-allocator.html
Спасибо за полезную информацию.