
У меня износились в очередной раз SSD диски на одном из железных серверов. В связи с этим решил сделать заметку на эту тему, используя наглядный пример. С SSD дисками до сих пор куча вопросов в плане надежности и мониторинга износа. У каждого вендора SSD свои метрики в SMART, так что не мудрено и запутаться. Поделюсь той информацией, что есть у меня.
На углубленном курсе "Архитектура современных компьютерных сетей" вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Заметка будет краткой с информацией только по существу. Для начала, как я мониторю диски. За основу взят шаблон для Zabbix - zbx-smartctl. У меня есть статья на тему мониторинга SMART в Zabbix. Но там используется другой шаблон, не такой функциональный. Да и в целом статья слегка устарела, но ее можно использовать для теоретической подготовки. За основу рекомендую сразу взять шаблон из первой ссылки.
Важное замечание. Из-за того, что у разных вендоров разные метрики, отвечающие за жизнеспособность SSD, слепо доверять приведенному шаблону нельзя. Он в целом хорошо работает на всех дисках, кроме метрики износа ssd. На каких-то дисках он вообще не работает. На каких-то параметр SSD wearout не уменьшается с 100 до 0, а наоборот растет с 0 до 100, соответственно, надо изменить триггеры.
В общем, шаблон нужно допиливать по месту и обязательно проверять вручную все метрики и триггеры. На одном из серверов, где все это проделано, у меня сработал триггер на SSD wearout. Я зашел в метрики диска и убедился, что диск реально изношен.
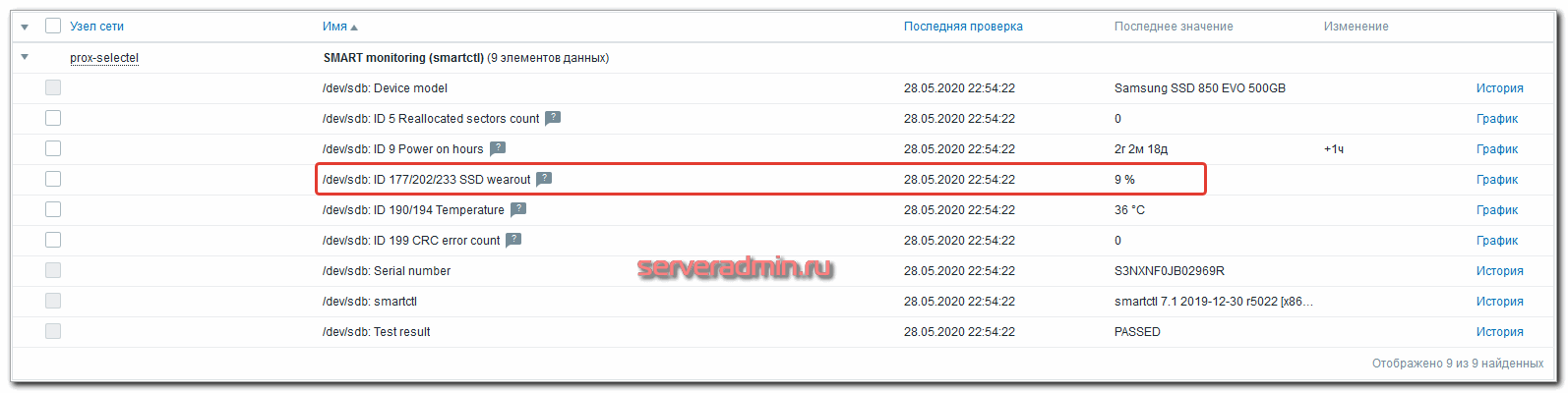
Косвенный признак наработанных часов подтверждает, что диск реально старый и скорее всего подходит конец срока его службы. Для того, чтобы убедиться в этом, идем в консоль и глазами проверяем смарт ssd диска:
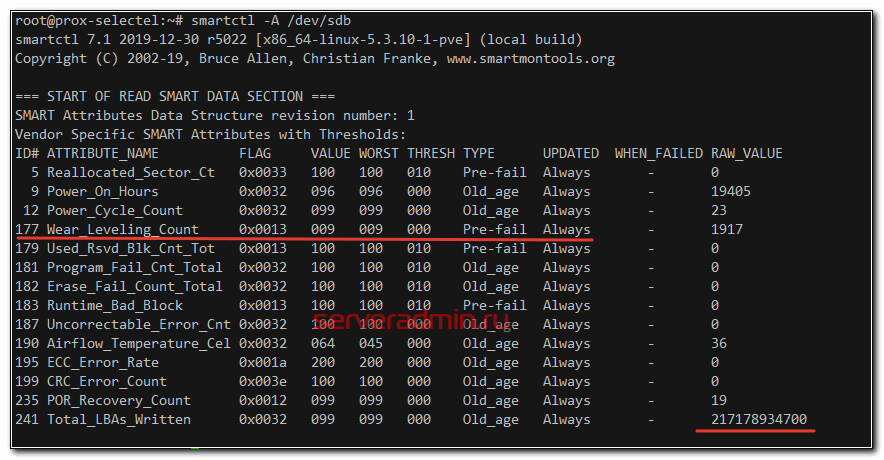
Обращаю внимание на параметр Total_LBAs_Written. Для того, чтобы его правильно интерпретировать, нам надо узнать размер сектора диска, так как показывает он именно их число.
# smartctl /dev/sdb --all | grep "Sector Size" Sector Size: 512 bytes logical/physical
Теперь идем на TLB Calculator и смотрим количество перезаписей диска.
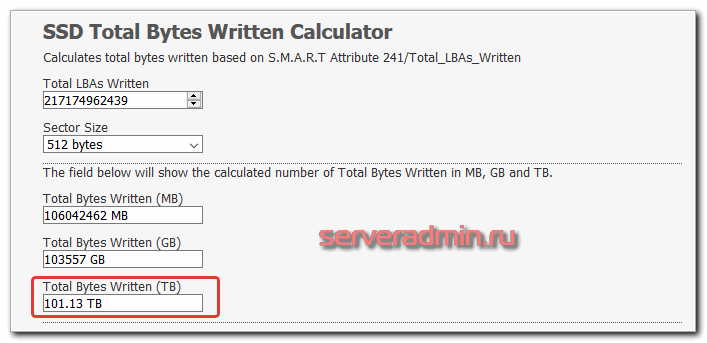
Износ SSD диска подтверждается. Хотя по документам Samsung SSD 850 EVO 500GB способен записать 150TBW, рисковать мне не хочется. К тому же сервер арендуется и тех поддержка без проблем заменит изношенный диск. Главное, чтобы они поменяли тот диск.
После этой истории, если сервер критичный, я не делаю замену диска. Я прошу через тех. поддержку дать подменный сервер, чтобы переехать на него. Обычно идут на встречу. По крайней мере в Selectel. Дают бонусы, чтобы запустить новый сервер на день. После переноса пишу в тех поддержку и они переводят новый сервер на основной тариф, а старый выключают и забирают.
Такая процедура мне видится более прогнозируемой, надежной и быстрой, нежели замена диска. Я не знаю точно, как наливали систему на диск, какие настройки биоса. Загрузится ли система с новым чистым диском, есть ли на втором диске рабочий загрузчик и т.д. В общем, много подводных камней. Гораздо надежнее перенести виртуалки на новый сервер, пока у тебя старый еще работает.
На углубленном курсе "Архитектура современных компьютерных сетей" вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315

спасибо
Добрый.
Аппаратный рейд уходит на свалку истории. При мощностях современных CPU программный заменяет его на 99%.
Кстати, на Хабре появилась статья о грядущем dRAID в ZFS )
Владимир, спасибо за полезную заметку! Подскажте, я правильно понимаю, что для корректной работы smartctl диски не должны быть в RAID`е? Если да, то как вы обычно поступаете с мониторингом износа, если на сервере или СХД используется аппаратный RAID-контроллер?
Износ никак не промониторить, если raid контроллер не передает информацию от smart. Кто-то умеет это делать, кто-то нет. Приходится рассчитывать только на информацию о состоянии рейд массивов, которую передает сам контроллер.