
Мне показалась полезной одна из статей официального блога Zabbix на тему размера базы данных. Решил ее перевести и поделиться с вами. Она будет более предметным дополнением к уже существующей моей статье на схожу тему - Очистка, оптимизация, настройка mysql базы Zabbix. Их бы по хорошему объединить в одну, но в рамках ведения блога это не всегда просто и удобно сделать.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном онлайн-курcе по администрированию MikroTik. Автор курcа – сертифицированный тренер MikroTik Дмитрий Скоромнов. Более 40 лабораторных работ по которым дается обратная связь. В три раза больше информации, чем в MTCNA.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Введение
Оригинал статьи, которую я буду переводить - https://blog.zabbix.com/what-takes-disk-space/13349/. Она отвечает на следующие вопросы:
- Какие таблицы самые больше в базе данных Zabbix
- Что за данные, занимающие больше всего места, поступают на сервер мониторинга
- Каких данных больше всего, находящихся внутри одной partition в базе
- Как посмотреть, какие хосты и айтемы занимают больше всего места в базе данных Zabbix
Если у вас еще нет своего сервера для мониторинга, то рекомендую материалы на эту тему. Для тех, кто предпочитает систему CentOS:
То же самое на Debian 10, если предпочитаете его:
Самые большие таблицы в бд zabbix
Следующие таблицы занимают больше всего места в базе данных:
| history | history_str | |
| history_uint | history_text | events |
| history_log |
- history хранит десятичные числа
- history_uint - целые
- history_str, history_text, history_log - текстовые данные
- events - всевозможные события: проблемы, внутренние события, события авторегистрации и автообнаружения
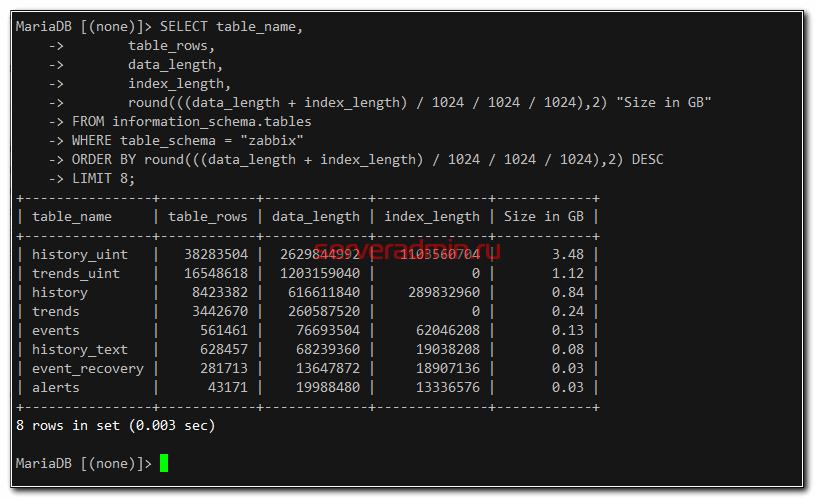
Посмотреть в базе Mysql, какая из таблиц занимает больше всего места можно следующим образом:
SELECT table_name,
table_rows,
data_length,
index_length,
round(((data_length + index_length) / 1024 / 1024 / 1024),2) "Size in GB"
FROM information_schema.tables
WHERE table_schema = "zabbix"
ORDER BY round(((data_length + index_length) / 1024 / 1024 / 1024),2) DESC
LIMIT 8;
И то же самое в PostgreSQL:
SELECT *, pg_size_pretty(total_bytes) AS total , pg_size_pretty(index_bytes) AS index ,
pg_size_pretty(toast_bytes) AS toast , pg_size_pretty(table_bytes) AS table
FROM (SELECT *, total_bytes-index_bytes-coalesce(toast_bytes, 0) AS table_bytes
FROM (SELECT c.oid,
nspname AS table_schema,
relname AS table_name ,
c.reltuples AS row_estimate ,
pg_total_relation_size(c.oid) AS total_bytes ,
pg_indexes_size(c.oid) AS index_bytes ,
pg_total_relation_size(reltoastrelid) AS toast_bytes
FROM pg_class c
LEFT JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE relkind = 'r' ) a) a;
Узнаем, откуда больше всего данных приходит в данный момент

Для того, чтобы узнать, кто за последние 30 минут больше всего пишет в конкретную таблицу базы данных, можно использовать следующий запрос:
use zabbix; SELECT hosts.host,items.itemid,items.key_, COUNT(history_log.itemid) AS 'count', AVG(LENGTH(history_log.value)) AS 'avg size', (COUNT(history_log.itemid) * AVG(LENGTH(history_log.value))) AS 'Count x AVG' FROM history_log JOIN items ON (items.itemid=history_log.itemid) JOIN hosts ON (hosts.hostid=items.hostid) WHERE clock > UNIX_TIMESTAMP(NOW() - INTERVAL 30 MINUTE) GROUP BY hosts.host,history_log.itemid ORDER BY 6 DESC LIMIT 1\G
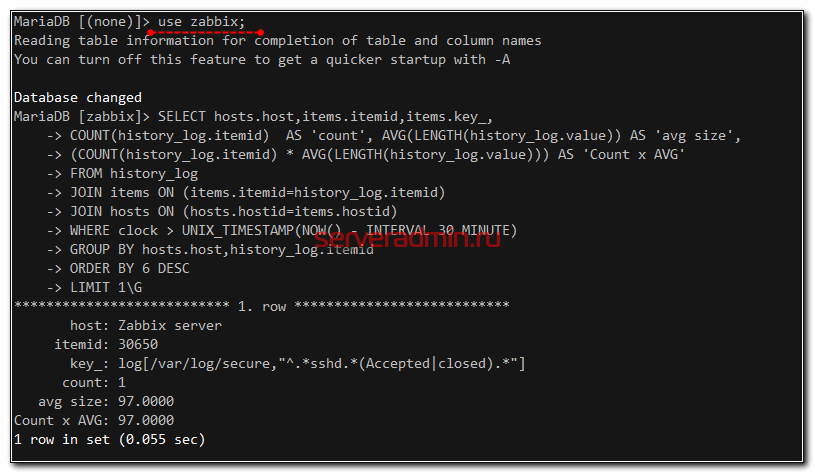
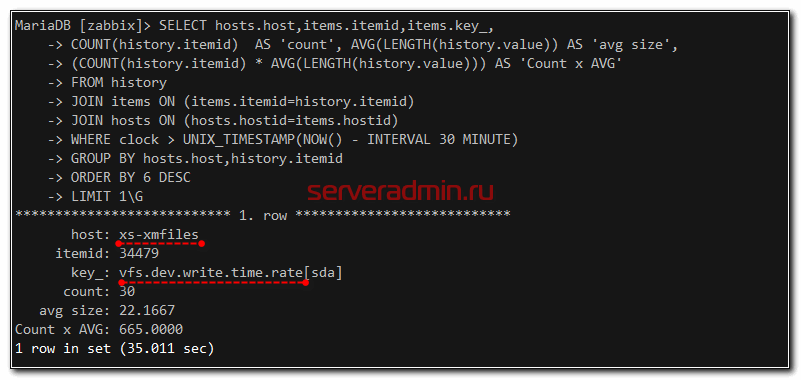
В моем примере это log файл secure, в который стекается информация об ssh подключениях. Она пишется в history_log. Если возьмете интервал побольше, то возможно там будет уже другой айтем. Для того, чтобы посмотреть информацию о числовых метриках, используйте другую таблицу, например history.
SELECT hosts.host,items.itemid,items.key_, COUNT(history.itemid) AS 'count', AVG(LENGTH(history.value)) AS 'avg size', (COUNT(history.itemid) * AVG(LENGTH(history.value))) AS 'Count x AVG' FROM history JOIN items ON (items.itemid=history.itemid) JOIN hosts ON (hosts.hostid=items.hostid) WHERE clock > UNIX_TIMESTAMP(NOW() - INTERVAL 30 MINUTE) GROUP BY hosts.host,history.itemid ORDER BY 6 DESC LIMIT 1\G
То же самое, для PostgreSQL:
SELECT hosts.host,history_log.itemid,items.key_, COUNT(history_log.itemid) AS "count", AVG(LENGTH(history_log.value))::NUMERIC(10,2) AS "avg size", (COUNT(history_log.itemid) * AVG(LENGTH(history_log.value)))::NUMERIC(10,2) AS "Count x AVG" FROM history_log JOIN items ON (items.itemid=history_log.itemid) JOIN hosts ON (hosts.hostid=items.hostid) WHERE clock > EXTRACT(epoch FROM NOW()-INTERVAL '30 MINUTE') GROUP BY hosts.host,history_log.itemid,items.key_ ORDER BY 6 DESC LIMIT 5 \gx
Какие хосты занимают больше всего места
Для того, чтобы подсчитать занимаемое место конкретным хостом, необходимо запустить очень тяжелый запрос. Для начала лучше попробовать на небольшой таблице и небольшом интервале. В следующем примере мы переместимся на сутки назад и проверим поступление данных в течении 60 минут в таблицу history_text.
SELECT ho.hostid, ho.name, count(*) AS records, (count(*)* (SELECT AVG_ROW_LENGTH FROM information_schema.tables WHERE TABLE_NAME = 'history_text' and TABLE_SCHEMA = 'zabbix')/1024/1024) AS 'Total size average (Mb)', sum(length(history_text.value))/1024/1024 + sum(length(history_text.clock))/1024/1024 + sum(length(history_text.ns))/1024/1024 + sum(length(history_text.itemid))/1024/1024 AS 'history_text Column Size (Mb)' FROM history_text LEFT OUTER JOIN items i on history_text.itemid = i.itemid LEFT OUTER JOIN hosts ho on i.hostid = ho.hostid WHERE ho.status IN (0,1) AND clock > UNIX_TIMESTAMP(now() - INTERVAL 1 DAY - INTERVAL 60 MINUTE) AND clock < UNIX_TIMESTAMP(now() - INTERVAL 1 DAY) GROUP BY ho.hostid ORDER BY 4 DESC LIMIT 5\G
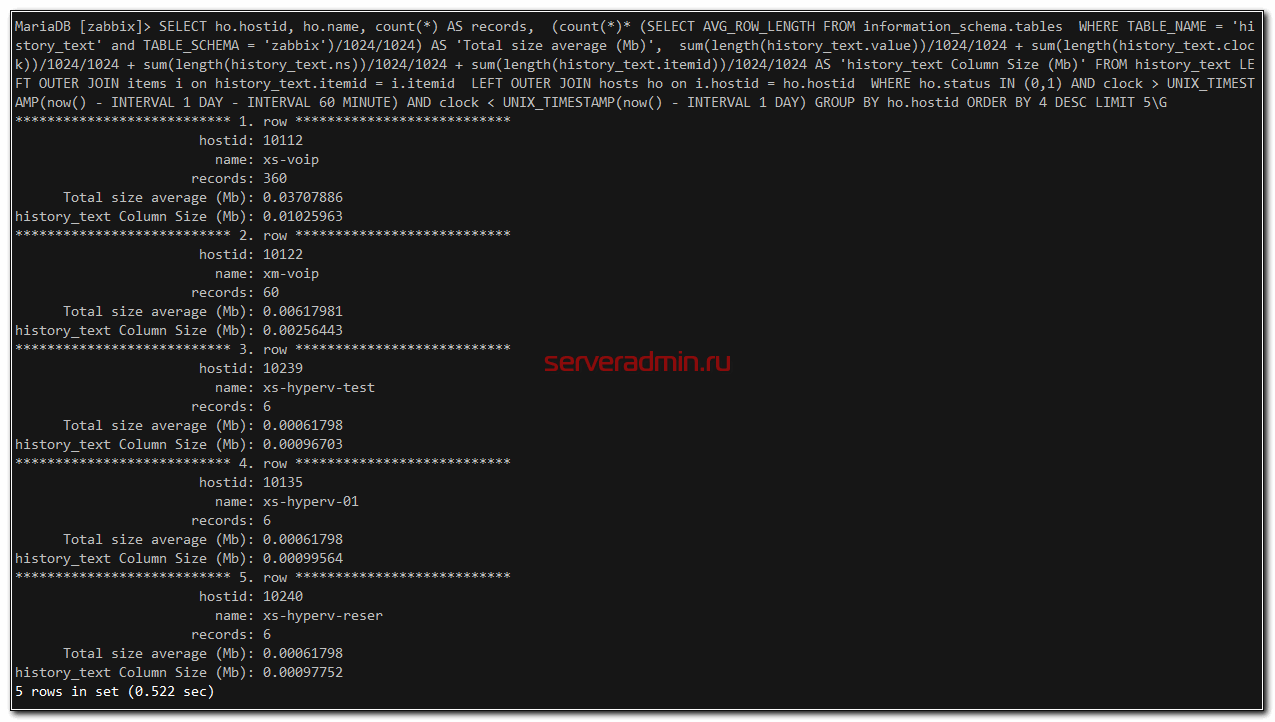
Если взять таблицу history и интервал в 3 часа, то видно, что запрос выполняется значительно дольше. Объем данных тоже для моего примера заметно подрастет.
SELECT ho.hostid, ho.name, count(*) AS records, (count(*)* (SELECT AVG_ROW_LENGTH FROM information_schema.tables WHERE TABLE_NAME = 'history' and TABLE_SCHEMA = 'zabbix')/1024/1024) AS 'Total size average (Mb)', sum(length(history.value))/1024/1024 + sum(length(history.clock))/1024/1024 + sum(length(history.ns))/1024/1024 + sum(length(history.itemid))/1024/1024 AS 'history Column Size (Mb)' FROM history LEFT OUTER JOIN items i on history.itemid = i.itemid LEFT OUTER JOIN hosts ho on i.hostid = ho.hostid WHERE ho.status IN (0,1) AND clock > UNIX_TIMESTAMP(now() - INTERVAL 1 DAY - INTERVAL 180 MINUTE) AND clock < UNIX_TIMESTAMP(now() - INTERVAL 1 DAY) GROUP BY ho.hostid ORDER BY 4 DESC LIMIT 5\G
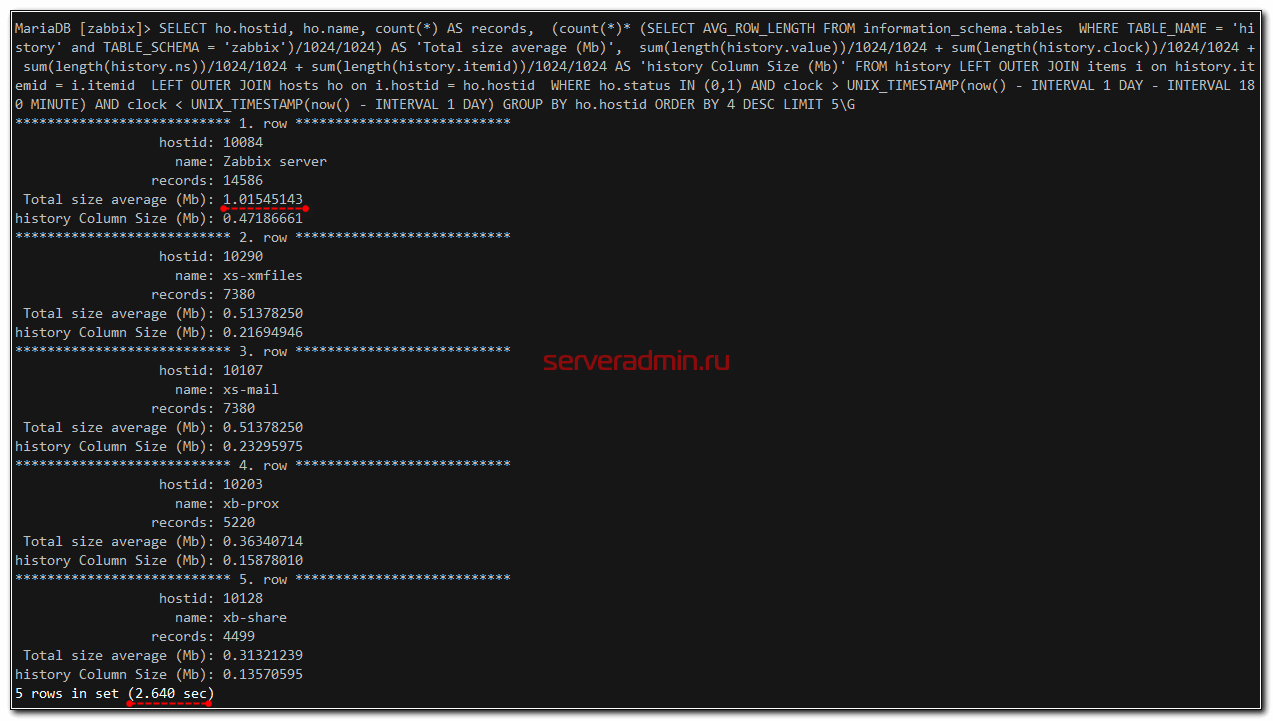
Анализ партиционированых таблиц в Mysql
Если у вас настроено партиционирование, то размер таблиц можно смотреть на уровне файловой системы:
# cd /var/lib/mysql/zabbix # ls -lh history_log#*
-rw-r-----. 1 mysql mysql 44M Jan 24 20:23 history_log#p#p2021_02w.ibd -rw-r-----. 1 mysql mysql 24M Jan 24 21:20 history_log#p#p2021_03w.ibd -rw-r-----. 1 mysql mysql 128K Jan 11 00:59 history_log#p#p2021_04w.ibd
Вы получите список всех ваших частей таблицы. Дальше каждую отдельную часть можно использовать в запросах точно так же, как до этого мы использовали целые таблицы.
SELECT ho.hostid, ho.name, count(*) AS records, (count(*)* (SELECT AVG_ROW_LENGTH FROM information_schema.tables WHERE TABLE_NAME = 'history_log' and TABLE_SCHEMA = 'zabbix')/1024/1024) AS 'Total size average (Mb)', sum(length(history_log.value))/1024/1024 + sum(length(history_log.clock))/1024/1024 + sum(length(history_log.ns))/1024/1024 + sum(length(history_log.itemid))/1024/1024 AS 'history_log Column Size (Mb)' FROM history_log PARTITION (p2021_02w) LEFT OUTER JOIN items i on history_log.itemid = i.itemid LEFT OUTER JOIN hosts ho on i.hostid = ho.hostid WHERE ho.status IN (0,1) GROUP BY ho.hostid ORDER BY 4 DESC LIMIT 10;
Очистка занимаемого места Zabbix в базе данных MySQL
Удаление хоста через GUI не гарантирует высвобождение места, которое его метрики занимали в базе. У вас просто останутся пустые строки, которые будут заполняться новыми данными. Если вы хотите освободить реально занимаемое место на диске, необходимо выполнить команду REBUILD для партиций. Их список можно посмотреть следующим образом:
SHOW CREATE TABLE history\G
И далее сделать rebuild:
ALTER TABLE history REBUILD PARTITION p202101160000;
Очистка занимаемого места Zabbix в базе данных PostgreSQL
В Postgresql есть отдельная служба, которая занимается очисткой базы данных - autovacuum. Для того, чтобы проверить, когда была последняя очистка, можно использовать запрос:
SELECT schemaname, relname, n_live_tup, n_dead_tup, last_autovacuum FROM pg_stat_all_tables WHERE n_dead_tup > 0 ORDER BY n_dead_tup DESC;
В выводе мы смотрим на n_dead_tup, что показывает "мертвые строки". Количество этих строк должно уменьшаться после выполнения autovacuum. Если подобных строк накапливается слишком много, можно увеличить частоту запуска autovacuum и его приоритет. Делается это с помощью следюущих параметров:
vacuum_cost_page_miss = 10 vacuum_cost_page_dirty = 20 autovacuum_vacuum_threshold = 50 autovacuum_vacuum_scale_factor = 0.01 autovacuum_vacuum_cost_delay = 20ms autovacuum_vacuum_cost_limit = 3000 autovacuum_max_workers = 6
На этом по размеру таблиц и занимаемому месту на диске базы данных Zabbix все. Напоминаю, что это перевод с некоторыми моими дополнениями статьи из блога zabbix.
На углубленном курсе "Архитектура современных компьютерных сетей" вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315

Поделюсь с коллегами скриптами на PostgreSQL:
-- Количество данных с разбивкой по хостам / метрикам / таблицам хранения
(SELECT hosts.name as "Hostname", items.name as "Item", COUNT(*) as "CNT", 'history' as "Table"
FROM history, items, hosts
WHERE items.itemid=history.itemid AND hosts.hostid=items.hostid
GROUP BY hosts.name, items.name
UNION ALL
SELECT hosts.name as "Hostname", items.name as "Item", COUNT(*) as "CNT", 'history_log' as "Table"
FROM history_log, items, hosts
WHERE items.itemid=history_log.itemid AND hosts.hostid=items.hostid
GROUP BY hosts.name, items.name
UNION ALL
SELECT hosts.name as "Hostname", items.name as "Item", COUNT(*) as "CNT", 'history_str' as "Table"
FROM history_str, items, hosts
WHERE items.itemid=history_str.itemid AND hosts.hostid=items.hostid
GROUP BY hosts.name, items.name
UNION ALL
SELECT hosts.name as "Hostname", items.name as "Item", COUNT(*) as "CNT", 'history_text' as "Table"
FROM history_text, items, hosts
WHERE items.itemid=history_text.itemid AND hosts.hostid=items.hostid
GROUP BY hosts.name, items.name
UNION ALL
SELECT hosts.name as "Hostname", items.name as "Item", COUNT(*) as "CNT", 'history_uint' as "Table"
FROM history_uint, items, hosts
WHERE items.itemid=history_uint.itemid AND hosts.hostid=items.hostid
GROUP BY hosts.name, items.name
UNION ALL
SELECT hosts.name as "Hostname", items.name as "Item", COUNT(*) as "CNT", 'trends' as "Table"
FROM trends, items, hosts
WHERE items.itemid=trends.itemid AND hosts.hostid=items.hostid
GROUP BY hosts.name, items.name
UNION ALL
SELECT hosts.name as "Hostname", items.name as "Item", COUNT(*) as "CNT", 'trends_uint' as "Table"
FROM trends_uint, items, hosts
WHERE items.itemid=trends_uint.itemid AND hosts.hostid=items.hostid
GROUP BY hosts.name, items.name)
ORDER BY "CNT" DESC
LIMIT 1000;
-- Количество данных с разбивкой по таблицам (по типам хранимых данных)
(SELECT 'history' AS "Table", COUNT(*) AS "CNT" FROM history
UNION ALL
SELECT 'history_uint' AS "Table", COUNT(*) AS "CNT" FROM history_uint
UNION ALL
SELECT 'history_str' AS "Table", COUNT(*) AS "CNT" FROM history_str
UNION ALL
SELECT 'history_log' AS "Table", COUNT(*) AS "CNT" FROM history_log
UNION ALL
SELECT 'history_text' AS "Table", COUNT(*) AS "CNT" FROM history_text
UNION ALL
SELECT 'trends' AS "Table", COUNT(*) AS "CNT" FROM trends
UNION ALL
SELECT 'trends_uint' AS "Table", COUNT(*) AS "CNT" FROM trends_uint)
ORDER BY "CNT" DESC;
Описание таблиц:
history - числовой (с плавающей точкой)
history_uint - числовой (целое положительное)
history_str - символ (но фактически строка)
history_log - журнал (лог)
history_text - текст (в т.ч. многострочный)
trends - динамика изменений для типа числовой (с плавающей точкой)
trends_uint - динамика изменений для типа числовой (целое положительное)
Спасибо за информацию.
Владимир огромное Вам спасибо за такое полезное дело не которое Вы делаете, публикуя подобного рода статьи!
У меня вопрос по поводу последнего пункта «Очистка занимаемого места Zabbix в базе данных MySQL», у Вас указанно что необходимо выполнить команду REBUILD для партиций, я пока в этом не очень хорошо понимаю, опыта маловато, но поправьте если я не прав. Портиции это грубо говоря набор файлов, содержащие в себе данные за определённый промежуток времени, определённой таблицы.
У меня возникло 2 вопроса:
1) Как быть в ситуации с REBUILD если у меня не настроено партицирование, но файл history_uint уже превышает 230Gb и занимает 90% пространства всего диска?
2) Если всё же настроено партицирование (отдельный файл хранящий данные за период времени), разве нельзя его просто удалить с диска?
1. Если не настроено партицирование, то очевидно, что rebuild Вам делать не надо. Вам нужно чистить данные и переходить на партиции. С таким объемом данных это уже давно пора сделать. Либо перейти на postgresql + timescaledb. Я бы лично делал второе, но переход сложнее будет, но в целом решаемо. В интернете есть пошаговые инструкции.
2. Можно. В статье rebuild делают, чтобы удалить данные от уже несуществующего хоста во всех партициях, а не только старых, которые будут удалены.
Понял, спасибо большое за ответ.
Под очисткой данных Вы имеете введу проделать удаление записей командами из статьи "Очистка, оптимизация, настройка mysql базы Zabbix"?
DELETE FROM history WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0');
DELETE FROM history_uint WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0');
DELETE FROM history_str WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0');
DELETE FROM history_text WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0');
DELETE FROM history_log WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0');
DELETE FROM trends WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0');
DELETE FROM trends_uint WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0');
После этого уменьшится ли физический размер файлов или они всё равно останутся того же размера?
history.ibd
history_uint.ibd
history_str.ibd
history_text.ibd
history_log.ibd
trends.ibd
trends_uint.ibd
Это Вам решать, что вы хотите удалить. Также учтите, что на большой базе все эти команды могут выполняться очень долго.
Мне нужно очистить место на диске, так как вся база занимает 98% всего объёма диска.
В принципе основной большой файл это history_uint.ibd он занимает ~88% объёма всего диска.
Вот я и ищу метод который позвполит освободить место на диске.
Подскажите, после команды
DELETE FROM history_uint WHERE itemid NOT IN (SELECT itemid FROM items WHERE status='0');
с удалением данных в таблице history_uint, сам файл history_uint.ibd станет меньше?
Вообще, конкретно по очистке у меня есть другая статья - https://serveradmin.ru/ochistka-i-nastroyka-bazyi-dannyih-zabbix/
Рекомендую там почитать, что конкретно делать. И обязательно посмотреть комментарии. Там даны советы команд, которые выполняются более оптимально и быстро. Я сейчас сходу не готов давать конкретные советы по очистке, так как сам ей занимаюсь в ручном режиме крайне редко.
Нашел замечательный скрипт по чистки github com/zabbix-book/partitiontables_zabbix
Спасибо, любопытный скрипт. Надо будет потестировать.
а можно так.
cd ~
mcedit zabbix_cleanup.sql
SET @history_interval = 7;
SET @trends_interval = 90;
DELETE FROM alerts WHERE (UNIX_TIMESTAMP(NOW()) - clock) > (@history_interval * 24 * 60 * 60);
DELETE FROM acknowledges WHERE (UNIX_TIMESTAMP(NOW()) - clock) > (@history_interval * 24 * 60 * 60);
DELETE FROM events WHERE (UNIX_TIMESTAMP(NOW()) - clock) > (@history_interval * 24 * 60 * 60);
DELETE FROM history WHERE (UNIX_TIMESTAMP(NOW()) - clock) > (@history_interval * 24 * 60 * 60);
DELETE FROM history_uint WHERE (UNIX_TIMESTAMP(NOW()) - clock) > (@history_interval * 24 * 60 * 60);
DELETE FROM history_str WHERE (UNIX_TIMESTAMP(NOW()) - clock) > (@history_interval * 24 * 60 * 60);
DELETE FROM history_text WHERE (UNIX_TIMESTAMP(NOW()) - clock) > (@history_interval * 24 * 60 * 60);
DELETE FROM history_log WHERE (UNIX_TIMESTAMP(NOW()) - clock) > (@history_interval * 24 * 60 * 60);
DELETE FROM trends WHERE (UNIX_TIMESTAMP(NOW()) - clock) > (@trends_interval * 24 * 60 * 60);
DELETE FROM trends_uint WHERE (UNIX_TIMESTAMP(NOW()) - clock) > (@trends_interval * 24 * 60 * 60);
сохраняем
mysql -uroot -p
use zabbix;
source zabbix_cleanup.sql
Владимир, Благодарю Вас за прекрасный сайт. Вы делаете очень полезное дело. На сайте и в ваших работах вы используете системы мониторинга grafana и продукцию микротик. Было бы очень интересно, если вы сделаете инструкцию по настройке мониторинга роутера mikrotik через сервер prometheus + grafana. в интернете нет статей, написанных популярным языком, как осуществить данную операцию, хотя snmp_exporter есть на github, а в графане есть готовый дашборд.
Я сам prometheus не использую на практике, поэтому и статей по нему нет.
спасибо большое
Очень полезный материал, Владимир. Спасибо за ваш труд!