
Продолжаю тему настройки и использования централизованной системы сбора логов на основе elasticsearch. Сегодня расскажу, как настроить сбор и анализ логов аудита samba в ELK Stack. Я буду не только собирать логи, но и обрабатывать их и добавлять метаданные для построения графиков и дашбордов.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном онлайн-курcе по администрированию MikroTik. Автор курcа – сертифицированный тренер MikroTik Дмитрий Скоромнов. Более 40 лабораторных работ по которым дается обратная связь. В три раза больше информации, чем в MTCNA.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Введение
Для установки и настройки файлового сервера samba можно воспользоваться одной из моих статей:
- Настройка файлового сервера Samba с интеграцией в Active Directory
- Быстрая и простая настройка samba
Дальнейшее описание подойдет для обоих случаев. И для интеграции с AD, и для одиночного сервера с авторизацией по IP или имени пользователя.
Для того, чтобы samba записывала в лог все операции с файлами, необходимо настроить логирование. Как это сделать я рассказал уже давно в отдельной статье - настройка логов доступа в samba. Дальше в статье я буду считать, что у вас настроено примерно так же. Формат логов очень важен, так как ниже я предложу свой вариант grok фильтра для парсинга.
Сбор логов samba
Для сбора логов с samba сервера необходимо на него установить filebeat. Как это сделать рассказано в моей статье по установке и настройке elk stack. Создаем простой конфиг для filebeat - /etc/filebeat/filebeat.yml.
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/samba/audit.log
fields:
type: smb-audit
fields_under_root: true
scan_frequency: 5s
output.logstash:
hosts: ["10.1.4.114:5044"]
Минимум опций. Просто отправляем все записи лога самбы audit.log в logstash по адресу 10.1.4.114 и устанавливаем тип - smb-audit. Это сделано для удобства в дальнейшей обработке и вычленении логов самбы из общего потока данных. Идентичные настройки будут на всех серверах samba.
Парсинг логов samba в logstash
Нам нужно принять логи с samba в logstash, обработать их и передать в elasticsearch. Для приема логов в конфиге logstash /etc/logstash/conf.d/input.conf (напомню, что у меня для удобства конфиг разделен на 3 части input.conf, filter.conf, output.conf) у меня уже есть строки:
input {
beats {
port => 5044
}
}
Так что ничего добавлять не надо. Дальше нам нужно настроить фильтрацию логов. Для этого в filter.conf добавляю строки:
else if [type] == "smb-audit" {
mutate {
gsub => ["message","[\\|]",":"]
gsub => ["message"," "," "]
}
grok {
match => [ "message" , "%{MONTH:syslog_month} %{MONTHDAY:syslog_day} %{TIME:syslog_time} %{HOSTNAME:srv_name} smbd_audit: XS:%{GREEDYDATA:user_name}:%{IP:user_ip}:%{WORD:share_name}:%{WORD:action}:%{DATA:sucess}:%{GREEDYDATA:path}"]
overwrite => [ "message" ]
}
}
В данном случае выше в конфиге у меня уже есть другие правила. Если же данное правило у вас будет единственным, то else не нужно указывать. Расскажу, что делают данные правила. Плагин mutate и операция gsub в первой строке заменяет в логе самбы все обратные слеши \ и | на : Это сделано для того, чтобы потом было проще использовать фильтр grok. Вторая операция gsub заменяет двойной пробел на единичный. Это сделано для того, чтобы убрать двойной пробел в логах самбы, когда в числе месяца используется одна цифра. Вот пример:
Nov 6 18:00:41 xmdoc smbd_audit: XS\kobelev|10.1.4.49|documents|open|ok|r|Конструкторы/_Проекты/15667/проработка.dwg
Nov 13 12:04:47 xmdoc smbd_audit: XS\ignatev|10.1.4.81|documents|open|ok|r|Конструкторы/_Проекты/02649.обрамление.dwg
В первом случае после Nov стоят 2 пробела. Это усложняет настройку парсинга. Поэтому лишние пробелы и символы убираем. После работы фильтра mutate мы получим вот такую строку:
Nov 6 18:00:41 xmdoc smbd_audit: XS:kobelev:10.1.4.49:documents:open:ok:r:Конструкторы/_Проекты/15667/проработка.dwg
Дальше вступает в дело фильтр grok и его правило обработки:
%{MONTH:syslog_month} %{MONTHDAY:syslog_day} %{TIME:syslog_time} %{HOSTNAME:srv_name} smbd_audit: XS:%{GREEDYDATA:user_name}:%{IP:user_ip}:%{WORD:share_name}:%{WORD:action}:%{DATA:sucess}:%{GREEDYDATA:path}
Оно не идеальное, но мои запросы удовлетворяет. Проверить работу фильтра можно в grok debugger. На выходе будет вот такой json:
{
"user_ip": "10.1.4.49",
"share_name": "documents",
"syslog_time": "18:00:41",
"srv_name": "xmdoc",
"user_name": "kobelev",
"syslog_month": "Nov",
"path": "r:Конструкторы/_Проекты/15667/проработка.dwg",
"syslog_day": "6",
"sucess": "ok",
"action": "open"
}
В моем случае не парсится значение домена XS из лога, так как все делается в рамках одного домена, и я просто опустил это действие. Вам нужно подработать правило под свои реалии. Если у вас много доменов, добавьте отдельное поле для имени домена. Если это не нужно, просто поменяйте на свой домен. Из названия полей думаю и так понятно, что я сделал. Я выделил ключевые для меня значения, которые дальше буду использовать в графиках и дашбордах. Я не смог отдельно выделить путь файла без лишних символов в начале. Не помню точно, с чем конкретно это связано, но в целом, проблема в том, что лог сильно изменяется в зависимости от проводимой операции. Единым фильтром было трудно все охватить, пришлось бы разделять разные события на разные потоки и анализировать отдельно. Я посчитал, что это не имеет смысла.
Если у вас samba не в домене, то лог будет немного другой. Вот пример строки лога и моего grok фильтра для обработки. Исходный лог:
Nov 13 11:40:54 xb-share smbd_audit: 10.1.5.20|scans|realpath|ok|Отсканированные счета/2018/счет.pdf
После работы фильтра mutate:
Nov 13 11:40:54 xb-share smbd_audit: 10.1.5.20:scans:realpath:ok:Отсканированные счета/2018/счет.pdf
Дальше вступает в дело grok фильтр
%{MONTH:syslog_month} %{MONTHDAY:syslog_day} %{TIME:syslog_time} %{HOSTNAME:srv_name} smbd_audit: %{IP:user_ip}:%{WORD:share_name}:%{WORD:action}:%{DATA:sucess}:%{GREEDYDATA:path}
И на выходе получаем обработанные данные:
{
"user_ip": "10.1.5.20",
"share_name": "scans",
"syslog_time": "11:40:54",
"srv_name": "xb-share",
"syslog_month": "Nov",
"path": "Отсканированные счета/2018/счет.pdf",
"syslog_day": "13",
"sucess": "ok",
"action": "realpath"
}
Теперь эти данные надо передать в elasticsearch. Добавляем в конфиг output.conf строки:
else if [type] == "smb-audit" {
elasticsearch {
hosts => "localhost:9200"
index => "smb-audit-%{+YYYY.MM}"
}
}
Если других правил у вас нет, то else уберите. После этого нужно перезапустить logstash и проверять через kibana поступление обработанных логов.
Дашборд в ELC Stack для логов samba
Я немного поразмышлял и собрал вот такой dashboard для логов samba.
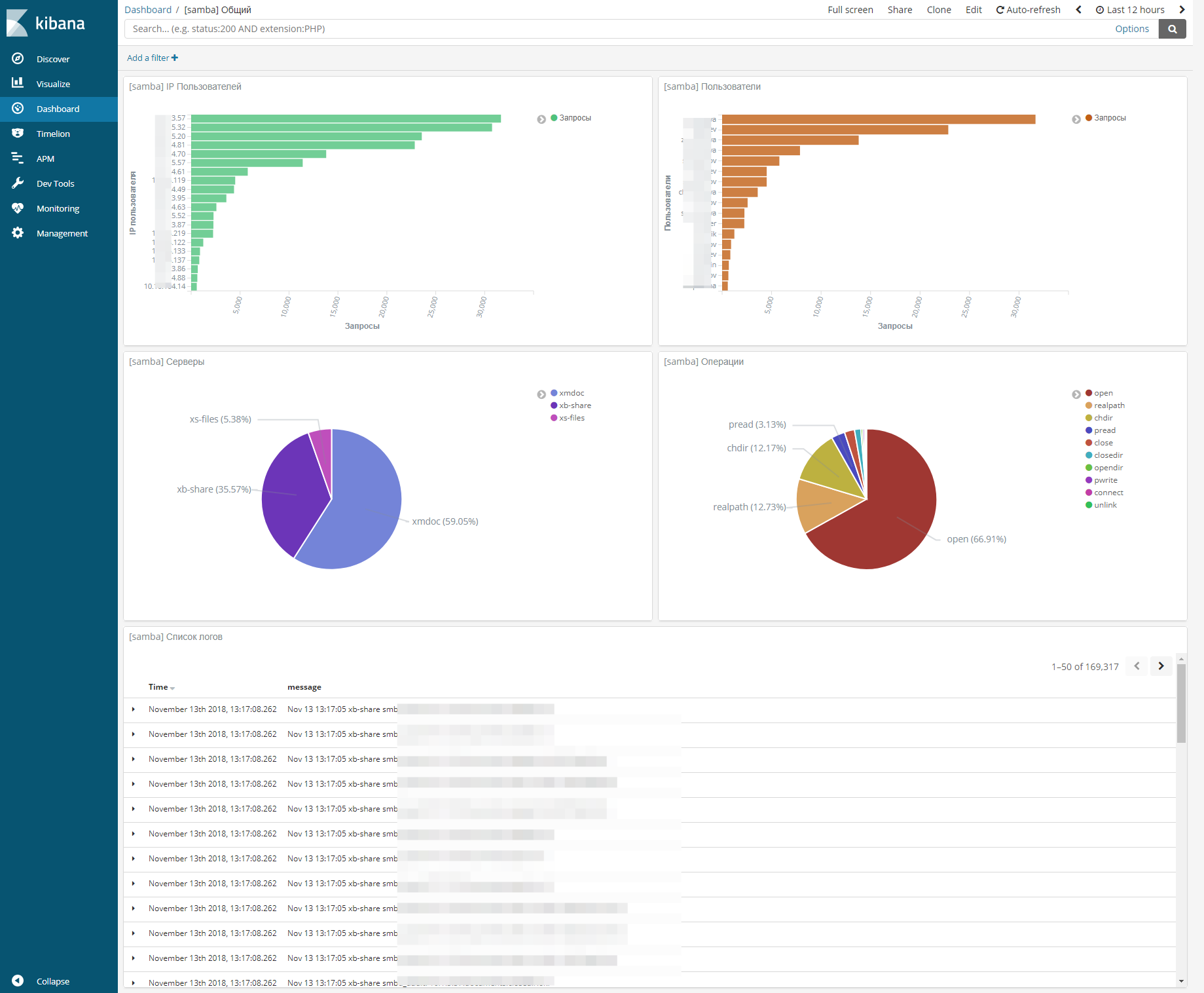
На этом дашборде расположены следующие визуализации:
- Количество запросов с конкретного IP.
- Количество запросов по доменному имени пользователя.
- Распределение запросов между тремя файловыми серверами.
- Распределение по типам операций.
- Список исходных логов.
При выборе конкретного сервера, мы получаем дашборд с информацией только по нему. То же самое по пользователям, ip, операциям и т.д. Стало ОЧЕНЬ удобно анализировать работу серверов. К примеру, если у вас в сети появится шифровальщик, вы сразу же это увидите на дашборде и узнаете ip источника проблемы. Про банальное - узнать, кто у удалил или изменил файл я и не говорю.
Большие выбросы на графиках дают пользователи, которые используют поиск по сетевым дискам. У них будет огромное количество операций чтения. Но тут уже ничего не поделать. Визуализация не идеальная, но тем не менее, очень упрощает жизнь.
Заключение
Вот таким относительно простым и эффективным способом можно облегчить управление файловыми серверами, особенно когда их много. Я раньше и представить не мог, что можно так удобно собрать всю информацию с логов и вывести в наглядном виде. А потом еще и фильтровать все это по нужным параметрам практически на лету.
В следующей статье расскажу, как сделать то же самое, только для файловых серверов на windows. Там примерно такой же dashboard будет, но сбор и анализ логов другие.
Логичным продолжением этой работы были бы уведомления при превышении пороговых значений. Пока руки не дошли разобраться с темой. Краем уха слышал, что функционал триггеров и уведомлений реализуется только платными модулями. Если у кого-то есть информация на данную тему, прошу поделиться в комментариях.
На углубленном курсе "Архитектура современных компьютерных сетей" вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315

GROK фильтров может быть много, перечисляются через запятую. Синтаксис такой:
grok {
break_on_match => true
match => [
"message", "%{PATTERN1:field_name}",
"message", "%{PATTERN1:field_name} %{PATTERN2:field_name}"
Добрый день, по вашим статьям все получилось настроить и добавить, мониторятся логи микроитка,samba,asterisk и других серверов, но никак не могу понять как делать такие красивые и информативные дашборды?? может кто чем поможет?
Так тут ничего особенного нет. Просто сделайте несколько визуализаций и потом объедините их в дашборд. Там надо немного разобраться, как это делать, в дальше пойдет без проблем. Главное, смысл уловить. Можно видео на ютуб посмотреть, если самому не получается. Я сам разобрался в визуализациях, когда надо было.
Здравствуйте, подскажите правильно ли я понял суть своей проблемы вот выхлоп лога samba в Kibana:
input.type:log source:/var/log/samba/samba_audit/share1.log tags:beats_input_codec_plain_applied, _grokparsefailure message:Dec 27 12:35:30 server1 smbd_audit: ufa:192.168.5.11:close:ok:Формы/Шаблон @version:1 host.name:server1 beat.version:6.4.0 beat.name:server1 beat.hostname:server1 offset:731,320,624 prospector.type:log type:smb-audit @timestamp:December 27th 2018, 12:35:30.679 _id:TbHN7mcBWPrVKi-k6w5J _type:doc _index:smb-audit-2018.12 _score: -
получается grok фильтр
match => [ "message" , "%{MONTH:syslog_month} %{MONTHDAY:syslog_day} %{TIME:syslog_time} %{HOSTNAME:srv_name} smbd_audit: %{User:user}:%{IP:user_ip}:%{WORD:action}:%{DATA:sucess}:%{GREEDYDATA:path}"]
не отрабатывает строчку smbd_audit: и не парсит по заданным параметрам на основе которых уже можно создавать дашборд
или так и должно быть?
*match => [ "message" , "%{MONTH:syslog_month} %{MONTHDAY:syslog_day} %{TIME:syslog_time} %{HOSTNAME:srv_name} smbd_audit: %{WORD:user}:%{IP:user_ip}:%{WORD:action}:%{DATA:sucess}:%{GREEDYDATA:path}"]
p.s в grokdebug всё отрабатывается
Тэг _grokparsefailure означает, что поступившая строка не совпадает с фильтром, который ее должен обрабатывать.
спасибо разобрался, теперь возник вопрос как Дашборды делать, данные получаю всё парсится, есть какой-то манул интуитивно не совсем понятно
Сначала надо делать визуализации, потом из них собирать дашборд. Немного не очевидно, но можно разобраться методом тыка. Завтра будет статья про дашборды для виндовых серверов. Там будет пример создания визуализации.
Огромное Вам спасибо
Данные которые отпарсились не появляются в дашборде так как у них статус ? насколько я понимаю kibana не может определить что какой тип у этого параметра, его можно как-то поставить вручную?
Аналогично!
Не могу сообразить как задать тип данных в распарсенных данных.
я так и не смог разобраться с этим _grokparsefailure. получается точно такой же выхлоп как у Вас повыше. подскажите, плиз
_grokparsefailure говорит однозначно о том, что grok шаблон не работает на потоке входящих данных. Отлаживайте шаблон в Grok Debugger.
Привет! хотел спросить а Вы используете APM-server и APM-агенты ?
Нет, не использовал.
Есть https://github.com/Yelp/elastalert и плагин для kibana https://github.com/bitsensor/elastalert-kibana-plugin
Я настраивал только elastalert, работал отлично.
Большое спасибо за очередной полезный туториал.
Думаю многим было бы интересно увидеть ваш фильтр и визуализацию для messages(system) и secure(auth) логов.
До этого как раз руки не дошли. Secure логи для ssh подключений я мониторю в zabbix - https://serveradmin.ru/monitoring-ssh-loginov-v-zabbix/ Можно в elk перенести, но не вижу большого смысла. А вот как парсить messages я не знаю. Да и не понимаю, возможно ли это. Там же очень разные события. Под каждое событие нужен свой фильтр. Надо выделять ключевые моменты, которые нужны и парсить именно их. Тут универсальных советов быть не может. Мне, к примеру, в общем случае не нужен парсинг системных логов. Нужно просто хранение. Далее настраивается мониторинг нужных сервисов. Если они падают или есть какие-то другие проблемы с сервером, то просматриваются системные логи.
Было бы удобно как-то нужные логи подтягивать в заббикс оповещения. Но это уже нетривиальная задача.
Извиняюсь за свою невнимательность: а как вы настроили алертинг для NGINX логов и используете ли его в общем?
В сторону чего в первую очередь нужно смотреть, если нужно настроить алертинг по логам?
Спасибо ;)
Не настраивал и не использую, но очень хочу. Не было времени разобраться. Беглый поиск показал, что модуль с алертами в кибана платный, а бесплатно это в кибана сделать не получится. Информацию не проверял.
В первую очередь нужен алерт на большое число ошибок веб сервера, на большое число запросов к одному url, на больше число запросов с одного IP. Это первое, что приходит в голову.
В планах у меня статья по мониторингу времени ответа бэкенда. Я уже настроил и проверил все. Вот по нему тоже нужны будут оповещения, если бэкенд отвечает слишком медленно.
Эту тему лучше продолжать в статье по nginx. Тут все же samba.