
Некоторое время назад я настраивал работу 1С предприятия с базой данных postgresql. Во время тестирования столкнулся с проблемой медленной работы некоторых запросов. Хочу поделиться полезной информацией, которая позволит разобраться в таких ситуациях и попытаться ускорить работу и избавиться от узких мест в базе.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном онлайн-курcе по администрированию MikroTik. Автор курcа – сертифицированный тренер MikroTik Дмитрий Скоромнов. Более 40 лабораторных работ по которым дается обратная связь. В три раза больше информации, чем в MTCNA.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Содержание:
Данная статья является частью единого цикла статьей про сервер Debian.
Введение
Сервер postgresql настроен по предыдущей статье - Установка и настройка postgresql на debian 8 для работы с 1С. Основные моменты по ускорению работы базы там приведены. Они существенно увеличивают производительность по сравнению с настройками по-умолчанию. В большинстве случаев этого бывает достаточно. Если нет - то у вас уже не типичный случай и надо разбираться более детально.
Проблема, с которой столкнулся я, кроется в особенности работы postgresql и отсутствии оптимизации 1С для работы с этой бд. База данных postgresql, в отличие от mssql, не умеет распараллеливать выполнение одного запроса не несколько ядер процессора. Даже если у вас очень высокопроизводительный сервер с большим числом ядер, вы можете попасть в ситуацию, когда какой-то тяжелый запрос будет очень сильно тормозить, нагружая только одно ядро. Остальные мощности процессора будут простаивать при этом. Увеличение ресурсов сервера никак не поможет вам ускорить работу базы. Она будет всегда спотыкаться на этом запросе.
Параллельное выполнение запросов на нескольких ядрах в postgresql
Я использовал версию postgresql 9.6. Если верить новости - http://www.opennet.ru/opennews/art.shtml?num=43313 в ней добавлена поддержка распараллеливания запросов. Я стал пробовать на практике это распараллеливание. Информации в интернете, к моему сожалению, не так много. Вроде проблема популярная, много где видел вопросов на эту тему. Например, вот тут обсуждают тему использования нескольких ядер процессора для выполнения запроса - http://www.sql.ru/forum/1002408/zadeystvovanie-neskolkih-processorov.
Наиболее популярные рекомендации, это изменить запросы и логику работы приложения с БД, чтобы не попадать в ситуацию, когда возникает один большой запрос, который невозможно разбить и обработать параллельно на нескольких ядрах. Пример такого подхода есть на хабре - https://habrahabr.ru/post/76309/. У меня нет ни должных знаний sql, ни тем более 1С, чтобы на уровне приложения что-то менять. Стал разбираться с возможностями postgresql.
Есть несколько параметров, которые как раз отвечают за параллельную обработку запросов:
max_worker_processes = 16 max_parallel_workers_per_gather = 8 min_parallel_relation_size = 0 parallel_tuple_cost = 0.05 parallel_setup_cost = 1000
Их необходимо подбирать под свое количество ядер. В данном случае настройки представлены для 16-ти ядерной системы. Далее необходимо применить скрипт на базе 1С, который позволит оптимизатору постгреса использовать параллельную обработку тех запросов 1С где участвуют текстовые поля (большинство запросов), путём изменения определений функций. Текст скрипта очень длинный, поэтому не привожу его здесь, чтобы не нагружать статью. Качаем его с сайта - postgre.sql.
Запрос необходимо выполнить в базе, которую использует 1С. Для этого можно воспользоваться либо программой pgAdmin, либо напрямую подключиться к базе, через консоль сервера. Опишу второй вариант в подробностях.
Подключаемся к серверу с postgresql по ssh. Заходим под юзером postgres:
# su postgres
Переходим в домашний каталог пользователя:
# cd
Создаем файл с запросом, который будем выполнять. В данном случае можете сразу скопировать файл, который скачали ранее, либо создайте вручную и скопируйте в него текст запроса.
# touch postgre.sql
Если будете копировать готовый файл, убедитесь, что у пользователя postgres есть доступ к этому файлу.
Подключаемся к серверу бд:
# psql -U postgres
Подключаемся к нужной базе данных:
\connect base1c
Выполняем sql запрос из файла:
\i postgre.sql
Все, можно идти проверять. Мы должны были увеличить быстродействие 1С запросов в базе postgresql, разрешив использовать параллельную обработку некоторых запросов. В моем случае это не дало никакого прироста по проблемным запросам. Сама база в целом работала нормально, но спотыкалась на определенных запросах. Разбираемся дальше.
Логирование sql запросов в postgresql
Для того, чтобы разобраться, что же конкретно у нас тормозит, надо посмотреть на сами запросы. Для этого нам нужно включить логирование запросов к базе данных. Запросов будет очень много, нам не нужны все подряд. Сделаем ограничение на логирование только тех запросов, которые выполняются дольше, чем 3 секунды. Для этого рисуем следующие параметры в конфиге БД:
log_destination = 'syslog' syslog_facility = 'LOCAL0' syslog_ident = 'postgres' log_min_duration_statement = 3000 # 3000 мс = 3 секунды log_duration = off log_statement = 'none'
И добавляем описание канала для логов LOCAL0 в конфиг rsyslog в файле /etc/rsyslog.conf, в самый конец:
LOCAL0.* -/var/log/postgresql/sql.log
Если оставить настройки rsyslog в таком виде, то лог запросов будет писаться не только в файл /var/log/postgresql/sql.log, но и в messages, и в syslog. Я не люблю спамить в системные логи, поэтому отключим запись sql логов туда. Добавляем в описание этих лог файлов значение LOCAL0.none. Должно получиться примерно так:
*.*;auth,authpriv.none;LOCAL0.none -/var/log/syslog
*.=info;*.=notice;*.=warn;\
auth,authpriv.none;\
cron,daemon.none;\
mail,news.none;\
LOCAL0.none -/var/log/messages
Перезапускаем postgresql и rsyslog:
# systemctl restart postgresql # systemctl restart rsyslog
Идем в базу 1С и вызываем свой запрос, который тормозит. Если его выполнение занимает больше, чем 3 секунды, вы увидите текст запроса в лог файле. Можете подольше попользоваться базой, чтобы собрать список запросов для анализа. Запросы 1С настолько громоздкие, что даже просто скопировать их из лога и обработать непростая задача. Воспользуемся для этого специальной программой.
Анализ запросов postgresql с помощью pgFouine
Устанавливаем pgFouine в debian:
# apt-get install pgfouine
Это старая программа, но для наших целей сойдет. Пользоваться ей очень просто. Я не вдавался в подробности настройки и не смотрел возможные параметры. Мне было достаточно сделать вот так:
# pgfouine -file /var/log/postgresql/sql.log > /root/report.html
Забираем файл report.html к себе на компьютер и открываем в браузере. У меня получилось примерно так:
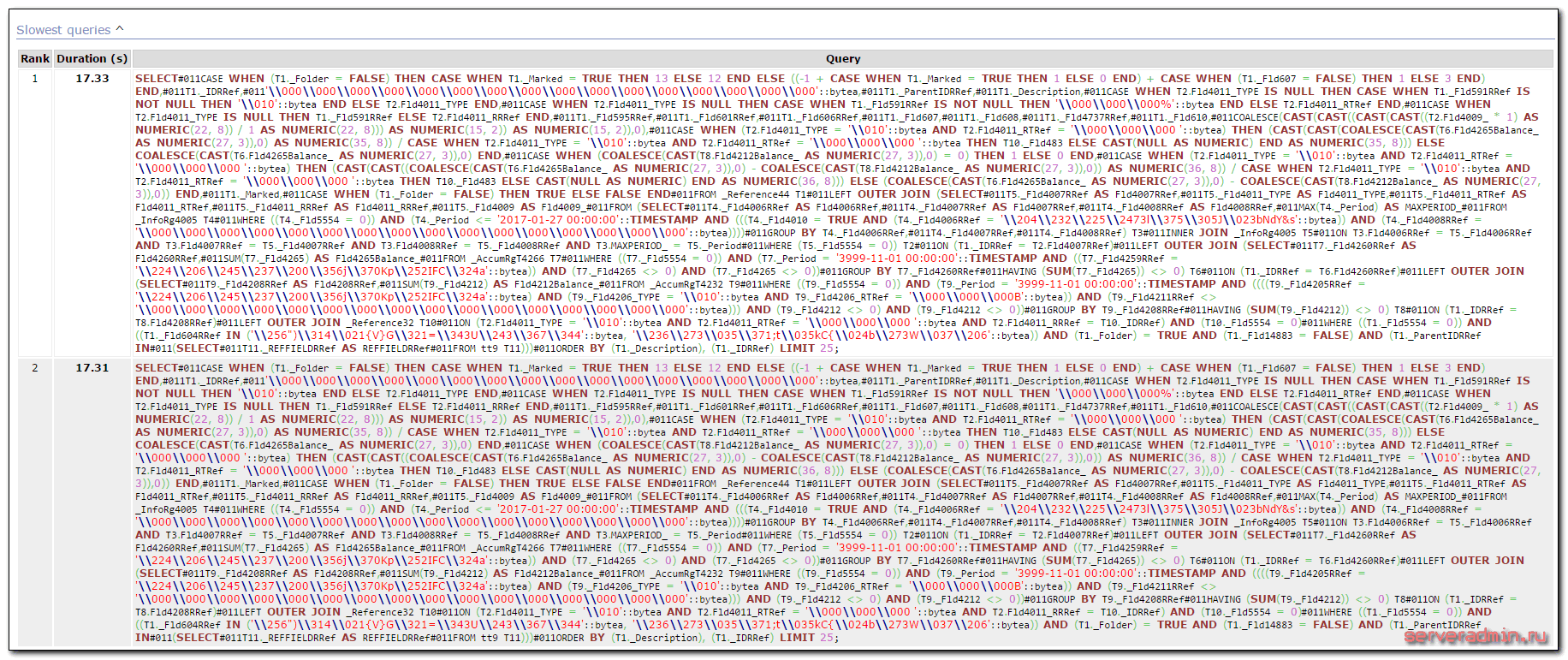
Запрос впечатляет :) Не удивительно, что он тормозит! Сказать, что я был удивлен, это ничего не сказать. Глядя на эти запросы, я понимал, что никакой оптимизации в 1С для работы с postgresql нет. Хотя я очень плохо разбираюсь в sql, знаком поверхностно с синтаксисом, и сам составлял только очень простые запросы. Но даже я вижу, что проблема тормозов в том, что этот запрос просто безобразно огромный. Парсер запроса нахватал в код мусорных символов. В моем случае это символы #011, они присутствую в логе sql.log. Я не знаю, откуда они там берутся, но чтобы получить чистый запрос, их надо убрать. Я скопировал текст запроса в текстовый редактор и сделал замену символов #011 на пробел. В итоге получился синтаксически корректный запрос. В моем случае он выглядит таким образом:
SELECT CASE WHEN (T1._Folder = FALSE) THEN CASE WHEN T1._Marked = TRUE THEN 13 ELSE 12 END ELSE ((-1 + CASE WHEN T1._Marked = TRUE THEN 1 ELSE 0 END) + CASE WHEN (T1._Fld607 = FALSE) THEN 1 ELSE 3 END) END, T1._IDRRef, '\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000'::bytea, T1._ParentIDRRef, T1._Description, CASE WHEN T2.Fld4011_TYPE IS NULL THEN CASE WHEN T1._Fld591RRef IS NOT NULL THEN '\\010'::bytea END ELSE T2.Fld4011_TYPE END, CASE WHEN T2.Fld4011_TYPE IS NULL THEN CASE WHEN T1._Fld591RRef IS NOT NULL THEN '\\000\\000\\000%'::bytea END ELSE T2.Fld4011_RTRef END, CASE WHEN T2.Fld4011_TYPE IS NULL THEN T1._Fld591RRef ELSE T2.Fld4011_RRRef END, T1._Fld595RRef, T1._Fld601RRef, T1._Fld606RRef, T1._Fld607, T1._Fld608, T1._Fld4737RRef, T1._Fld610, COALESCE(CAST(CAST((CAST(CAST((T2.Fld4009_ * 1) AS NUMERIC(22, 8)) / 1 AS NUMERIC(22, 8))) AS NUMERIC(15, 2)) AS NUMERIC(15, 2)),0), CASE WHEN (T2.Fld4011_TYPE = '\\010'::bytea AND T2.Fld4011_RTRef = '\\000\\000\\000 '::bytea) THEN (CAST(CAST(COALESCE(CAST(T6.Fld4265Balance_ AS NUMERIC(27, 3)),0) AS NUMERIC(35, 8)) / CASE WHEN T2.Fld4011_TYPE = '\\010'::bytea AND T2.Fld4011_RTRef = '\\000\\000\\000 '::bytea THEN T10._Fld483 ELSE CAST(NULL AS NUMERIC) END AS NUMERIC(35, 8))) ELSE COALESCE(CAST(T6.Fld4265Balance_ AS NUMERIC(27, 3)),0) END, CASE WHEN (COALESCE(CAST(T8.Fld4212Balance_ AS NUMERIC(27, 3)),0) = 0) THEN 1 ELSE 0 END, CASE WHEN (T2.Fld4011_TYPE = '\\010'::bytea AND T2.Fld4011_RTRef = '\\000\\000\\000 '::bytea) THEN (CAST(CAST((COALESCE(CAST(T6.Fld4265Balance_ AS NUMERIC(27, 3)),0) - COALESCE(CAST(T8.Fld4212Balance_ AS NUMERIC(27, 3)),0)) AS NUMERIC(36, 8)) / CASE WHEN T2.Fld4011_TYPE = '\\010'::bytea AND T2.Fld4011_RTRef = '\\000\\000\\000 '::bytea THEN T10._Fld483 ELSE CAST(NULL AS NUMERIC) END AS NUMERIC(36, 8))) ELSE (COALESCE(CAST(T6.Fld4265Balance_ AS NUMERIC(27, 3)),0) - COALESCE(CAST(T8.Fld4212Balance_ AS NUMERIC(27, 3)),0)) END, T1._Marked, CASE WHEN (T1._Folder = FALSE) THEN TRUE ELSE FALSE END FROM _Reference44 T1 LEFT OUTER JOIN (SELECT T5._Fld4007RRef AS Fld4007RRef, T5._Fld4011_TYPE AS Fld4011_TYPE, T5._Fld4011_RTRef AS Fld4011_RTRef, T5._Fld4011_RRRef AS Fld4011_RRRef, T5._Fld4009 AS Fld4009_ FROM (SELECT T4._Fld4006RRef AS Fld4006RRef, T4._Fld4007RRef AS Fld4007RRef, T4._Fld4008RRef AS Fld4008RRef, MAX(T4._Period) AS MAXPERIOD_ FROM _InfoRg4005 T4 WHERE ((T4._Fld5554 = 0)) AND (T4._Period <= '2017-01-27 00:00:00'::TIMESTAMP AND (((T4._Fld4010 = TRUE AND (T4._Fld4006RRef = '\\204\\232\\225\\2473l\\375\\305J\\023bNdY&s'::bytea)) AND (T4._Fld4008RRef = '\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000'::bytea)))) GROUP BY T4._Fld4006RRef, T4._Fld4007RRef, T4._Fld4008RRef) T3 INNER JOIN _InfoRg4005 T5 ON T3.Fld4006RRef = T5._Fld4006RRef AND T3.Fld4007RRef = T5._Fld4007RRef AND T3.Fld4008RRef = T5._Fld4008RRef AND T3.MAXPERIOD_ = T5._Period WHERE (T5._Fld5554 = 0)) T2 ON (T1._IDRRef = T2.Fld4007RRef) LEFT OUTER JOIN (SELECT T7._Fld4260RRef AS Fld4260RRef, SUM(T7._Fld4265) AS Fld4265Balance_ FROM _AccumRgT4266 T7 WHERE ((T7._Fld5554 = 0)) AND (T7._Period = '3999-11-01 00:00:00'::TIMESTAMP AND ((T7._Fld4259RRef = '\\224\\206\\245\\237\\200\\356j\\370Kp\\252IFC\\324a'::bytea)) AND (T7._Fld4265 <> 0) AND (T7._Fld4265 <> 0)) GROUP BY T7._Fld4260RRef HAVING (SUM(T7._Fld4265)) <> 0) T6 ON (T1._IDRRef = T6.Fld4260RRef) LEFT OUTER JOIN (SELECT T9._Fld4208RRef AS Fld4208RRef, SUM(T9._Fld4212) AS Fld4212Balance_ FROM _AccumRgT4232 T9 WHERE ((T9._Fld5554 = 0)) AND (T9._Period = '3999-11-01 00:00:00'::TIMESTAMP AND ((((T9._Fld4205RRef = '\\224\\206\\245\\237\\200\\356j\\370Kp\\252IFC\\324a'::bytea) AND (T9._Fld4206_TYPE = '\\010'::bytea AND T9._Fld4206_RTRef = '\\000\\000\\000B'::bytea)) AND (T9._Fld4211RRef <> '\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000'::bytea))) AND (T9._Fld4212 <> 0) AND (T9._Fld4212 <> 0)) GROUP BY T9._Fld4208RRef HAVING (SUM(T9._Fld4212)) <> 0) T8 ON (T1._IDRRef = T8.Fld4208RRef) LEFT OUTER JOIN _Reference32 T10 ON (T2.Fld4011_TYPE = '\\010'::bytea AND T2.Fld4011_RTRef = '\\000\\000\\000 '::bytea AND T2.Fld4011_RRRef = T10._IDRRef) AND (T10._Fld5554 = 0) WHERE ((T1._Fld5554 = 0)) AND ((T1._Fld604RRef IN ('\\256")\\314\\021{V}G\\321=\\343U\\243\\367\\344'::bytea, '\\236\\273\\035\\371;t\\035kC{\\024b\\273W\\037\\206'::bytea)) AND (T1._Folder) = TRUE AND (T1._Fld14883 = FALSE) AND (T1._ParentIDRRef IN (SELECT T11._REFFIELDRRef AS REFFIELDRRef FROM tt9 T11))) ORDER BY (T1._Description), (T1._IDRRef) LIMIT 25;
Дальше вы можете разбираться со своими запросами, в зависимости от ваших знаний и возможностей. Я не знал, что делать дальше, для решения своей проблемы. Попытался построить карту запроса с помощью EXPLAIN ANALYZE, но не получилось. Запрос использует какие-то временные таблицы, так что просто скопировать и повторить его не получалось. Выходила ошибка, что какой-то таблицы не существует.
В настоящий момент я получил совет на профильном форуме по моей проблеме. Мне сказали, что ситуация известная и достаточно типичная для 1С. Исправлять ее нужно на стороне самой 1С, изменяя код запроса выборки из виртуальных таблиц на запросы из временных таблиц, соединяя их потом с основной. Это уже задача для программиста. Я в самой 1С не разбираюсь вообще.
Заключение
На текущий момент моя проблема не решена, но стало понятно, в каком направлении двигаться и что делать. В принципе, я изначально, когда стал заниматься этой задачей, предполагал, что проблема именно на стороне 1С из-за сложного запроса и отсутствии оптимизации работы 1С именно с postgresql. Я это понял, потому что с mssql таких тормозов никогда наблюдал на базах такого размера. В данном случае объем базы всего 10 гб, она не очень большая. 15 секунд лопатить запрос на такой базе можно только, если этот запрос ужасен. На деле все так и оказалось.
В процессе разбора ситуации приобрел определенный опыт, который постарался зафиксировать в этой статье. Думаю, он пригодится в будущем, как мне, так и другим пользователям. В интернете не нашел хороших статей по анализу производительности постгрес. Пришлось все собирать по крохам в разных статьях, но больше на форумах. С учетом стоимости лицензии mssql, замена ее на postgresql выглядит весьма обоснованной, так что тема актуальна.
Буду рад любым замечаниям и советам в комментариях. Тема для меня новая, но полезная. Хотелось бы разобраться в работе постгрес.
Напоминаю, что данная статья является частью единого цикла статьей про сервер Debian.
На углубленном курсе "Архитектура современных компьютерных сетей" вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315

Добрый день, а нет ли у вас услуги оптимизации postgere sql на windows сервере?
У меня - нет. Я не большой специалист по базам данных.
Бытует мнение, что лучшая ФС для postgres - это много, ОЧЕНЬ много оперативы. Чтоб и база и весь журнал туда спокойно помещались. При этом, максимально агрессивная запись транзакций, дабы избежать потери данных. 1С в основном берет SELECT запросы.
Что касается параллельных запросов, узким местом является не процессор, а дисковая подсистема. Если вся база с журналом может разместиться в памяти - то лучше ее туда и разместить. Тогда и проц будет получше утилизироваться. Но в любом случае, postgres очень любит NVMe накопители. В таком случае и с параллельной записью все будет ОК.
И да, у меня счас 1с вполне успешно и комфортно крутится на postgres-12
Подскажите пожалуйста, сколько у вас пользователей работает на сервере? У нас на 1С сервере (Debian) примерно 60 подключений, сеансов. Сейчас запущено 4 rphost по 20 сеансов на каждый и памяти всего сервер потребляет 8GB. Сколько у вас пользователей и сколько памяти потребляет сервер 1С?
В данном примере проблема тормозов была из-за тяжелых запросов, нагружающих полностью одно ядро. Даже если вся база влезет в оперативу, принципиально от этого скорость работы этого запроса не вырастет. Диск не был узким местом.
Временные таблицы в PostgreSQL не включают параллелизм
( https://infostart.ru/1c/articles/1497478/ )
Отсюда и утилизация 1 ядра
2019 год, 1С уже поддерживает 11.5.
Параллельность рекомендуется отключать и на MS SQL. Даже не так, отключение дает предсказуемый результат, а включать надо очень осторожно, под присмотром, можно получить дедлоки на параллельных потоках или загрузку процессора на 100% при выполнении одного запроса и полностью неработоспособную базу у всех пользователей, из-за того, что главбух запустил тяжелый отчет. И вообще выхлоп это дает в редких случаях, ибо с 1С работают как правило пользователей, больше чем ядер, поэтому каждое ядро обслуживает несколько потоков и получаем более-менее сбалансированную нагрузку.
Делать выводы о сложности запроса по его величине - по меньшей мере странно. Можно написать длиннющий запрос, выбирающий много полей из всего лишь одной строки таблицы по кластерному индексу, а можно выбрать несколько полей из непокрывающего индекса, который просканирует всю таблицу. Это в общем случае, там все намного сложнее, больше условностей.
Мусорные символы - это похоже на временные (промежуточные) таблицы, они значительно упрощают программирование. А еще 1С добавляет дополнительные условия или поля, чтобы оптимизатор воспринял запрос как новый. Может значительно помочь, если стоит отбор на поле, которое при разном значении параметра может давать кардинально разную селективность запроса и план запроса ошибется, например какой-нибудь флажок, включен у 1млн строк, а выключен у 10 строк. В данной ситуации должны быть совершенно разные планы запроса, хотя запрос тот же, значение флажка передается через параметр.
В общем, ищите человека с сертификатом 1С: Эксперт по технологическим вопросам, не Ваше это... И да, правильно посоветовали, бОльшая часть проблем сидит именно в коде 1С, причем дописанном, а не типовом.
Согласен с автором. Действительно в обновлении 8.3 много новых фич появилось: гибко настраиваемые отчеты, возможности запуска программы в браузере, трехзвенная архитектура системы. Из-за этого программа работает медленнее на прежних компьютерах. Краткий план работы такой:
1)Зафиксируйте проблему. Самостоятельно, поручите ответственному сотруднику или другим доступным способом.
2)Оцените допустимые значения и выгоду от ускорения процесса.
3)Назначьте ответственного – специалиста из штата или профессионала со стороны.
4)Оцените окупаемость работ и примите решение, нужны ли они. Принимать решение, ускорять 1С или нет, я советую делать на основе оценок теоретических убытков от медленной работы, и стоимости работ специалистов.
5)Проследите за выполнением работ.
6)Подведите итоги.
Не понятна фраза - "Для этого рисуем следующие параметры в конфиге БД:"
В каком еще конфиге? для каждой БД есть свой конфиг? А где? Можно название файла для примера и путь?
В статье идет речь о сервере баз данных. Вне настройки вносятся в его конфигурацию. В разных версиях postgresql или операционных системах он в разных местах может быть.
Да я то понял что о сервере базы данных. Я не первый день вижу постгрес, 1С и Линукс. Просто я не в курсе где именно хранятся файлы и какие они. Поэтмоу фраза что надо чтото внести в конфиг БД - непонятна.. Ибо где эти конфиги
У меня Ubuntu + Postgres 9.4
Жаль в Вашей статье ни строчки по поводу оптимизации системы и bios под postgres(((
В bios нечего оптимизировать под postgres.
видел советы по включению\отключению некоторых опций. Но раз Вы расхотели учиться, то ладно, не буду пруф кидать :-)
Опции Биоса не для постгреса, а для 1С.
Хватит уже интриговать. Напишите, о чем идет речь. Никогда о подобном не слышал и даже представить не могу, что может быть в биосе для оптимизации работы приложения.
Может можем где-то списаться что бы в комментах не мусорить?
Лучше поделитесь со всеми, чем с одним челом в личке
Написал в телегу.
https://pgday.ru/files/pgmaster14/ilya.kosmodemiansky.linux.postgresql.tuning.pdf
или вот ещё http://www.gilev.ru/bioshp/
Боже.. это такой несусветный бред , то что там написано по оптимизации якобы БИОСа для 1С.. Господи. чушь для лохов.
1. те настройки биоса еще 20-ти летней давности. Счас совсем по другому все.
2. там всего навсего, ускоряется память, включается режим турбо для проца, и ускоряется кеш.. Какой осел в инете, назвал это ускорением для 1С?
Это всеравно что разогнать проц и память по шине - будет ровно тоже.. РОВНО!!
Это все, - общие настройки ускорения и разгона все что там приведено. И конкретно к 1С они никакого отношения не имеют. Разгоните память или проц и будет также.
так то!!!
Приветствую, а где вы нашли тот sql-ный скрипт для параллельной обработки запросов в 1С? Хочу потестировать, интересны первоисточники
К сожалению, не помню :( Хотел сейчас найти источник, но не смог. Возможно, мне его кто-то передал, так как я общался с несколькими людьми на эту тему.
Здравствуйте, на данный момент что-то сдвинулось с точки по распараллевиванию? Если да можете дополнить статью в каком направлении копать для оптимизации кода 1с? Пробовал выполнять запросы не из терминала а через саму 1с впринципе всё нормально прирост производительности очень высок, только переписывать практически все типовые вещи вообще не вариант т.к. потом невозможно будет нормально обновляться. Я к чему клоню есть такая вещь как "custom mods to PostgreSQL" вот только инфы гугль мало пока даёт. Поробуйте поискать может моды проще будет написать чем мучать типовую Постгри?
До меня доходила информация, что в каком-то обновление, описанные в этой статье тормоза исправили и теперь как минимум подобной ошибки быть не должно. Но сам я не проверял.
Просто наткнулся в гугле на статью о PargreSQL ребята на уровне не языка, а на уровне платформы Постгри заставляли работать так базу данных как им хотелось. Мне интересна тема показалась именно для типовых конфигураций, но куда копать дальше не знаю. Можно же сами запросы которая Платформа 1с использует прооптимизировать т.е. Например делает временную таблицу а мы хватаем на уровне платформы Постгри этот запрос и создаем таблицы в памяти а не на диске. И таких примеров много можно привести. Теже ядра ЦП задействовать.
Все это можно делать, но для этого нужны соответствующие знания и навыки :) Тут сходу не разобраться, нужно изучать тему подробно.
Думаю подвижки со стороны 1С будут. Не так давно анонсировалось сотрудничество PostgreSQL PRO и 1С. Были красивые картинки и графики, где коммерческая версия PostgreSQL PRO показывала, что она неплохо может "нагнуть" MSSQL. Думаю 1С займется оптимизацией в ближайшем будущем. Продавать то лицензии надо будет.
одмин, у тебя чат не ворк "Вы ввели некорректный параметр siteDomain: "www.chatbro.com"
Правильный параметр: "serveradmin.ru""