
Виртуализация в том или ином виде сейчас – основа большинства IT систем. В статье я расскажу, как настроить обычный кластер и кластер высокой доступности (HA) на базе open source платформы Proxmox VE. На сегодняшний день – это один из самых популярных бесплатных продуктов для построения инфраструктуры виртуальных машин и контейнеров.
Введение
Виртуализация Proxmox Virtual Environment (Proxmox VE) в последние несколько лет стала практически безальтернативной в сфере малого и среднего бизнеса, вытеснив оттуда другие продукты, такие как Hyper-V Server или платформы на базе Xen (XenServer и XCP-ng). Речь идёт именно о бесплатных платформах для виртуализации, которые закрывают потребности небольших и средних компаний. А в каких-то задачах и крупных.
Обусловлено это тем, что инфраструктура на базе продуктов Proxmox закрывает следующие потребности:
- Одиночный сервер виртуализации, либо несколько одиночных серверов, не связанных между собой, для решения разнородных задач.
- Кластер из двух серверов с возможностью быстрой миграции виртуальных машин с одного на другой.
- Отказоустойчивый кластер из трёх и более серверов для непрерывной работы виртуальных машин в случае выхода из строя части оборудования.
- Бэкап всей виртуальной инфраструктуры с такой доступной функциональностью как полные и инкрементные бэкапы, сжатие и дедупликация, хранение архивных копий в нескольких разнесённых хранилищах.
В данной статье я расскажу про установку и настройку отказоустойчивого кластера Proxmox VE из трёх нод. Сервера для этой статьи предоставлены компанией Selectel. По сути она выступила спонсором данного материала, так как без доступного железа написать её не представляется возможным. В статье можно будет увидеть все этапы реального построения кластера – от заказа серверов и начальной настройки в панели управления хостера, до ввода кластера в эксплуатацию.
Аренда сервера в Selectel
Для заказа сервера в Selectel необходимо зарегистрироваться в панели управления. Достаточно будет указать свой email и задать пароль.
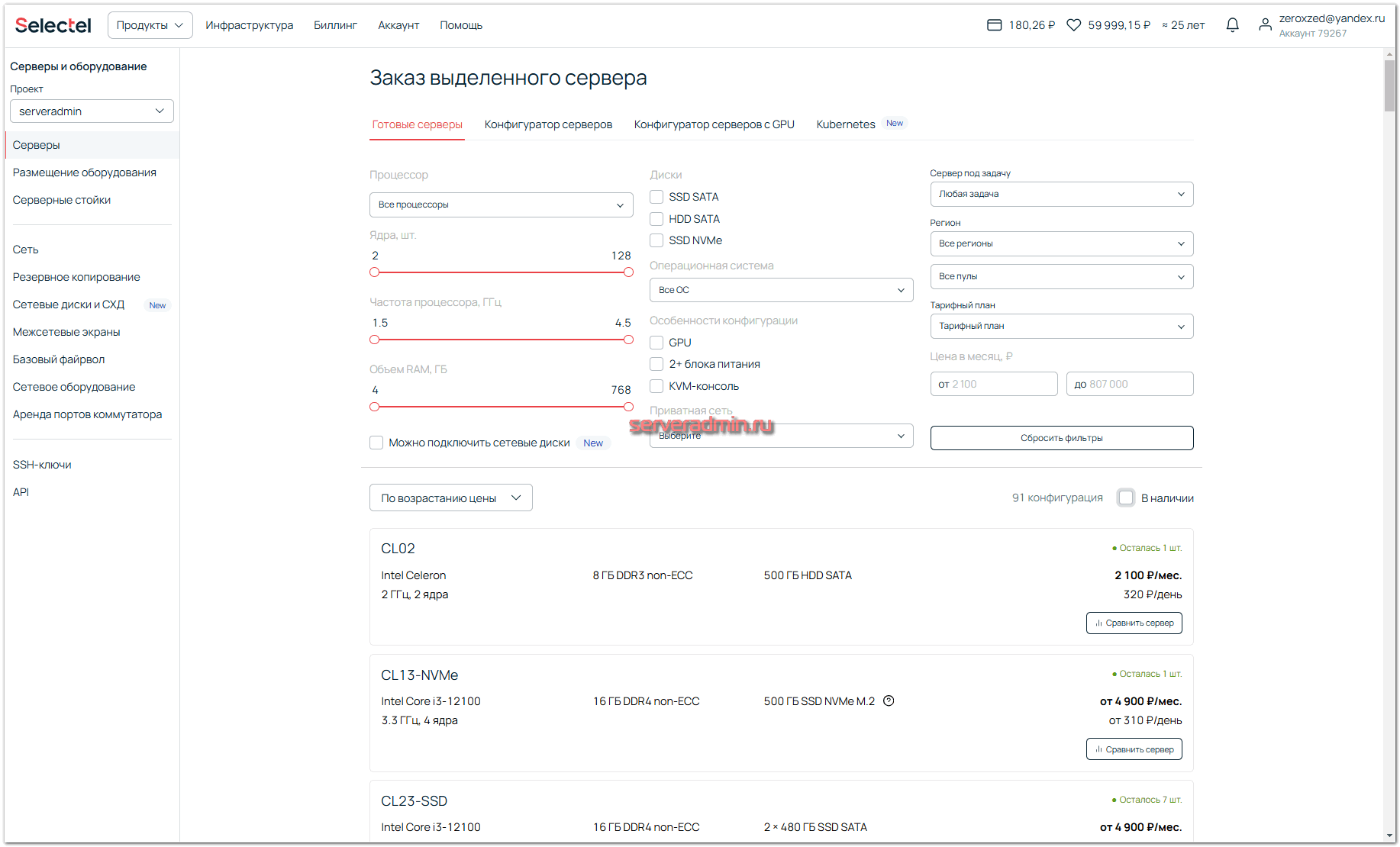
Для заказа выделенных серверов в панели управления необходимо перейти в раздел Инфраструктура ⇨ Выделенные серверы. Выбор конфигураций обширный: от одноплатников и бюджетных серверов на десктопном железе до мощных серверов с несколькими топовыми видеокартами.
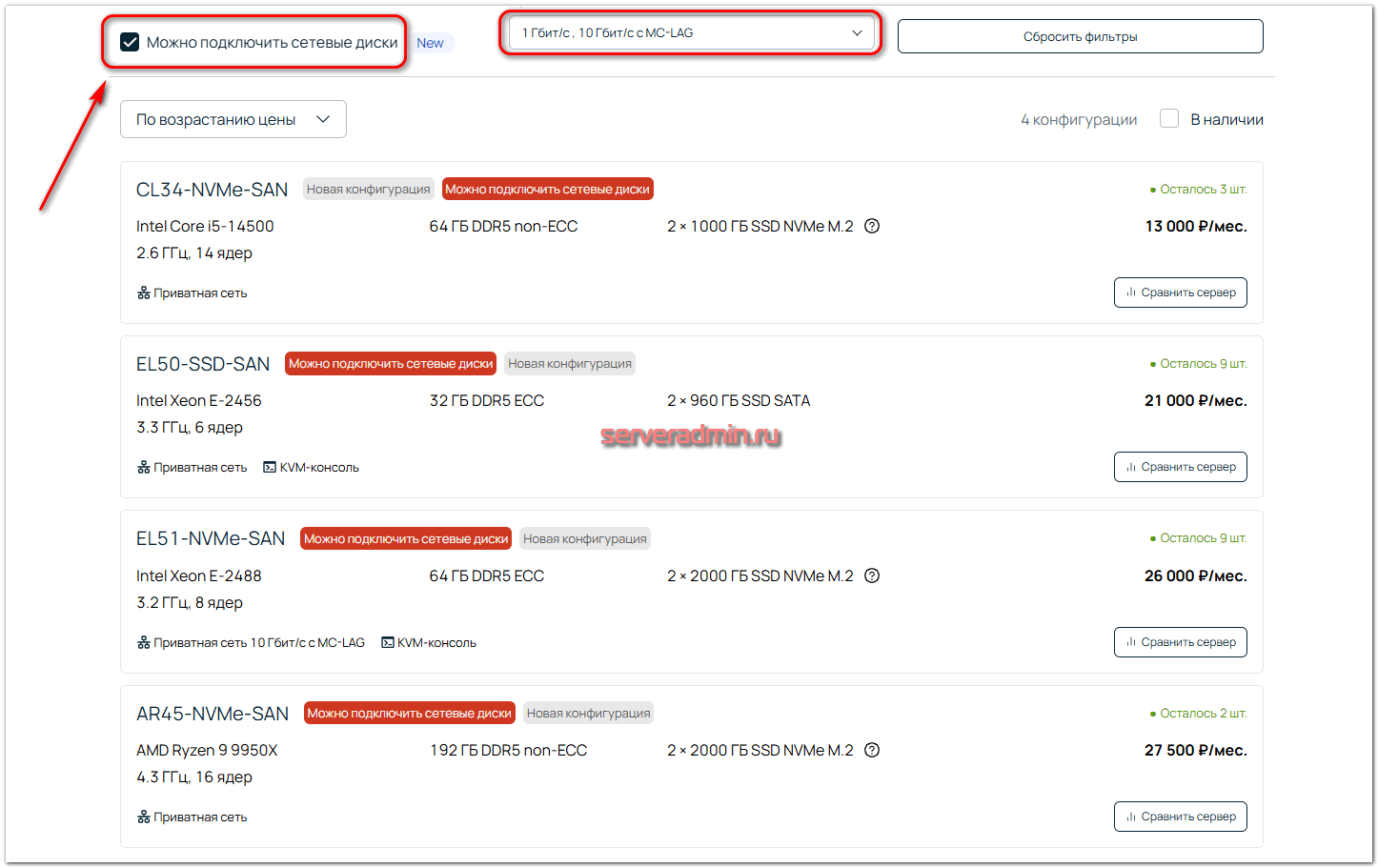
Для моей задачи мне понадобятся 3 сервера с возможностью подключения к ним общих сетевых дисков. Это позволит создать один из вариантов отказоустойчивого кластера на базе общего хранилища для виртуальных машин. В такой конфигурации не придётся самостоятельно прорабатывать вопрос отказоустойчивого файлового хранилища, хотя на базе Proxmox это решаемая задача.
Указываю в фильтре условие Можно подключить сетевые диски и дополнительно возможность создания приватной сети для серверов. Выбираю подходящие варианты.
В зависимости от выбранных конфигураций и наличия серверов вы либо сразу их получите в управление, либо будет создана автоматическая заявка в техническую поддержку на их подготовку.
В моей практике бюджетные массовые конфигурации доступны сразу, более дорогие обычно нет. Тут как повезёт. Если вы собираете сервер самостоятельно через конфигуратор, то скорее всего придётся подождать, когда он будет готов. Не берусь обобщать время подготовки серверов, но на моей практике я их получал либо сразу, либо в течении 1-2 дней. Если есть какие-то вопросы по конфигурациям, либо если нет чего-то в наличии, то имеет смысл оставить заявку в техподдержку. С вами свяжется менеджер, с ним можно будет обсудить как вопрос непосредственно железа, так и его стоимости. Советую этим пользоваться, если у вас крупный или нестандартный заказ.
Я остановился на конфигурации серверов под названием AR45-NVMe-SAN. Она имеет следующие характеристики:
| Процессор | AMD Ryzen 9 9950X 4.3 ГГц |
| Память | 192 ГБ DDR5 NON-ECC |
| Диск | 2 × 2000 ГБ SSD NVMe M.2 |
Установка Proxmox VE

После заказа я получил 3 сервера в свой личный кабинет.
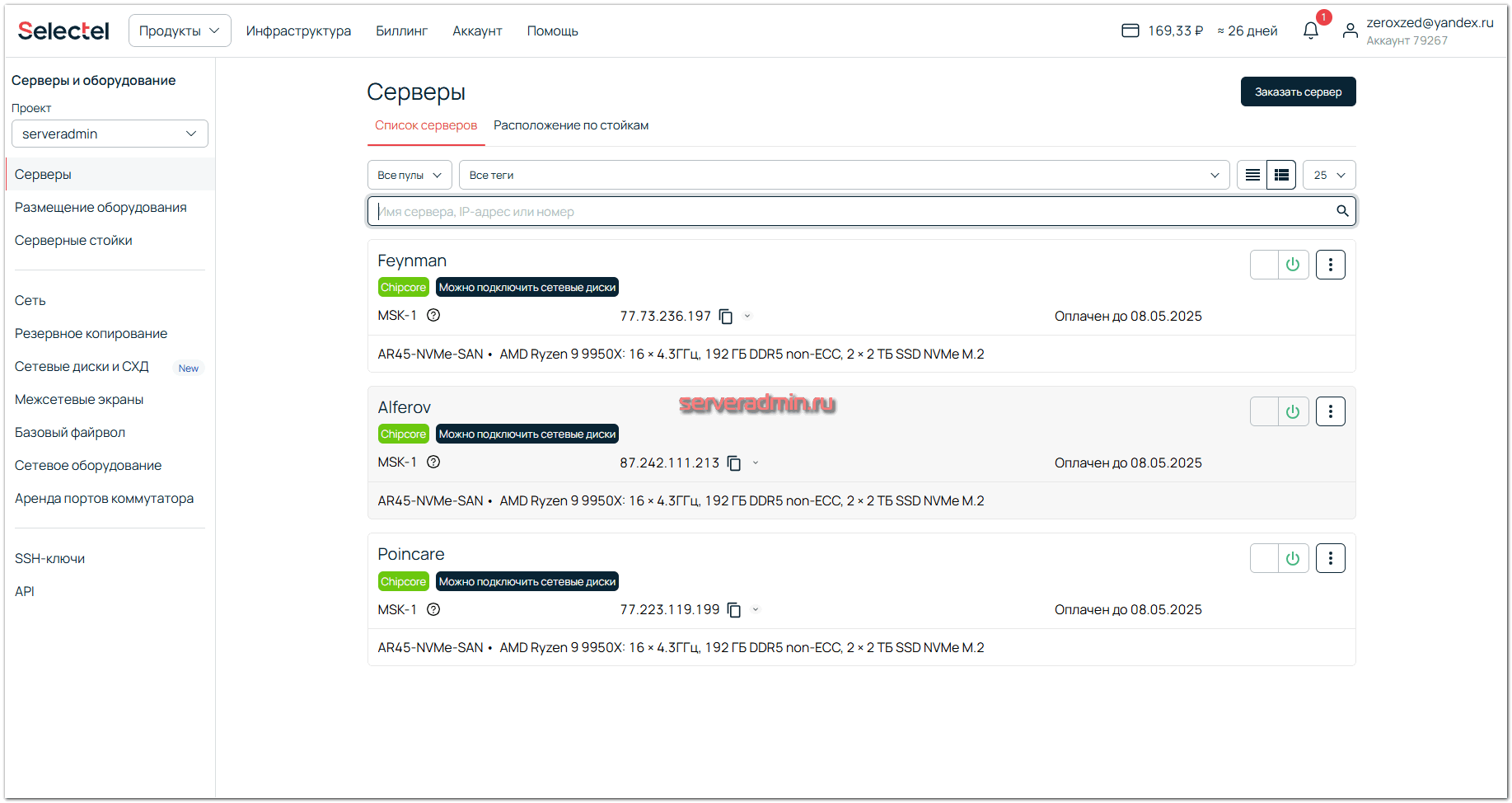
Сразу переименовываю их для удобства и заказываю для каждого установку системы. В интерфейсе управления установкой ОС есть возможность сразу добавить SSH-ключ и набор команд в виде bash скрипта или cloud-config для первоначальной настройки системы. Я выбираю шаблон Proxmox VE 8 с установкой на mdadm raid1, так как в системе есть 2 диска.
Обращаю внимание на то, что готовый шаблон всё делает за вас. Объединяет диски в mdadm массив, делает разбивку, которую вы можете отредактировать тут же в панели управления. Базовую установку системы вам делать вообще не нужно. После заказа системы через панель управления, вы сразу же получите SSH доступ в установленную по вашим параметрам систему. Это особенно удобно для временных или тестовых стендов, которые регулярно заказываются и потом через некоторое время удаляются. Используя свои скрипты преднастройки вы сразу же получаете сервер с установленной и настроенной системой.
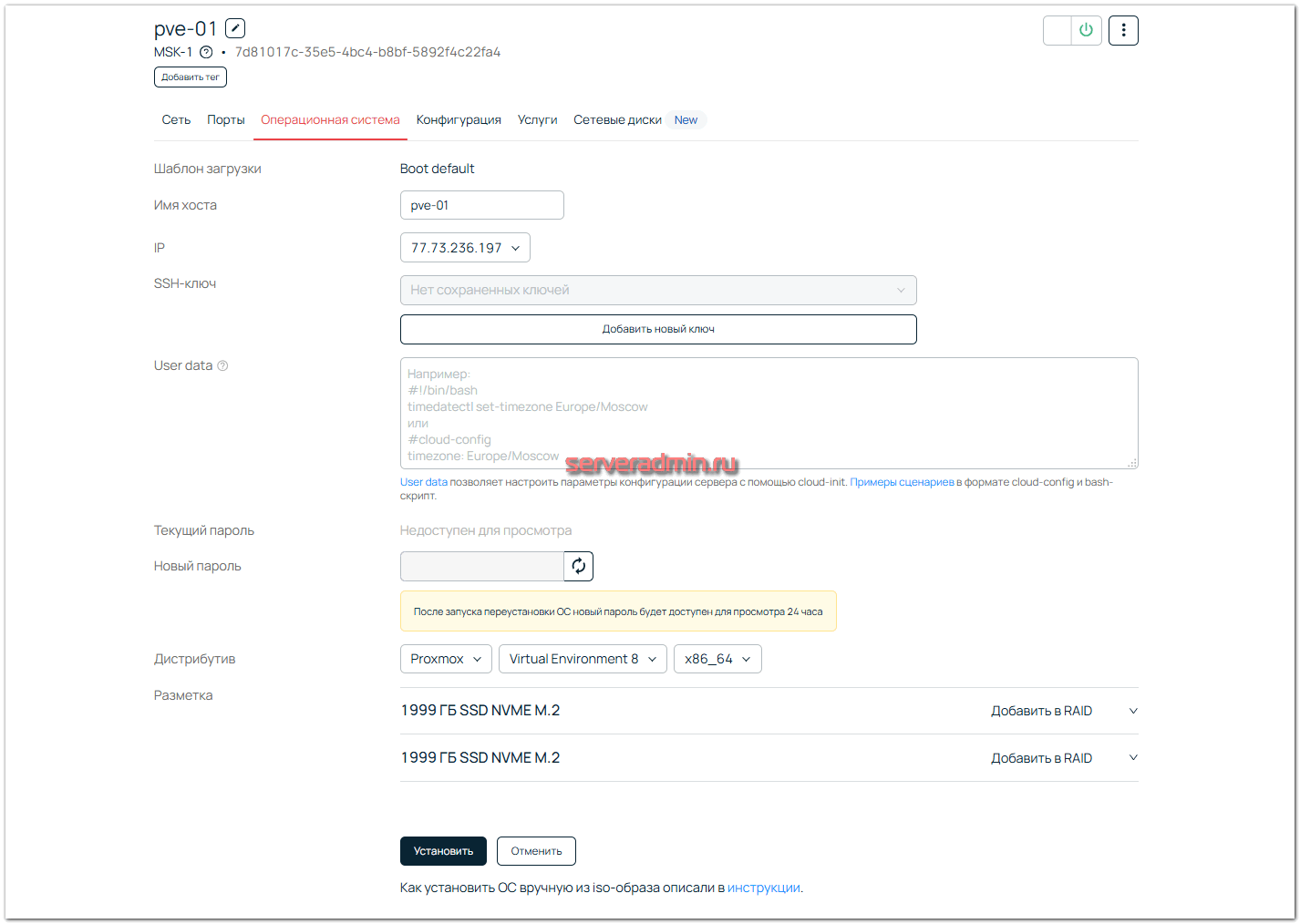
Установка обычно длится минут 10. После завершения тут же в панели управления можно увидеть пароль от сервера. Он будет виден только 24 часа. Обязательно его надо записать, особенно если не добавляли свой публичный ключ.
Каждый арендованный сервер имеет один внешний IP адрес. Также все мои арендованные серверы объединены виртуальной локальной сетью. Это одна из услуг Selectel. Доступна не на всех арендуемых серверах, так что нужно следить за этим, если вам нужна общая локальная сеть. Иначе придётся сервера объединять по VPN через внешние интерфейсы.
Дожидаюсь окончания установки ОС и подключаюсь по SSH к серверам. Сразу же проверяю состояние mdadm:
# cat /proc/mdstat
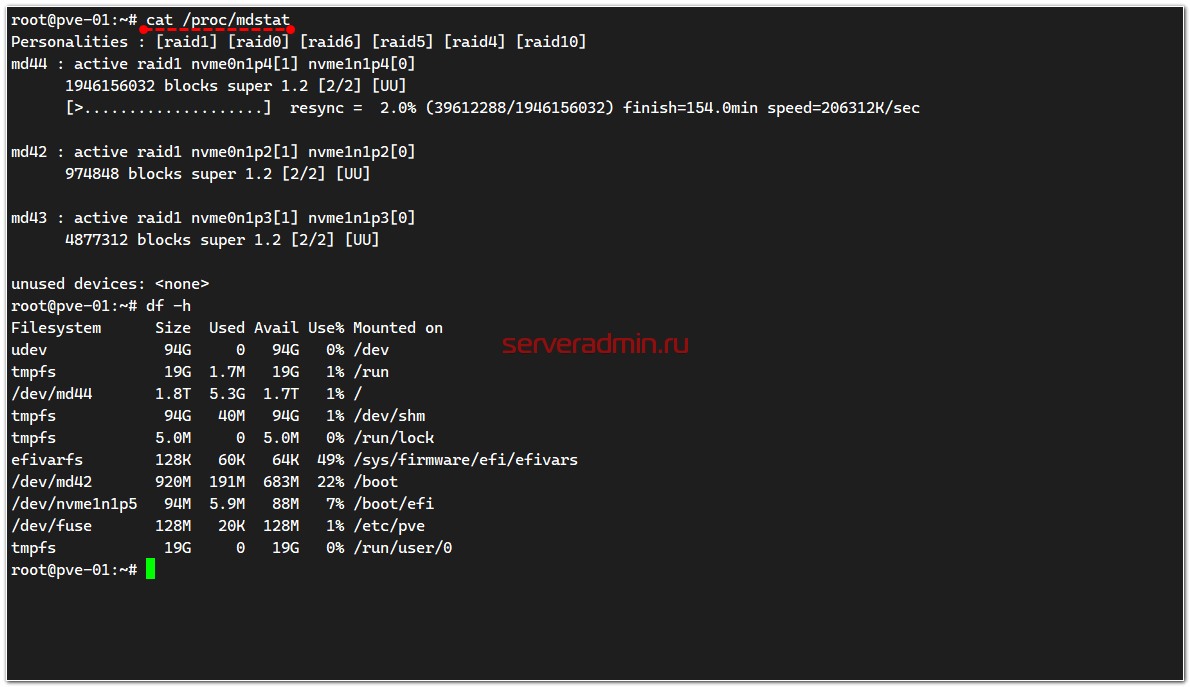
Вижу, что массив собран, идёт синхронизация корневого раздела. Вижу, что /boot раздел на зеркале. И вижу, что есть раздел /boot/efi на диске /dev/nvme1n1p5. Мне нужно убедиться, что и на втором он тоже есть. Смотрю разметку дисков:
# fdisk -l | grep /dev/
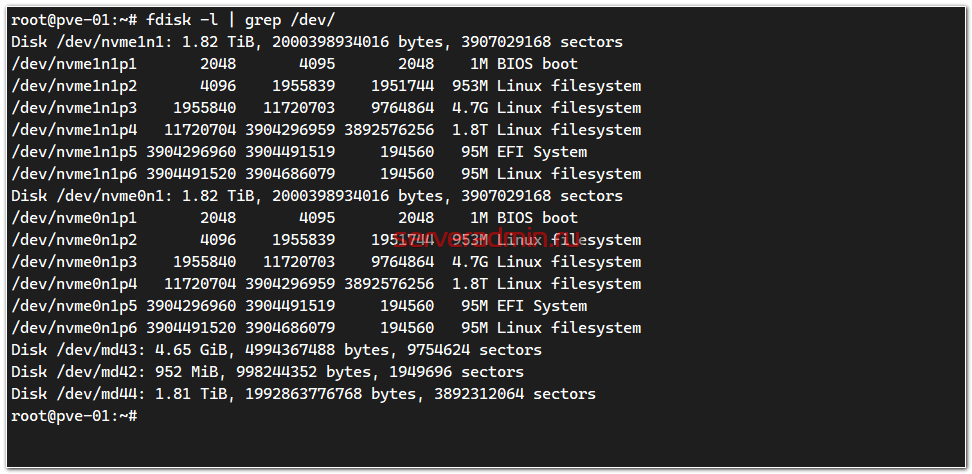
Разметка одинаковая. На всякий случай проверяю, что на /dev/nvme0n1p5 содержимое такое же, как на /dev/nvme1n1p5, чтобы в случае выхода из строя одного диска, можно было загрузиться с другого.
# mount /dev/nvme0n1p5 /mnt
Проверяю содержимое, там то же самое, что сейчас в /boot/efi. На первый взгляд всё в порядке. Диски в рейде, efi разделы есть. На всякий случай проверяю grub, устанавливая его принудительно на оба диска.
# dpkg-reconfigure grub-pc
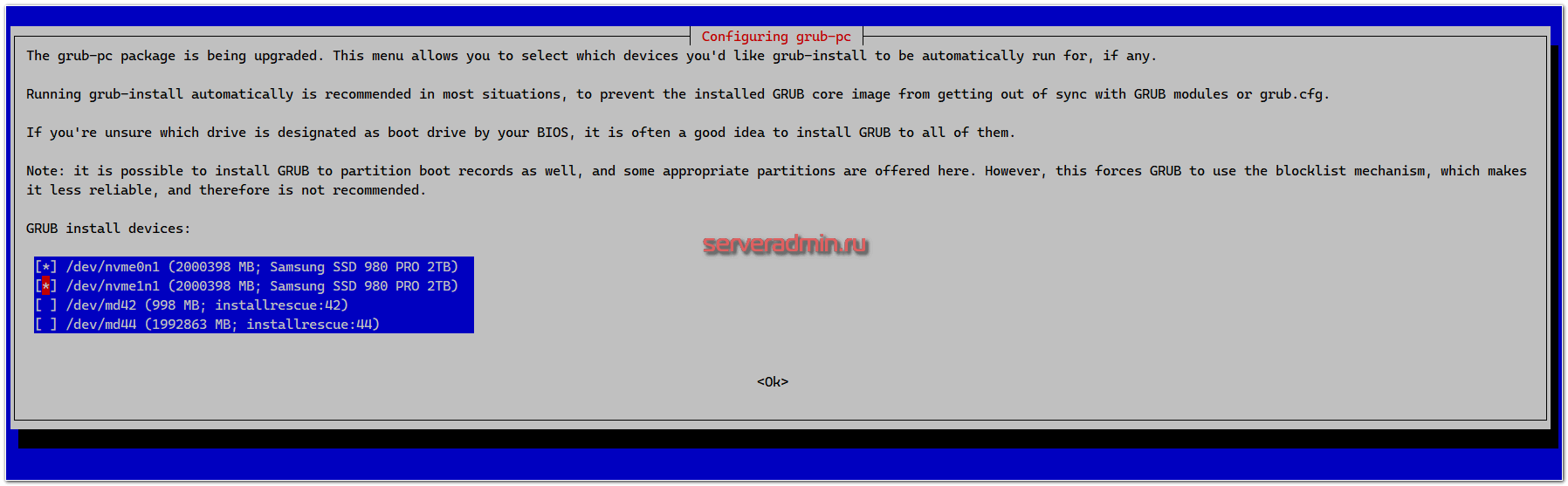
Проверяю всё это на всех трёх серверах. На этом же этапе имеет смысл дождаться синхронизации массивов mdadm и подёргать диски из сервера, если у вас к нему прямой доступ, убедиться, что он нормально это переживает и продолжает работать, загружаться. Потом стоит отработать отказ одного из диска и мероприятия по его замене. Я всё это уже много раз проделывал в том числе и на арендных серверах Selectel, так что не буду это делать. Это тема отдельной статьи.
Предварительная настройка системы перед установкой кластера
Выполню ряд стандартных действий, которые я обычно делаю при настройке сервера. Первым делом всё обновляю:
# apt update # apt upgrade
Если увидите ошибку:
The following packages have unmet dependencies:
pve-firmware : Conflicts: firmware-linux-free but 20200122-1 is to be installed
E: Broken packages
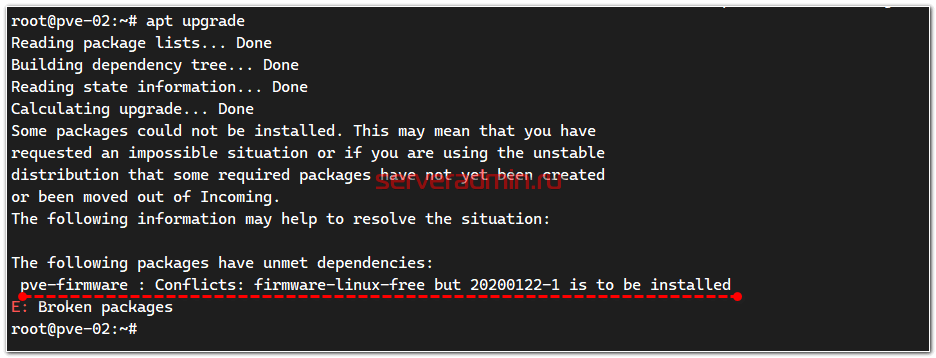
Не пугайтесь. Это нормальная история, если Proxmox устанавливали поверх Debian. Достаточно просто удалить стандартное ядро:
# apt remove firmware-linux-free linux-image-amd64
Теперь можно выполнить обновление ещё раз, ошибки не будет. Далее ставлю стандартный софт, который обычно использую:
# apt install mc htop net-tools iftop tmux
Проверяю время, часовой пояс, синхронизацию времени:
# timedatectl
Если что-то не настроено или настроено не так, то измените. Меня всё устроило.
По умолчанию на серверах настроен только один внешний интерфейс на eth0 или enp14s0. Мне надо объединить серверы по внутренней сети. Возьму адресацию 192.168.100.0/24 для нод кластера и 10.1.0.0/24 для виртуальных машин.
# ip a add 192.168.100.2/24 dev eth1 # ip link set eth1 up
Соответственно выполняю это на всех трёх серверах, не забывая менять IP адреса. Убеждаемся, что сервера видят друг друга по внутренней сети. Если всё в порядке, добавляем эти параметры в /etc/network/interfaces:
auto eth1
iface eth1 inet static
address 192.168.100.1/24
И дополнительно настроим на серверах локальные DNS записи в файлах /etc/hosts, чтобы узлы могли обращаться друг к другу по именам, а не IP адресам. Если у вас используется централизованный DNS сервер, то разумнее будет сделать это там. Но в данном случае у меня тестовое изолированное окружение из трёх серверов, поэтому добавляю в hosts каждого сервера идентичные записи:
192.168.100.1 pve-01 192.168.100.2 pve-02 192.168.100.3 pve-03
Все эти действия по первоначальной настройке вы можете выполнить ещё на этапе установки ОС в панели управления. Как я уже говорил, там есть поле для своих bash скриптов. Либо используйте свои роли ansible уже после получения доступа к системе.
Отдельно отмечу, что Proxmox Cluster предъявляет определённые требования к отклику внутри сети, по которой будет происходить синхронизация. Требуется отклик не более 5 миллисекунд (The Proxmox VE cluster stack requires a reliable network with latencies under 5 milliseconds (LAN performance) between all nodes to operate stably).
Перезагружаем сервера, чтобы убедиться, что всё в порядке, сервера стартуют, нигде критических ошибок нет. Только дождитесь окончания синхронизации mdadm, иначе она собьётся и после перезагрузки начнётся сначала.
Настройка кластера Proxmox VE из трёх нод
Теперь можно переходить в веб интерфейс Proxmox VE и все дальнейшие настройки делать там. В принципе, там же можно настроить и сеть на хостах, но я предпочитаю это делать и проверять в консоли.
Напомню, что в веб интерфейс можно попасть по IP адресу сервера на порту 8006. Подключиться можно по всем доступным IP адресам, если вы не настраивали ограничения. Я советую это сделать, но не буду затрагивать эту тему в рамках данной статьи, чтобы не раздувать её. И так объёмная получается. Плюс, ограничения зависят от вашей конфигурации сети. Возможно вам будет достаточно ограничивать соединения на уровне пограничного маршрутизатора, а сами хосты с PVE не трогать.
Приступаем к созданию кластера Proxmox. Делать это можно с любой ноды будущего кластера. Я для удобства всё буду делать с хоста pve-01. Идём в веб интерфейс, в раздел Datacenter ⇨ Cluster и жмём Create Cluster.
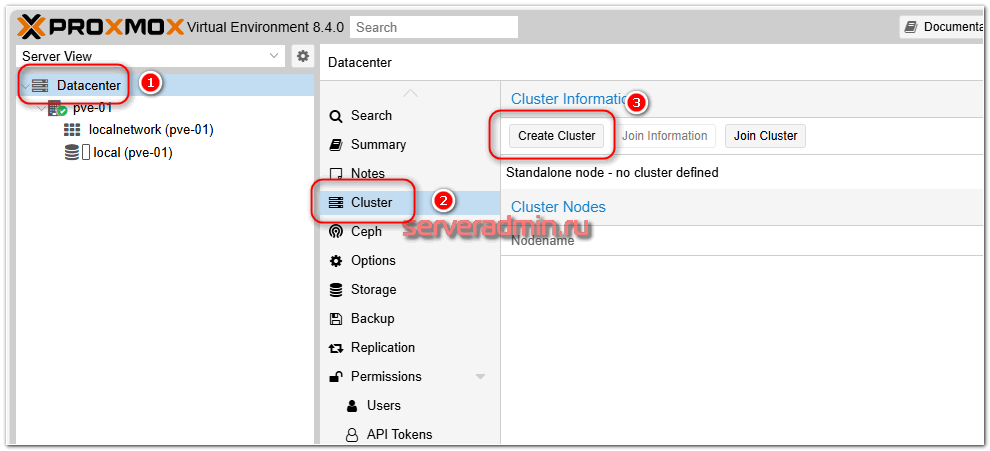
Указываем имя кластера и интерфейс, на котором он будет работать. В моём случае это будет локальный интерфейс для межкластерного взаимодействия.
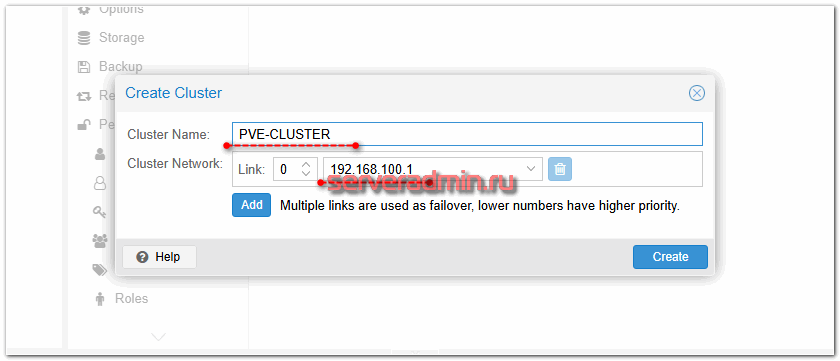
Не выходя из этого раздела, нажимаем рядом на кнопку Join Information и копируем информацию. Она нам будет нужна для присоединения других нод к кластеру.
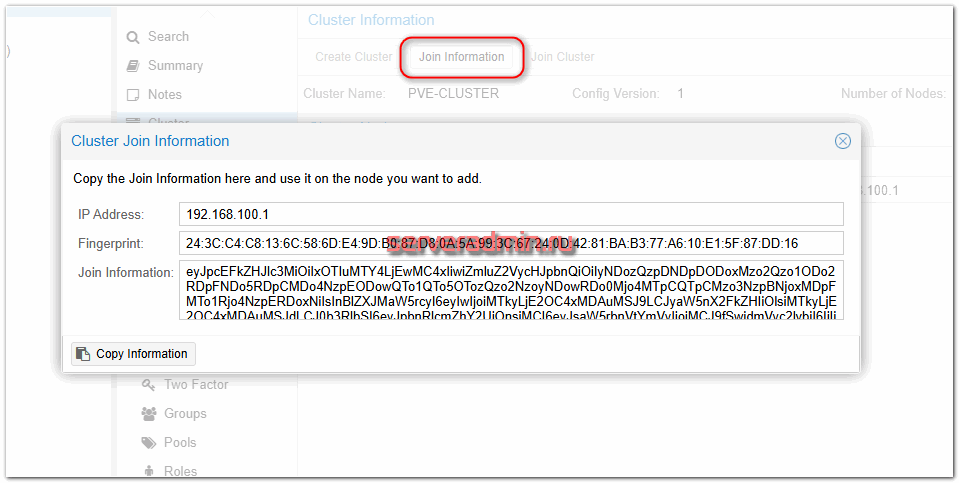
Теперь идём в веб интерфейс на остальные ноды кластера, переходим в раздел Datacenter ⇨ Cluster и жмём Join Cluster. Вводим полученную ранее информацию и подключаем ноду к кластеру.
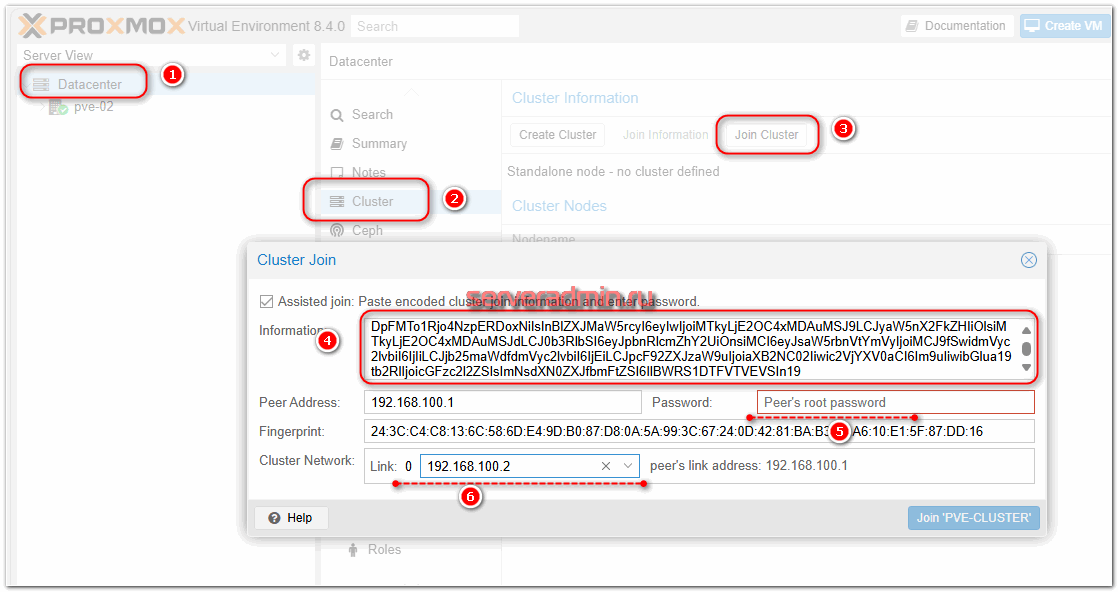
Здесь нужно будет указать root пароль от первой ноды, где мы создавали кластер. И не забудьте выбрать на всех нодах внутреннюю сеть из указанного вами диапазона.
После подключения нод к кластеру, меня разлогинивало из веб интерфейса. При повторном заходе на любую из нод, я видел все ноды кластера.
На этом создание непосредственно кластера на базе Proxmox VE закончено. Тут же в веб интерфейсе можно посмотреть логи. Там не должно быть ошибок. Можно зайти в консоль сервера и посмотреть там статус кластера:
# pvecm status
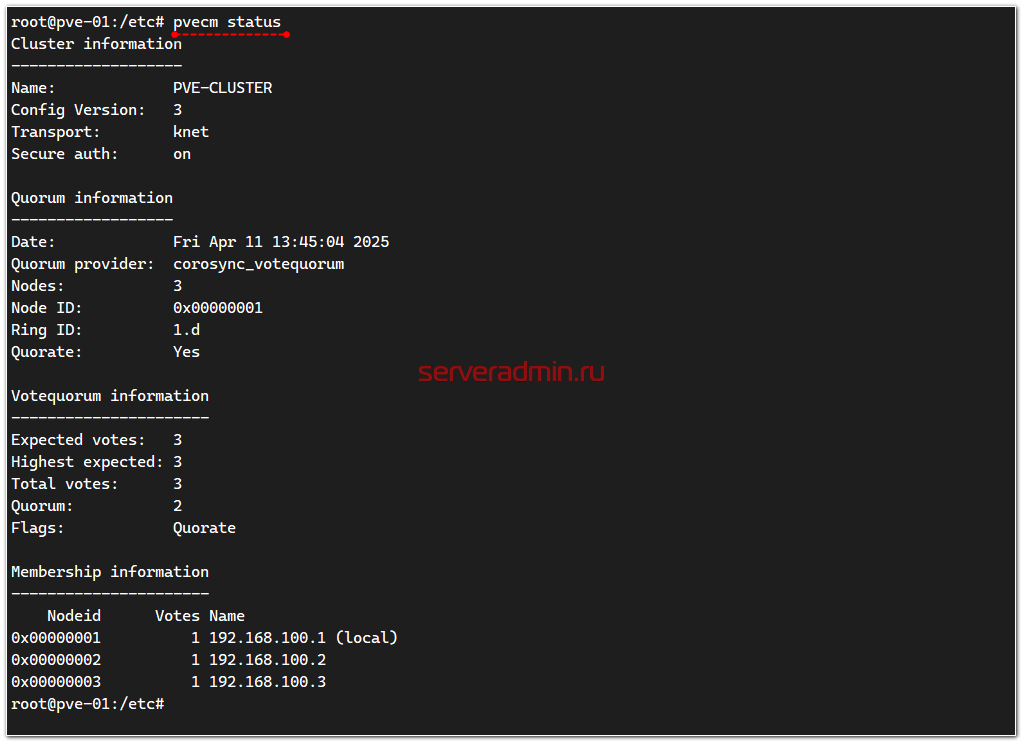
В настоящий момент кластер не отказоустойчивый, так как у него нет общего хранилища для виртуальных машин. Их можно переносить между нодами в рамках кластера только вручную, запуская миграцию. Создадим одну виртуальную машину, которая будет служить шлюзом для виртуальных машин, которые будут работать в кластере.
Настройка сети для виртуальных машин Proxmox
Скачиваем на одну из нод, у меня это будет первая, pve-01, образ системы и разворачиваем её. Я возьму ОС Debian. Тут сразу же на первый план встаёт вопрос сетевых настроек для этой виртуальной машины. Решение будет сильно зависеть от топологии вашей сети, где работает кластер.
У меня ситуация лабораторная: есть 3 сервера, где у каждого свой выход в интернет через внешний роутер. Причём у каждого свой. Скорее всего у вас будет не так, и будет какой-то один внешний шлюз. Особенно если кластер разворачивается локально на своём железе. Если же железо арендное, то лучше этот вопрос отдельно решить, исходя из возможностей хостера. Чаще всего они предлагают отдельную услугу в виде внешнего шлюза и файрвола. У Селектел такая услуга тоже есть, называется Глобальный роутер. Причём для наших задач она будет бесплатной, но её настройку я не буду рассматривать в рамках этой статьи, так как это отдельная тема для разговора. Сейчас хочется сфокусироваться непосредственно на кластере.
Как я уже сказал, у меня каждый сервер имеет свой независимый выход в интернет, плюс все серверы объединены в единую локальную сеть по одному сетевому интерфейсу. Для кластера идеальный вариант, когда есть один физический интерфейс для работы кластера, второй – для работы виртуальных машин.
В моём случае сеть кластера и сеть для виртуальных машин физически одна, подключена через интерфейсы eth1, поэтому проще всего создать обычный сетевой Linux Bridge на базе локальных сетевых интерфейсов и дальше уже использовать этот бридж и для связи нод кластера, и для связи виртуальных машин.
Я сделал в итоге вот так.
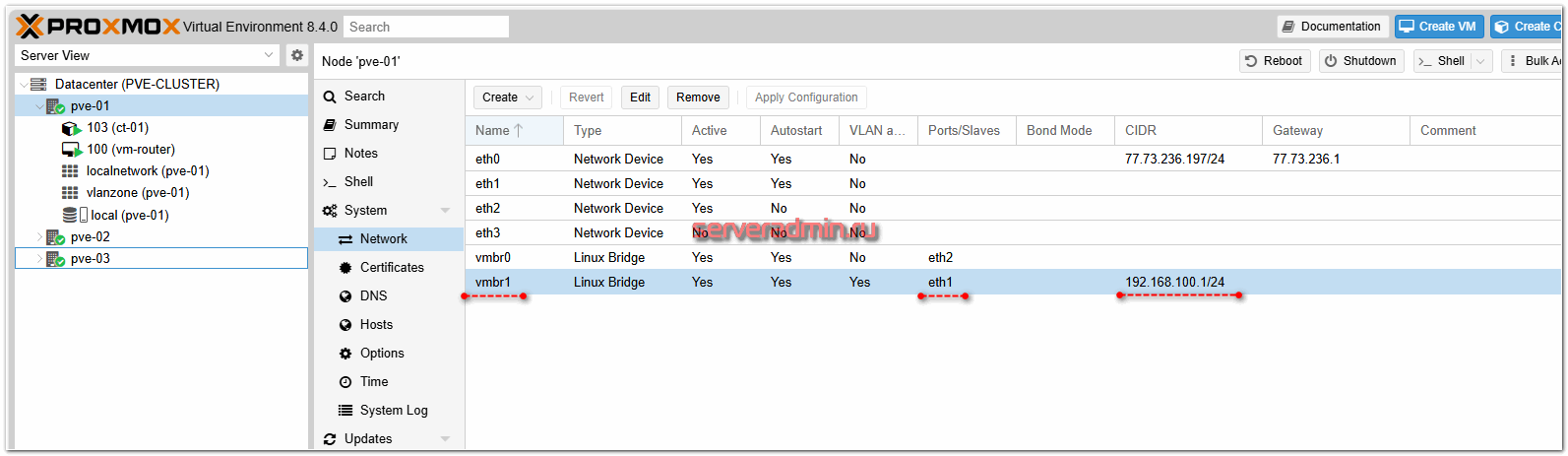
Дальше у нас тоже несколько вариантов настройки кластерной сети для локальных машин. Самый простой – добавлять виртуальным машинам сетевой бридж vmbr1 и использовать единое адресное пространство для нод кластера и виртуальных машин. Они будут спокойно перемещаться по нодам кластера без каких-либо проблем и изменения сетевых настроек.
Другой вариант – использовать VLAN и разграничивать доступ между нодами и виртуальными машинами, чтобы последние не видели сеть самого кластера. Например, как я сказал вначале, использовать одну подсеть для нод кластера, другую – для виртуальных машин. Причём для виртуальных машин машин подсетей и соответственно разных VLAN может быть много. Показываю, как это настроить с помощью Proxmox SDN.
Proxmox SDN для настройки VLAN в кластере
Идём в раздел Datacenter -> SDN -> Zones и добавляем новую зону типа VLAN.
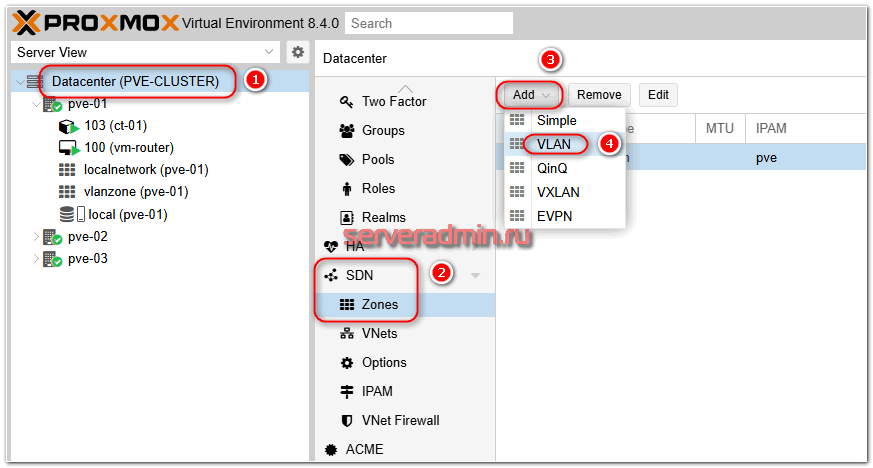
Указываем бридж vmbr1, у вас он может по-другому называться. Это должен быть бридж, связанный с сетевым интерфейсом, по которому доступны ноды кластера.
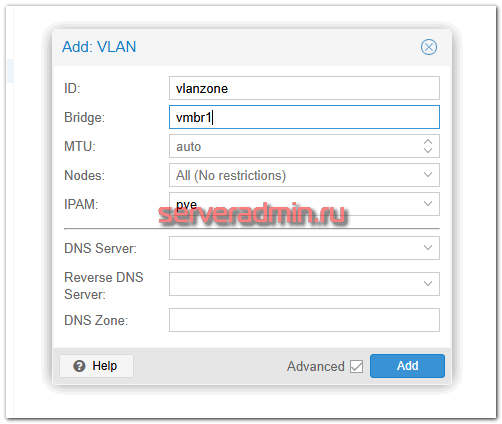
Потом идём в раздел VNets и добавляем в эту зону подсеть.
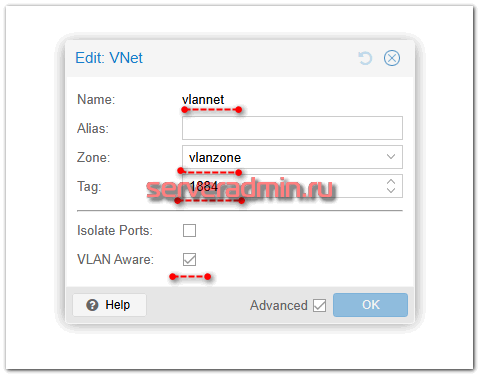
Указываете любое название, выбираете любой Tag, и обязательно ставите галочку VLAN Aware. Сохраняете сеть. Подсети я к ней не добавляю. Не очень люблю раздавать сетевые настройки средствами гипервизора. Тогда придётся бэкапить и его. Предпочитаю создать сетевую связность, поднять шлюз в виртуальной машине и дальше управлять сетью (DHCP, DNS, VPN и т.д.) через него. Бэкап виртуальной машины со шлюзом обеспечит сохранение всех сетевых настроек. Не нужно будет бэкапить настройки гипервизора.
Если вы ранее ещё не использовали настройки SDN, то вам нужно выполнить некоторые действия на нодах кластера. На каждой ноде нужно в конец файла /etc/network/interfaces добавить строку:
source /etc/network/interfaces.d/*
Ничего дополнительно делать не надо. Теперь настройки SDN можно применить. Идём в веб интерфейс, в раздел SDN и нажимаем Apply. Дожидаемся применения настроек на всех нодах кластера:
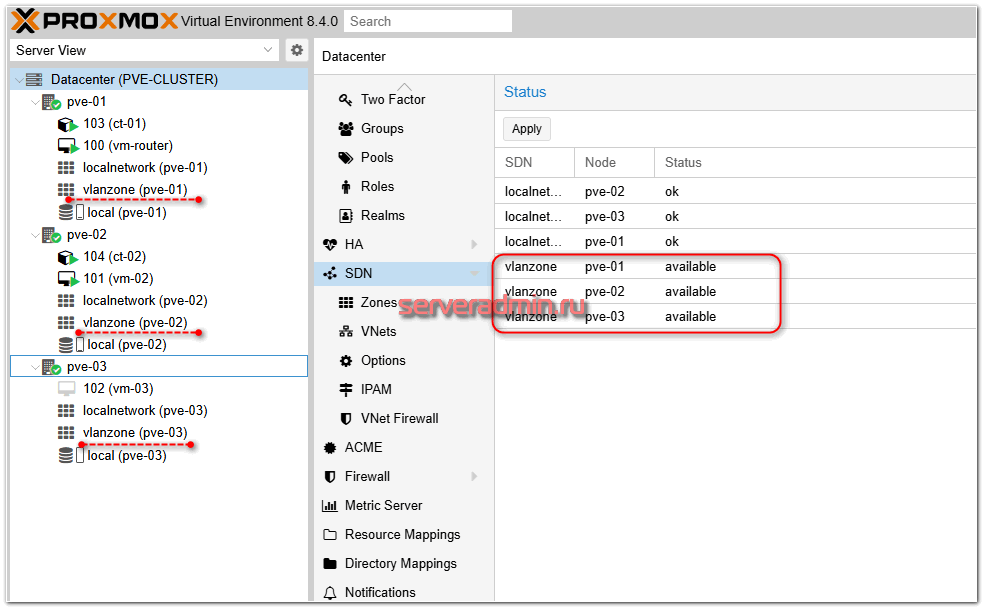
Добавленная зона должна появиться на всех нодах кластера. Теперь в настройках виртуальной машины в качестве сетевого интерфейса можно добавить эту зону. Если не указывать VLAN Tag, то будет использовать тот, что указан в SDN. Если же у разных виртуальных машин указать разные тэги, то они окажутся в разных VLAN.
Для своего роутера я добавил 2 сетевых интерфейса:
- vmbr1, чтобы он был связан с сетью хоста и мог выходить через него в интернет
- vlannet, для связи с виртуальными машинами в их vlan
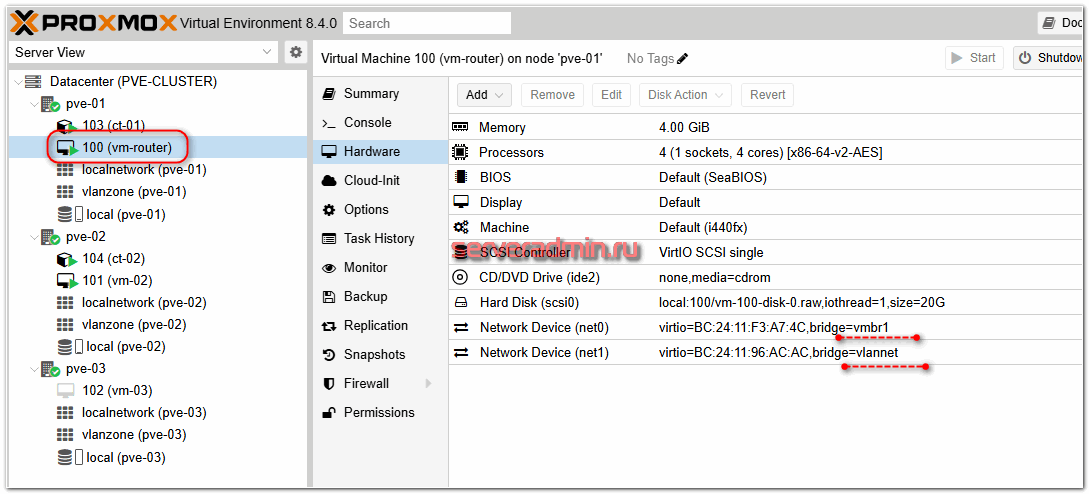
Для того, чтобы с такой конфигурацией сети виртуальная машина получила доступ в интернет через сеть хоста, у него нужно сделать несколько настроек. Сделать это нужно на всех нодах кластера, чтобы шлюз при переезде мог работать на любой из нод. На каждой ноде делаем следующие настройки.
Разрешаем форвард пакетов между сетевыми интерфейсами. Для этого добавляем в файл /etc/sysctl.conf параметр:
net.ipv4.ip_forward=1
Он там уже есть, достаточно раскомментировать. Сохраняем файл и применяем настройки:
# sysctl -p
Добавляем в Iptables правило NAT для всех из подсети 192.168.100.0/24. На шлюзе на одном из сетевых интерфейсов будет адрес из этой подсети для выхода в интернет.
# iptables -t nat -A POSTROUTING -s '192.168.100.0/24' -o eth0 -j MASQUERADE
В данном случае eth0 – интерфейс, через который ноды выходят в интернет. Для того, чтобы это правило применялось после загрузки, добавим его в /etc/network/interfaces в настройки vmbr1:
auto vmbr1 iface vmbr1 inet static address 192.168.100.1/24 bridge-ports eth1 bridge-stp off bridge-fd 0 bridge-vlan-aware yes bridge-vids 2-4094 post-up iptables -t nat -A POSTROUTING -s '192.168.100.0/24' -o eth0 -j MASQUERADE
Обратите внимание на параметр bridge-vlan-aware yes. Так как у меня vlan работают поверх этого бриджа, данная настройка там должна присутствовать. Ну и не забудьте поменять IP адрес в соответствии с нодой кластера. Эти настройки надо сделать на каждой из них.
Теперь можно установить и настроить виртуальную машину. На сетевом интерфейсе с vmbr1 внутри виртуальной машины я сделал адрес 192.168.100.100. Через него VM выходит в интернет и видит ноды кластера. В качестве шлюза указан IP адрес ноды 192.168.100.1, на которой она запущена. При переезде на другую ноду интернет на этой VM пропадёт, так как там уже будет другой адрес, 192.168.100.2 или 192.168.100.3. Это издержки моей текущей тестовой конфигурации, где каждая нода имеет свой выход в интернет. В идеале шлюз для выхода в интернет должен быть один, общий для всего кластера. Либо внутри виртуалки нужно будет делать проверку доступности шлюзов и автоматически переключаться на тот, который доступен. Это нетрудно сделать на базе обычного bash скрипта в cron.
VLAN внутри кластера Proxmox не работает
C VLAN могут быть некоторые проблемы и непонятки. Самая популярная – это когда VLAN между нодами кластера не работает. Внутри одного хоста всё нормально, разные тэги VLAN ограничивают доступ между виртуальными машинами. То есть всё работает ожидаемо. А между нодами кластера тэгированный трафик не ходит.
Чаще всего это связано с настройками коммутаторов. VLAN-трафик нужно явно разрешить на коммутаторах и физических интерфейсах. Если свитч не пропускает нужный VLAN, трафик от VM из этой VLAN не попадёт на другую ноду. В локальной сети Selectel между серверами у меня получилась именно такая история. Доступа к настройкам свитча нет. Через техподдержку не захотел решать вопрос, так как это время и в рамках тематики данной статьи не имеет принципиального значения.
Если доступ к сетевому оборудованию у вас есть и вы всё аккуратно настроите, то работать будет. Тема довольно популярно и хорошо представлена как в текстовом виде, в том числе в документации Proxmox, так и в обучающих роликах на Youtube. Настройка сильно зависит от вашей сетевой архитектуры, поэтому нет смысла акцентировать внимание на этих частностях. Если кластер небольшой, то возможно вам VLAN и не нужен будет. Я в итоге для простоты сеть кластера объединил с сетью виртуальных машин в рамках одной подсети 192.168.100.0/24 на базе vmbr1 а от VLAN отказался.
Миграция виртуальной машины в кластере Proxmox
Вернёмся к нашему кластеру. Мы его создали, настроили сеть, добавили виртуальные машины. Так как у нас нет общего хранилища, в данный момент перемещать машины между нодами можно только с помощью миграции.
Для миграции нужно в VM выбрать соответствующий раздел меню:
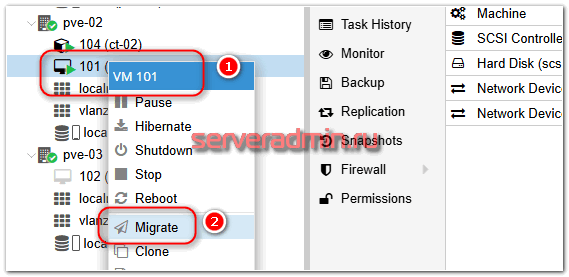
Откроется соответствующее окно, где нужно будет выбрать ноду кластера, куда будем переезжать:
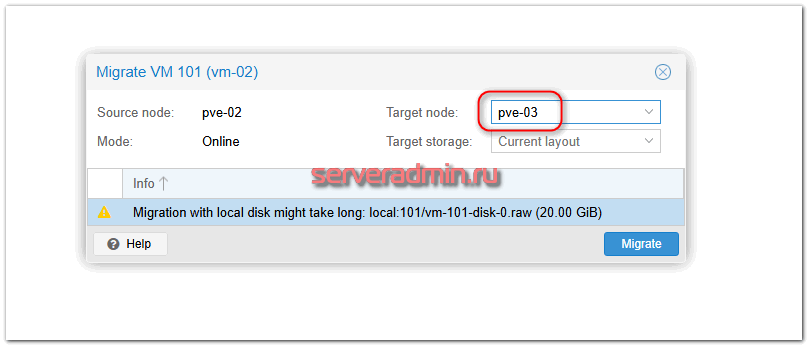
Для переезда останавливать машину не обязательно. Простой будет минимальный. А время переезда будет зависеть от размера дисков виртуальной машины и скорости локальной сети кластера. Идеально, конечно, его строить на скоростях 10Гбит/c и выше. Для небольших кластеров, как моего, хватит и гигабита.
После миграции можете зайти в виртуальную машину и убедиться, что она не перезагружалась. То есть переехала без остановки. Была небольшая заморозка на пару секунд.
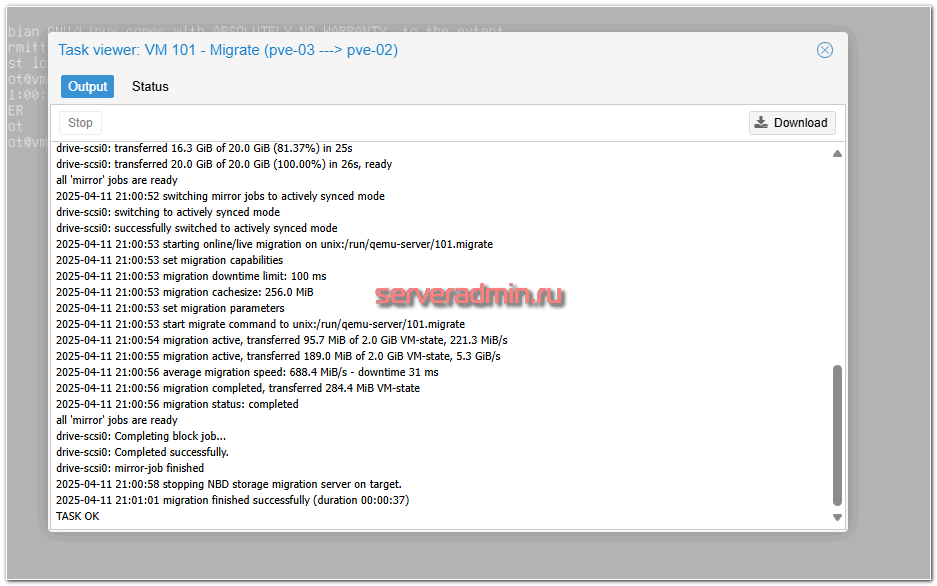
Подключение сетевых дисков iSCSI в качестве общего хранилища кластера Proxmox
Для построения полноценного HA кластера, который будет автоматически перезапускать виртуальные машины на работающей ноде в случае выхода из строя одной из них, необходимо использовать общее файловое хранилище. Оно должно быть подключено к каждой ноде кластера, а виртуальные машины размещены на нём.
Реализаций подобного хранилища может быть много. Это может быть какая-то СХД, предоставляющая блочные устройства по iSCSI или NFS, распределённое сетевое хранилище на базе Ceph или что-то ещё.
В рамках этой статьи я рассмотрю что-то ещё в виде сетевых дисков Selectel, которые можно купить как обычную услугу провайдера. Это максимально простой и быстрый вариант, который снимает с вас головную боль по настройке и поддержке хранилища, но, соответственно, стоит каких-то денег в зависимости от желаемого объёма и скорости дисков.
Сетевые диски решают важную задачу, с которой часто сталкиваются те, кто отдаёт предпочтение аренде железа, а не покупке облачных ресурсов. Вы зажаты в рамках платформы, а иногда и конфигурации конкретного сервера. Информация имеет свойство накапливаться и в какой-то момент вам может не хватить внутреннего хранилища. И решения зачастую может не быть, кроме как переезд. Я сам лично с этим сталкивался не раз.
В случае с арендой сетевых дисков вы можете очень быстро масштабироваться по объёму, как это обычно бывает в облаке, но при этом у вас своё железо и полная изоляция с этого уровня, а значит предсказуемая производительность. Это позволяет, к примеру, наращивать объём хранилища для обучения ML-моделей, которые требуют значительный объём дискового пространства. Также вы можете очень быстро и просто поднимать временные тестовые среды с необходимым объёмом хранения, а потом просто отключать его, когда он не нужен и не платить за неиспользуемый объём.
Подключение гибких производительных или медленных сетевых дисков к выделенным серверам является неким компромиссом и переходным вариантом между полностью своим железом и полностью арендным в облаке. Получается более функциональный и бюджетный гибрид услуг.
Для подключения сетевого диска необходимо зайти в панель управления Selectel, выбрать сервер, перейти на вкладку Сетевые диски и заказать его.
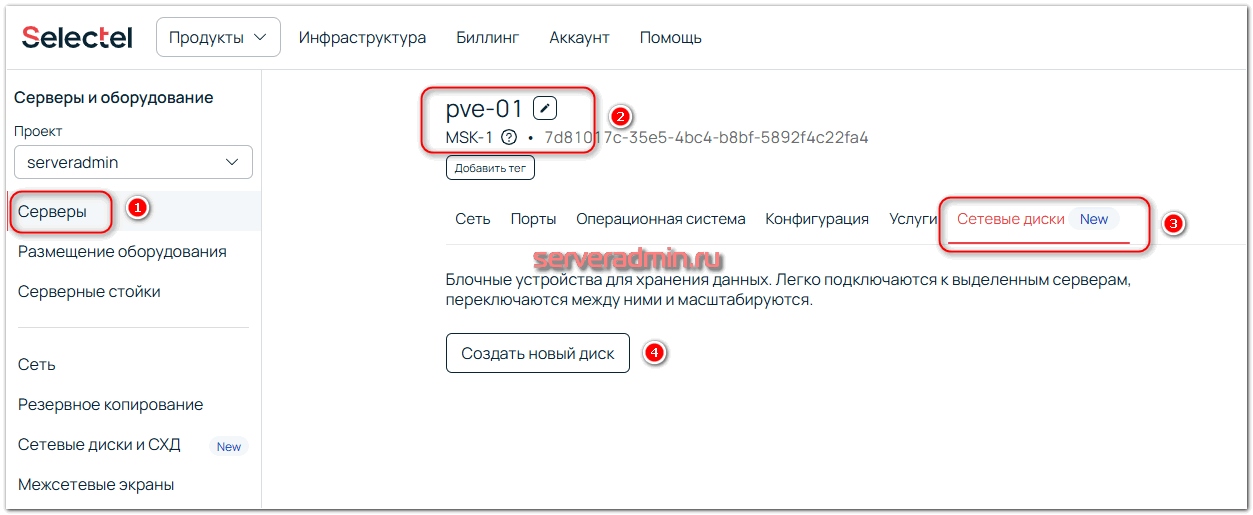
Далее можно ознакомиться с основными возможностями дисков и сделать заказ.
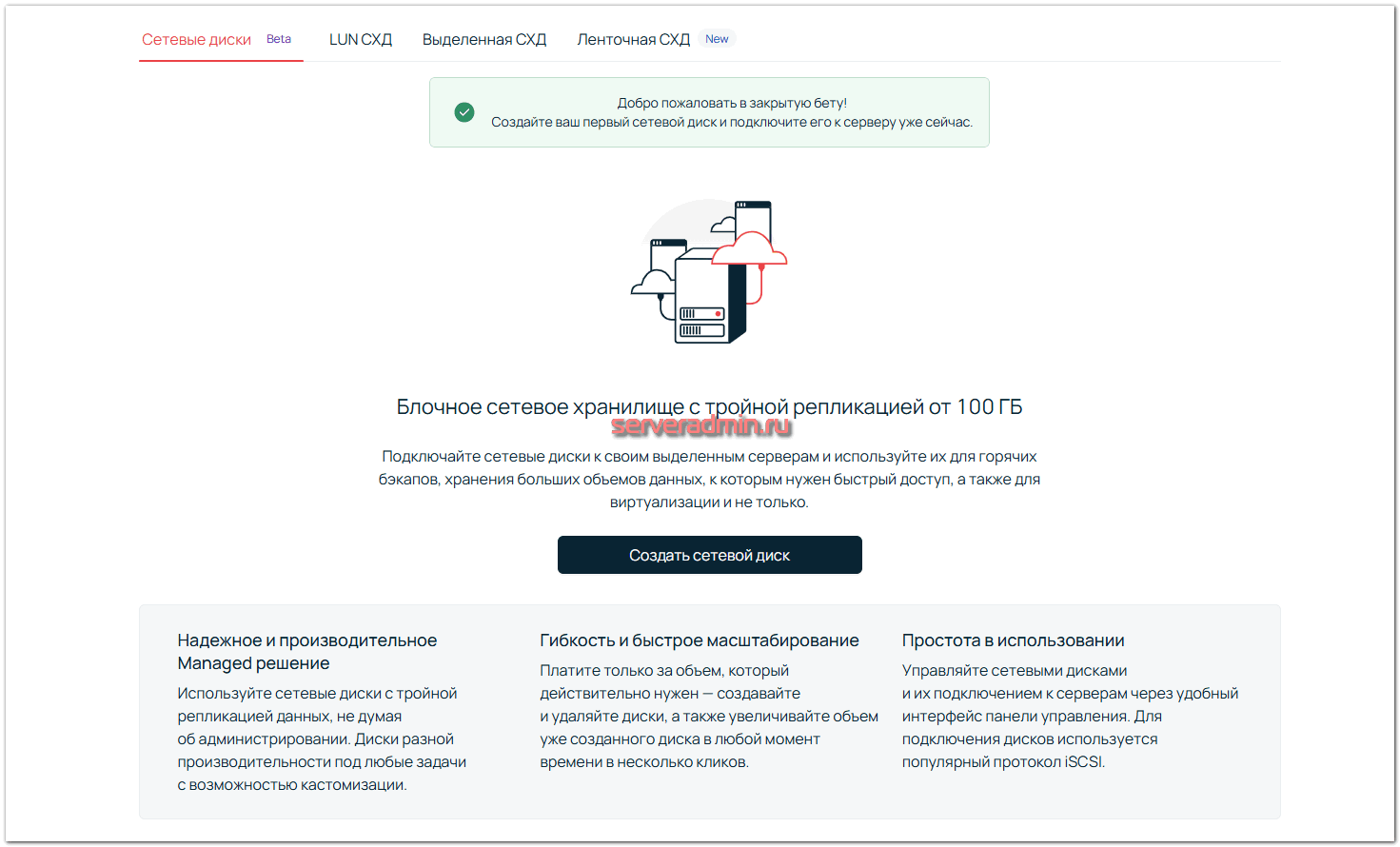
Во время заказа можно указать тип диск и его объём. В момент написания этой статьи были доступны 2 типа дисков:
- Базовый HDD с параметрами 150-320 IOPS и скорость записи 100 МБ/c
- Быстрый SSD c параметрами 15000-25000 IOPS и скоростью 500 МБ/c
Диски подключены к сети серверов портами со скоростью 10Гбит/c.
Сразу сделаю важную ремарку. Сетевые диски – это всегда более низкая скорость записи и очень большая разница в отклике по сравнению с локальными дисками. Отклик будет в разы выше. И это практически не зависит от технической реализации подключения сетевых дисков. Если у вас есть необходимость в большой производительности дисковой подсистемы, то планируйте архитектуру своих информационных систем так, чтобы можно было использовать локальные диски. Тем более сейчас разница между современными локальными NVME дисками и сетевыми будет значительна. Например, реализация хранилища на базе Ceph никогда не приблизится к производительности NVME дисков, даже если вы кластер соберёте из них. Скорости будут такие, что достаточно дисков SATA. Выжать скорость из NVME дисков Ceph просто не сможет из-за ограничений своей архитектуры. Это стабильное, проверенное, production-ready решение, но небыстрое. Нужно это понимать.
Для подключения сетевого диска к выделенному серверу, нужно создать SAN-сеть. Сделать это можно в интерфейсе управления созданным диском.
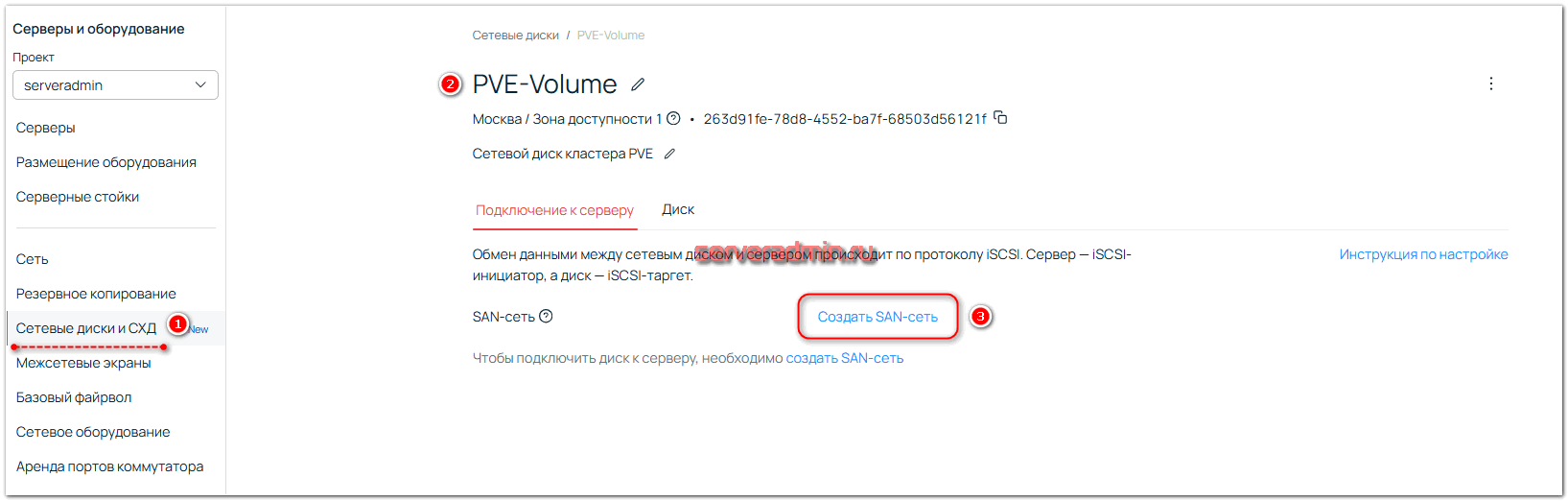
Я не менял предложенные по умолчанию значения. Добавил, как есть:
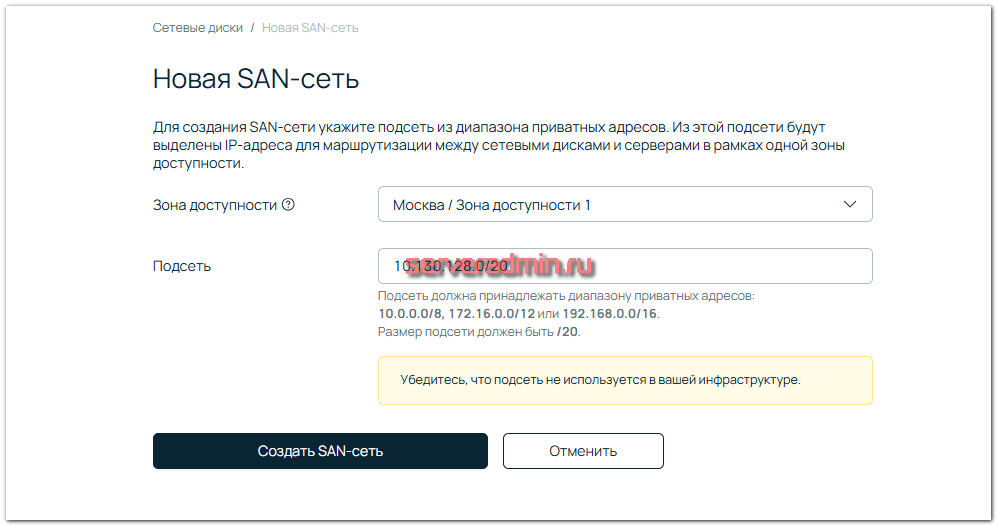
После создания SAN сети вы увидите IP адреса каждого сервера в ней. Мои сервера были подключены двумя сетевыми адаптерами в эту сеть.
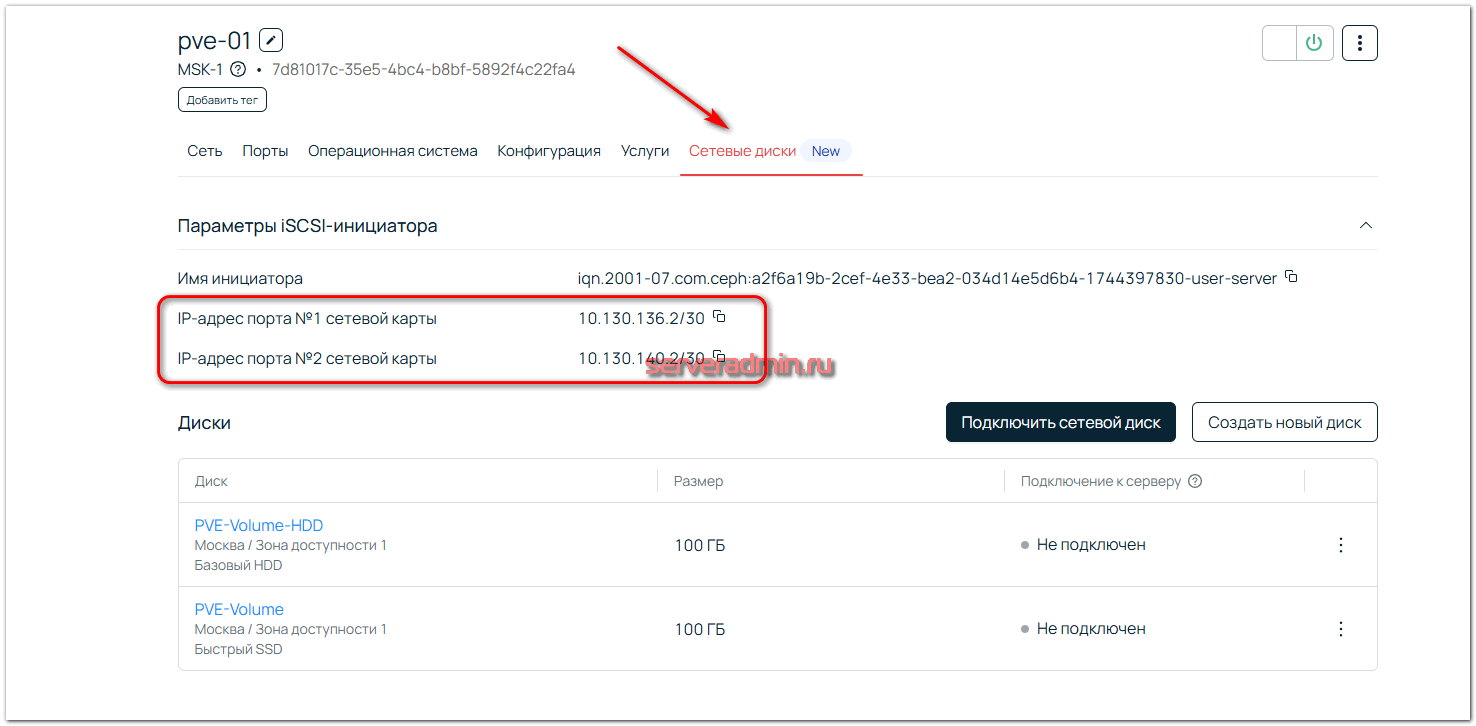
Понять на сервере, какие это интерфейсы, можно посмотрев их скорость. Доступ к сетевым дискам осуществляется по сети 10Гбит/c.
# ethtool eth2 | grep -i speed Speed: 10000Mb/s # ethtool eth3 | grep -i speed Speed: 10000Mb/s
Два других интерфейса будут гигабитными. Настраиваем IP адреса SAN сети на всех серверах. Полные настройки есть в разделе с сетевыми дисками, в описании каждого диска:
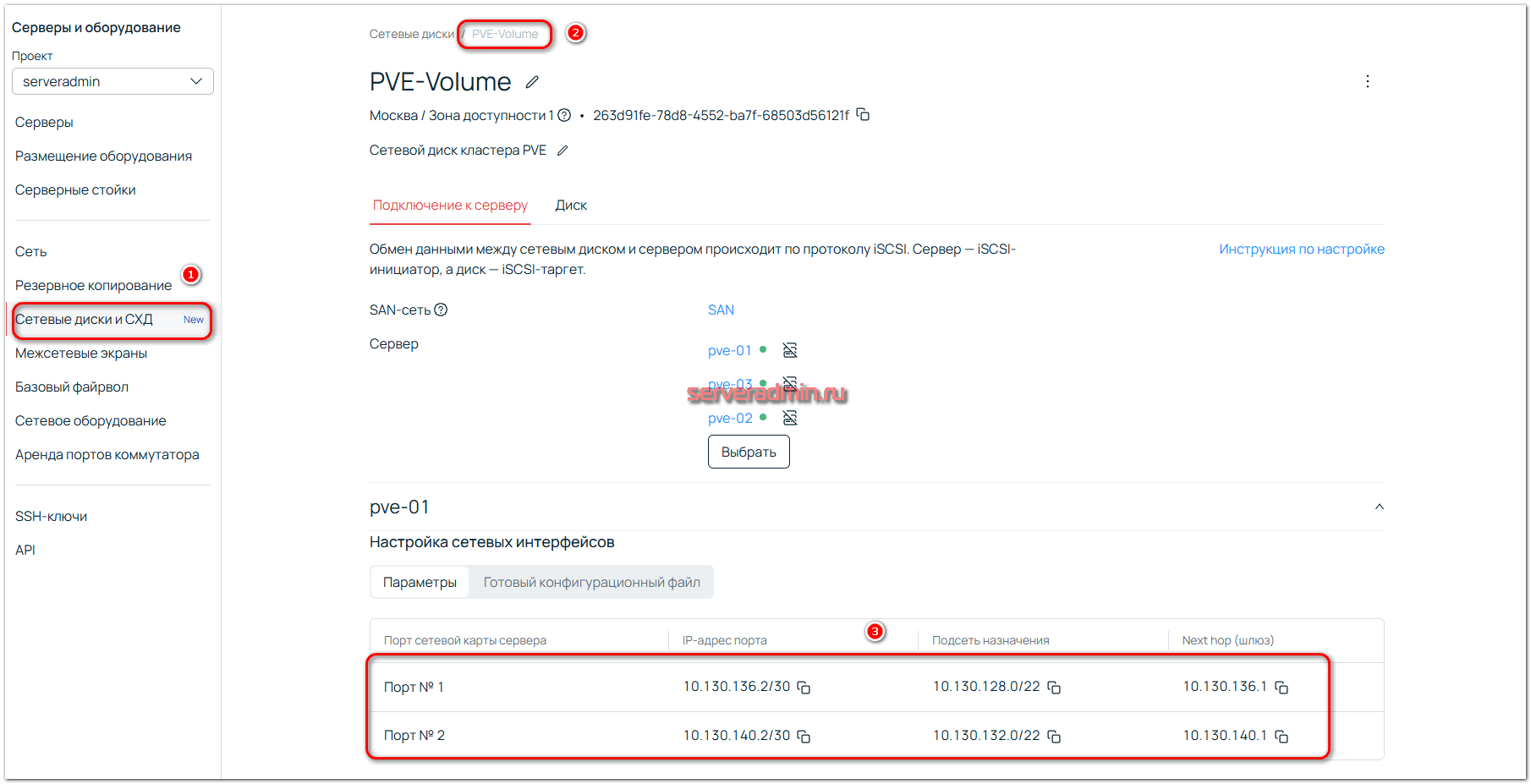
Нам нужно не только настроить IP адреса, но и добавить через интерфейсы SAN сети маршруты к серверам сетевых дисков. Сделать это можно разными способами. Я сделал через настройки в файле /etc/network/interfaces:
auto eth2 iface eth2 inet manual address 10.130.140.2/30 post-up ip route add 10.130.132.0/22 via 10.130.140.1 auto eth3 iface eth3 inet manual address 10.130.136.2/30 post-up ip route add 10.130.128.0/22 via 10.130.136.1
Сделать это нужно на всех серверах. Обращаю внимание, что для каждого сервера будут свои настройки IP адреса, шлюза и маршрутов. Посмотрите их, открывая вкладки для каждого сервера в информации о сетевом диске.
После того, как настроите сеть, можно подключать сетевые диски. Для этого есть инструкция в документации. Она кажется немного замороченной, когда первый раз это делаешь, но в целом там всё стандартно для подключения диска по iSCSI в Linux. Самое главное не ошибиться в IP адресах и учётных данных. Они для каждого сервера свои и отображаются в соответствующих вкладках:
Можно воспользоваться готовым скриптом для подключения. Там уже будут прописаны все учётные данные. Он в целом рабочий, я его проверял, но нужно выполнить некоторые предварительные действия, так как скрипт написан для Ubuntu, а у нас под капотом Proxmox – Debian. Скорее всего скоро появятся скрипты и под другие популярные системы. Услуга только появилась.
Покажу набор команд для одного сервера, с помощью которого можно подключить к нему сетевые диски. Команды будут актуальны для любых дисков, подключаемых через iSCSI с аутентификацией. Все они взяты из инструкции, ссылка на которую приведена выше:
# apt install multipath-tools
Создаём конфигурацию для службы multipath в файле /etc/multipath.conf:
defaults {
user_friendly_names yes
find_multipaths yes
}
blacklist {
}
Перезапускаем службу и добавляем в автозагрузку:
# systemctl enable multipathd.service # systemctl restart multipathd.service
Добавляем в файл /etc/iscsi/initiatorname.iscsi наше имя инициатора, которое указано в панели управления дисками:
InitiatorName=iqn.2001-07.com.ceph:a2f6a19b-2cef-4e33-bea2-034d14e5d6b4-1744397830-user-server
Перезапускаем службу:
# systemctl restart iscsid.service
Создаём iSCSI-интерфейсы:
# iscsiadm -m iface -I eth2 --op new # iscsiadm -m iface -I eth3 --op new
Привязываем iSCSI-интерфейсы к сетевым интерфейсам, которые настроили:
# iscsiadm -m iface --interface eth2 --op update -n iface.net_ifacename -v eth2 # iscsiadm -m iface --interface eth3 --op update -n iface.net_ifacename -v eth3
Проверяем доступность iSCSI-таргета через интерфейсы iSCSI:
# iscsiadm -m discovery -t sendtargets -p 10.130.128.2 --interface eth3 # iscsiadm -m discovery -t sendtargets -p 10.130.132.2 --interface eth2
Настраиваем CHAP-аутентификацию на iSCSI-Initiator:
# iscsiadm --mode node -T iqn.2001-07.com.ceph:a2f6a19b-2cef-4e33-bea2-034d14e5d6b4-1744395738-user-target -p 10.130.128.2 --op update -n node.session.auth.authmethod --value CHAP # iscsiadm --mode node -T iqn.2001-07.com.ceph:a2f6a19b-2cef-4e33-bea2-034d14e5d6b4-1744395738-user-target -p 10.130.132.2 --op update -n node.session.auth.authmethod --value CHAP # iscsiadm --mode node -T iqn.2001-07.com.ceph:a2f6a19b-2cef-4e33-bea2-034d14e5d6b4-1744395738-user-target --op update -n node.session.auth.username --value a2f6a19b-2cef-4e33-bea2-034d14e5d6b4-1744397830-user-server # iscsiadm --mode node -T iqn.2001-07.com.ceph:a2f6a19b-2cef-4e33-bea2-034d14e5d6b4-1744395738-user-target -p 10.130.128.2 --op update -n node.session.auth.password --value 5892f4c22fa4OAvW # iscsiadm --mode node -T iqn.2001-07.com.ceph:a2f6a19b-2cef-4e33-bea2-034d14e5d6b4-1744395738-user-target -p 10.130.132.2 --op update -n node.session.auth.password --value 5892f4c22fa4OAvW
Проходим аутентификацию на iSCSI-таргете через iSCSI-интерфейсы:
# iscsiadm --mode node -T iqn.2001-07.com.ceph:a2f6a19b-2cef-4e33-bea2-034d14e5d6b4-1744395738-user-target -p 10.130.128.2 --login --interface eth3 # iscsiadm --mode node -T iqn.2001-07.com.ceph:a2f6a19b-2cef-4e33-bea2-034d14e5d6b4-1744395738-user-target -p 10.130.132.2 --login --interface eth2
Проверяем, что iSCSI-сессия для каждого iSCSI-таргета запустилась:
# iscsiadm -m session tcp: [1] 10.130.128.2:3260,1 iqn.2001-07.com.ceph:a2f6a19b-2cef-4e33-bea2-034d14e5d6b4-1744395738-user-target (non-flash) tcp: [2] 10.130.132.2:3260,2 iqn.2001-07.com.ceph:a2f6a19b-2cef-4e33-bea2-034d14e5d6b4-1744395738-user-target (non-flash)
Включаем автоматическое подключение дисков при перезагрузке сервера:
# iscsiadm --mode node -T iqn.2001-07.com.ceph:a2f6a19b-2cef-4e33-bea2-034d14e5d6b4-1744395738-user-target -p 10.130.128.2 --op update -n node.startup -v automatic # iscsiadm --mode node -T iqn.2001-07.com.ceph:a2f6a19b-2cef-4e33-bea2-034d14e5d6b4-1744395738-user-target -p 10.130.132.2 --op update -n node.startup -v automatic
Проверяем, что диски появились в системе:
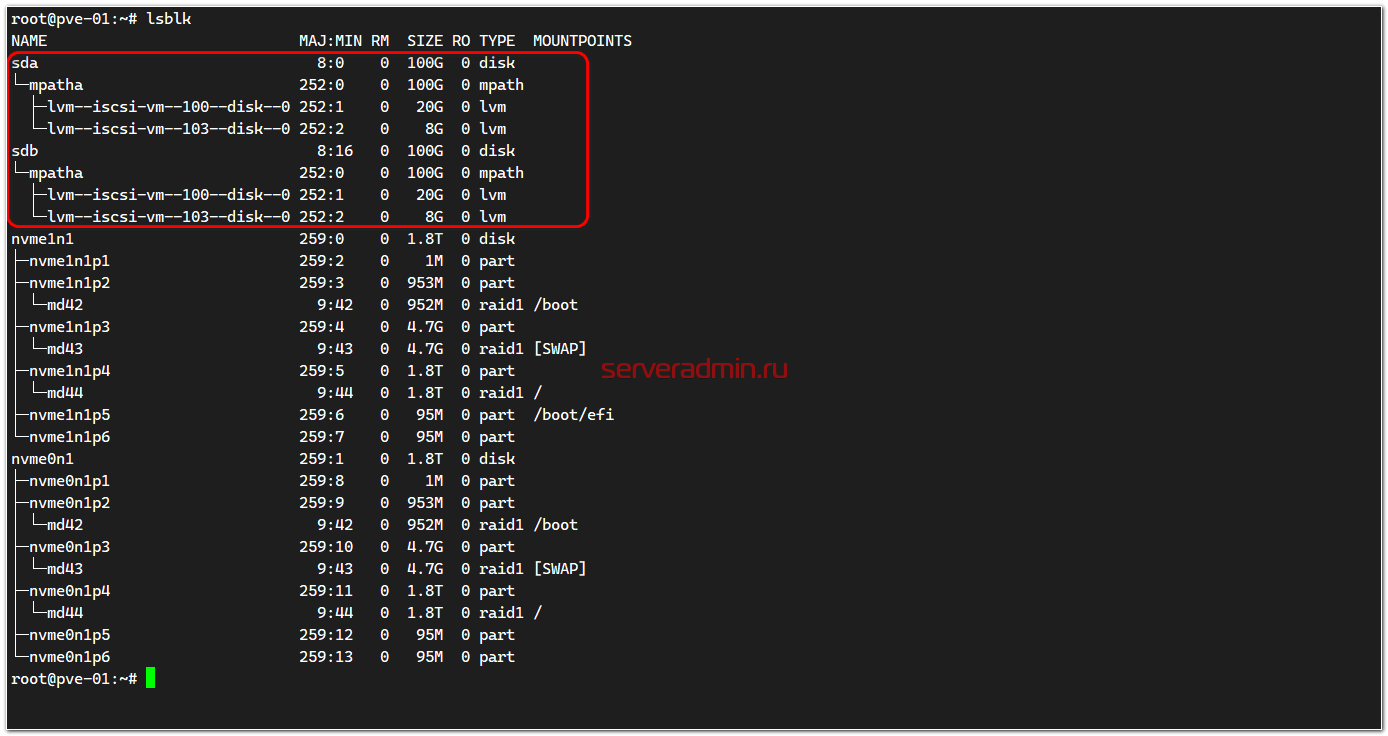
На моей картинке там уже размещены 2 виртуальные машины. Если диски только подключили, LVM разделов там не будет.
Подобные действия нужно выполнить на всех трёх серверах кластера. Когда это закончите, можно перемещаться в веб интерфейс кластера Proxmox и добавлять хранилище. Делаем это в разделе Datacenter ⇨ Storage. Добавляем новое хранилище типа iSCSI. Указываем следующие параметры:
- ID – любое название. Я свои диски назвал network0 и network1
- Portal - IP-адрес iSCSI-таргета, берём из панели управления диском
- Target - Имя таргета, берём из панели управления диском
- Nodes – указываем ноды, к которым подключаем этот диск. Если просто тестируете его, подключив пока к одному серверу, можете указать тут только его. Я вначале так и делал.
- Enable – активируем, ставим галку.
- Use LUNs Directly – отмечаем галкой, нам нужен именно такой режим работы.
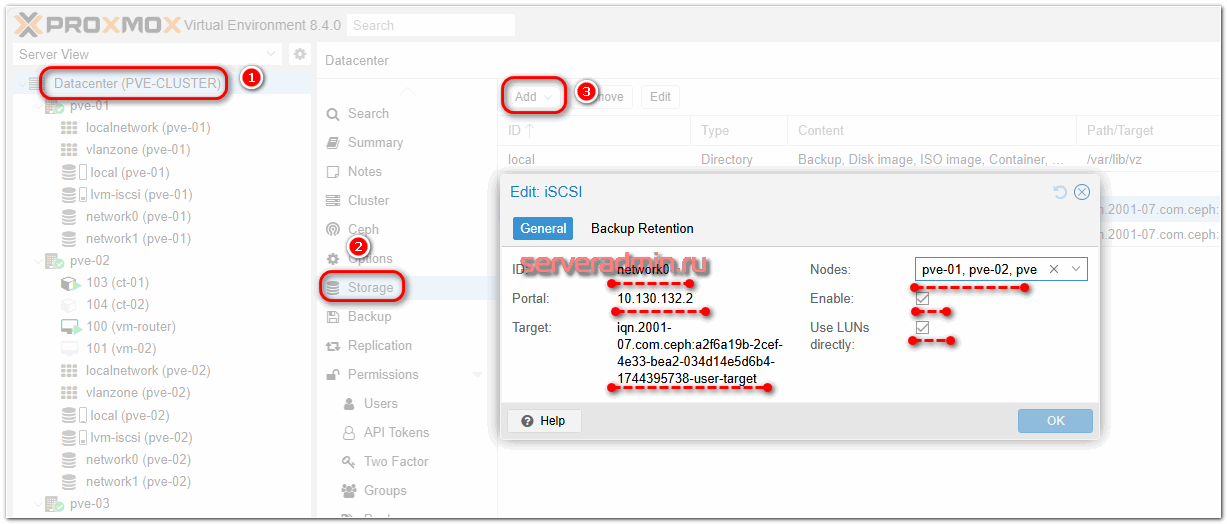
То же самое делаем для второго iSCSI-таргета.
Далее нам нужно поверх iSCSI дисков пустить RAW LVM. Для этого здесь же добавляем ещё одно хранилище типа LVM. Указываем ему следующие параметры:
- ID – любое имя, я назвал lvm-iscsi.
- Base Storage – указываем iSCSi Storage
- Base volume – выбираем из списка volume, он должен быть один, размером как созданный сетевой диск в панели управления
- Volume group - указываете любой, я указал то же самое, что в ID.
- Content – указываете, что там будете размещать.
- Shared – помечаем, так как у нас как раз такой режим совместного доступа к LUN.
- Wipe Removed Volumes – удалять ли данные сразу после удаления LV. Реальное удаление данных, а не просто пометка об удалении, затратная операция по ресурсам, так что если вам не критично, не ставьте галку.
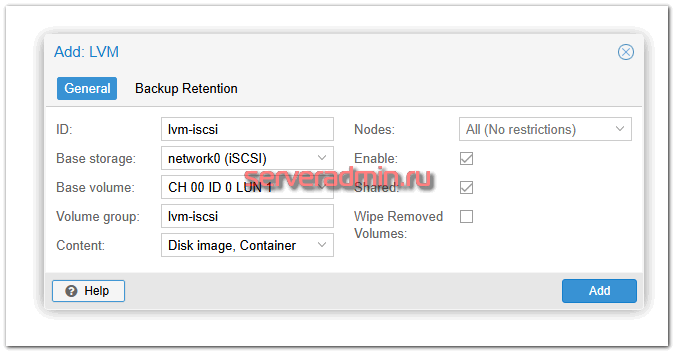
У меня получились вот такие итоговые настройки хранилищ в /etc/pve/storage.cfg
dir: local path /var/lib/vz content backup,rootdir,images,iso,snippets,vztmpl prune-backups keep-all=1 iscsi: network0 portal 10.130.132.2 target iqn.2001-07.com.ceph:a2f6a19b-2cef-4e33-bea2-034d14e5d6b4-1744395738-user-target content images nodes pve-03,pve-02,pve-01 iscsi: network1 portal 10.130.128.2 target iqn.2001-07.com.ceph:a2f6a19b-2cef-4e33-bea2-034d14e5d6b4-1744395738-user-target content images nodes pve-01,pve-02,pve-03 lvm: lvm-iscsi vgname lvm-iscsi base network0:0.0.1.scsi-3600140534e606011c8d4b8fa9da34c46 content rootdir,images nodes pve-03,pve-02,pve-01 saferemove 0 shared 1
Мы закончили подключение общего сетевого диска по протоколу iSCSI ко всем нодам кластера. Можно переходить к настройке HA (High Availability).
Настройка HA (High Availability)
Приступаем к настройке отказоустойчивого кластера на базе Proxmox VE с автоматическим запуском виртуальных машин на работающих нодах кластера в случае выхода из строя одной из них.
Настройка очень простая, если ранее сделаны все предварительные этапы. Вам необходимо выполнить следующие действия:
- Создать виртуальную машину с хранением дисков на общем сетевом хранилище, которое мы добавили ранее. Если у вас уже есть настроенные машины, то можно перенести их локальные диски на сетевые. И обязательно после этого нужно удалить локальный диск, если он остался в свойствах виртуальной машины в качестве отключенного устройства. Если этого не сделать, то VM не будет автоматически мигрировать со сбойной ноды.
- Зайти в раздел Datacenter ⇨ HA ⇨ Groups и добавить группу из нескольких нод кластера. Это актуально, если кластер большой, а вы хотите разбить кластер на несколько групп и привязать виртуальные машины к этим группам, чтобы они переезжали только в пределах своей группы. Для нашего случая кластера из трёх нод это не очень актуально. Для примера сделал одну группу из всех трёх нод.
- В раздел Datacenter ⇨ HA ⇨ Resources добавить виртуальную машину, указать, сколько рестартов и переездов можно сделать, к какой группе она должна быть привязана и в какое состояние её перевести после переезда.
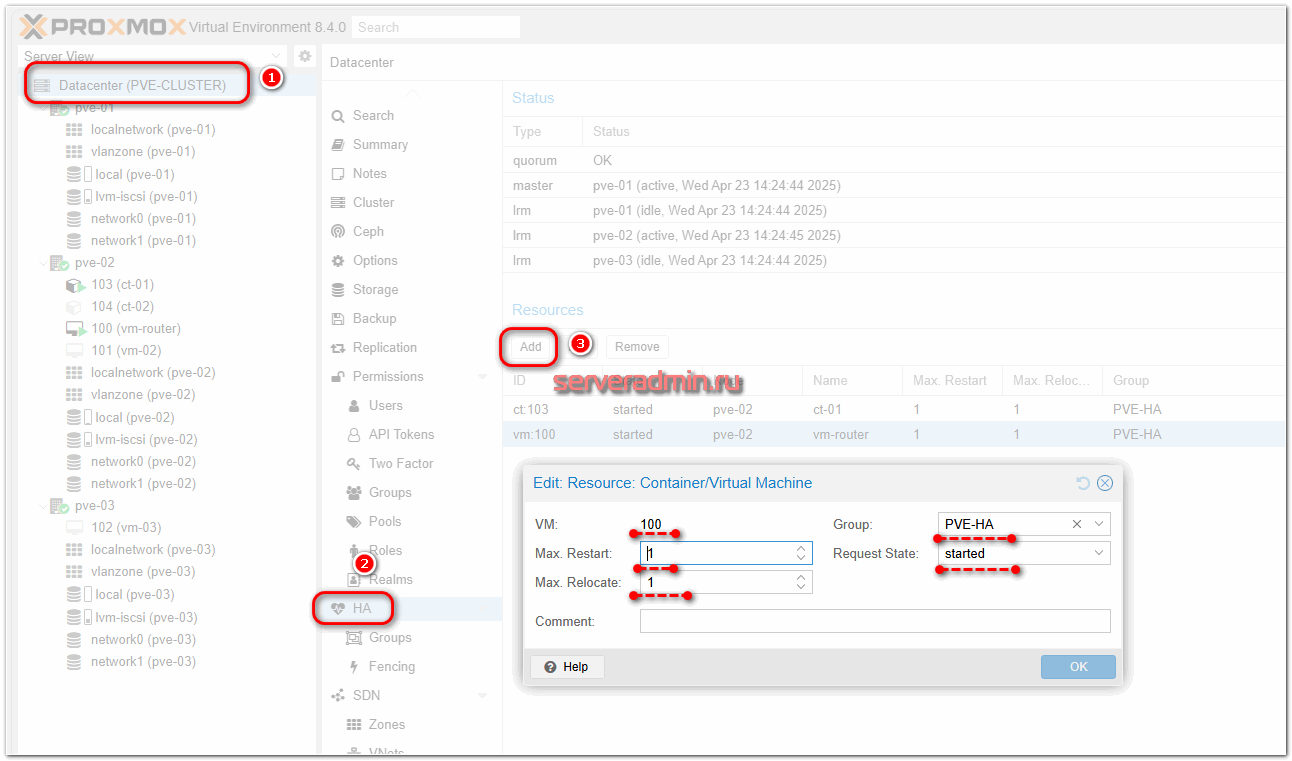
Немного поясню эти настройки. В случае падения одной ноды настроенные в режим HA виртуальные машины примерно через 2 минуты переезжают на работающую ноду. При этом они условно перезагружаются. Переехавшая виртуальная машина на новой ноде стартует заново, как-будто после аварийного завершения работы. Соответственно, вы можете настроить так, чтобы она автоматически не стартовала. Если она по какой-то причине не стартует, а причины могут быть разные – наличие локальных дисков на VM, которые остались на упавшей ноде, несовпадение по типам процессоров или другого железа и т.д., то параметр Max. Restart определяет, сколько будет попыток запуска. Я не особо понимаю, зачем тут могут пригодиться множественные попытки. Если машина не стартует, надо идти разбираться, что с ней не так.
После того, как настроили HA для виртуальных машин или контейнеров, можно посмотреть как отказоустойчивый кластер работает. Я просто взял и выключил через панель управления один из серверов, на котором были размещены одна виртуальная машина и один контейнер.
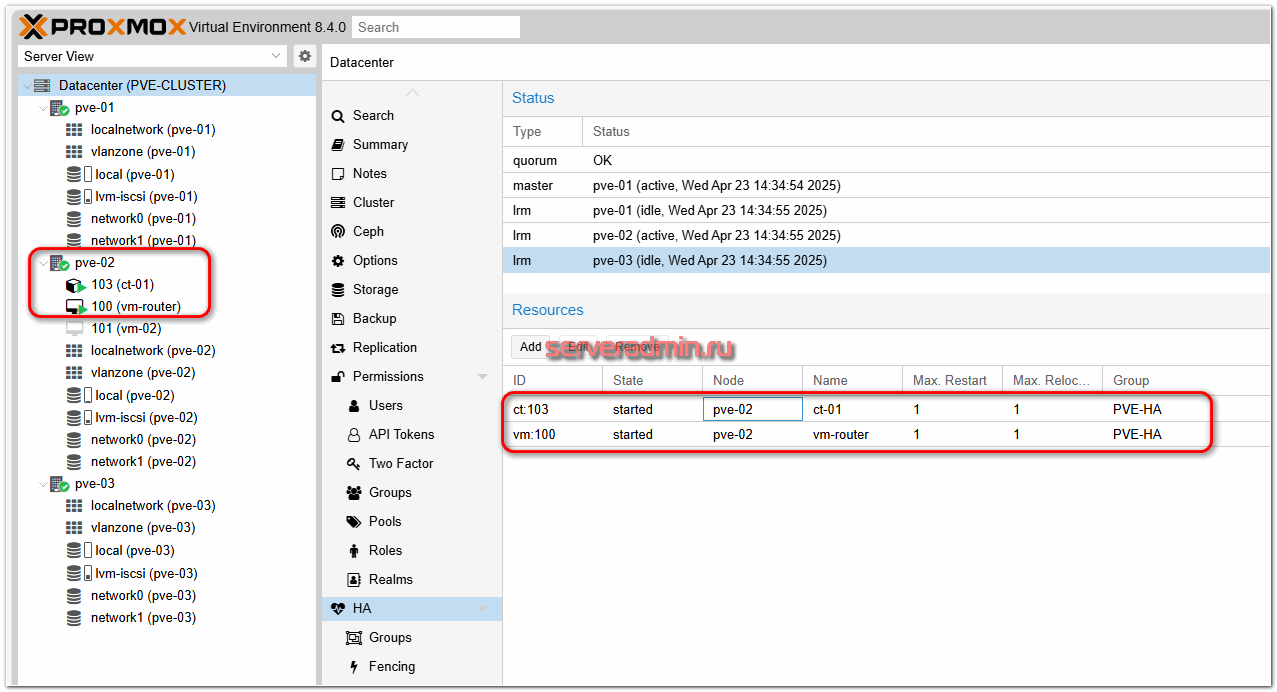
Выключаю сервер:
Секунд через 20 я вижу в панели управления кластером, что выключенный сервер недоступен:
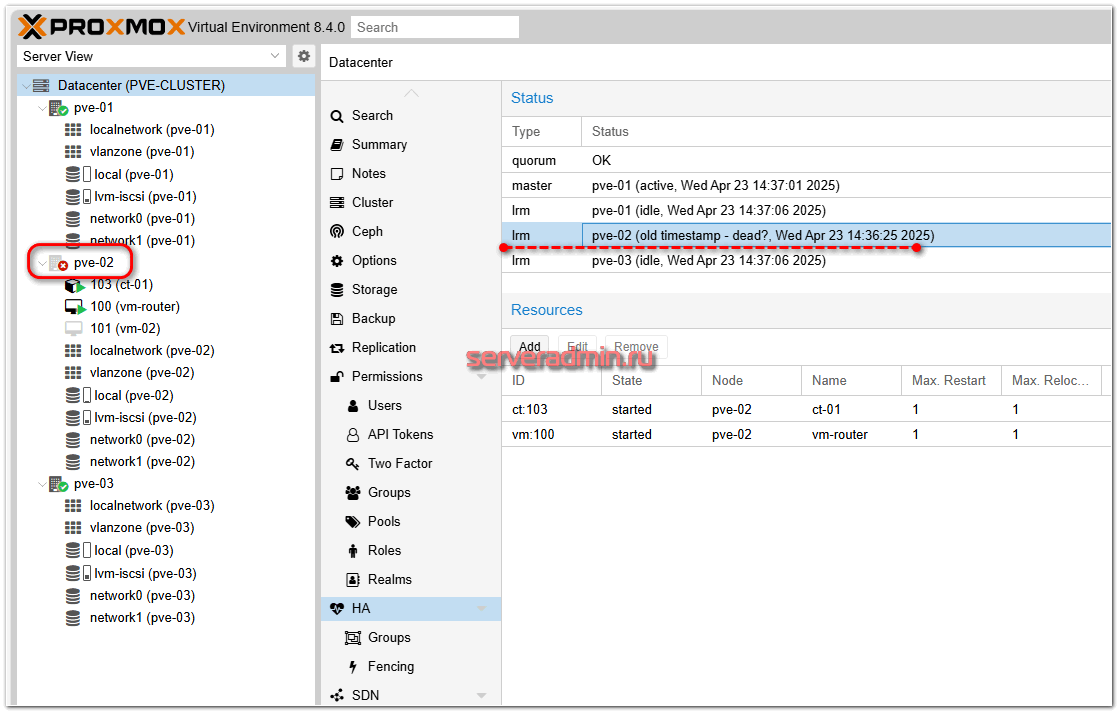
И примерно через 2,5 минуты упавшие виртуальные машины были запущены на двух других нодах кластера:
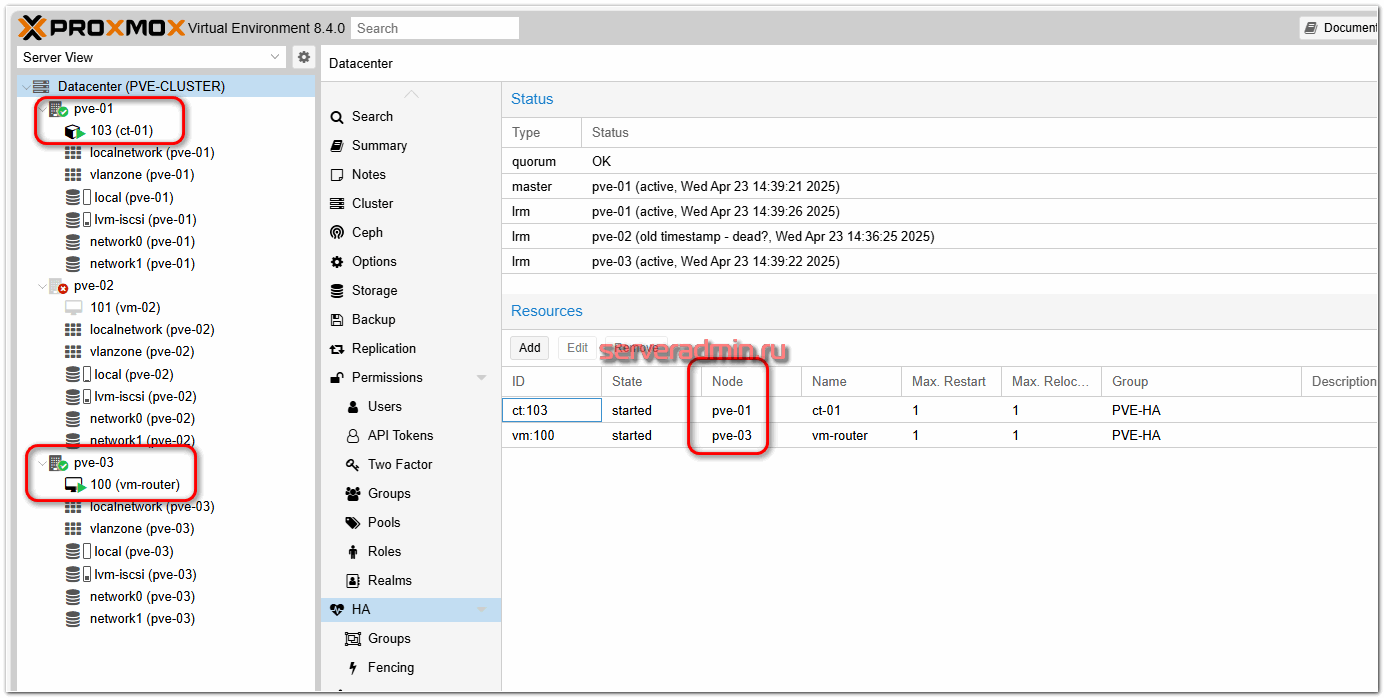
В моём случае ресурсы были автоматически распределены между общей группой серверов, которую я настроил ранее. Если хотите конкретизировать для каждого ресурса, куда он поедет, дробите кластер на более мелкие группы по 2 ноды и настраивайте для каждой VM или CT соответствующую группу.
В целом по работе кластера на базе Proxmox VE у меня всё. Я показал, как создать обычный кластер с ручной миграцией виртуальных машин и кластер с High Availability и автоматическим переносом виртуальных машин и контейнеров в случае падения ноды. Вы можете комбинировать эти два режима. Какие-то машины ставить в режим высокой доступности, а какие-то привязать к конкретной ноде с ручным переездом в случае необходимости.
В материале не хватает ещё одного раздела с созданием из этих же трёх нод локального кластера Ceph, но я вынесу это в отдельный материал, так как тут получился большой объём. Кластер с хранилищем это всё же немного другая тема, напрямую с кластером виртуальных машин не связанная.
Заключение
Подведём итог того, что мы сделали:
- Взяли в аренду 3 выделенных сервера с 2-мя локальными дисками, чтобы создать софтовый рейд массив для защиты от физического отказа одного из дисков. В качестве софтового рейда выбрали mdadm, так как в рамках моего примера он наиболее актуален за счёт простоты настройки и скорости работы. Если у вас не подразумевается использование общих сетевых дисков, то вы можете взять файловую систему zfs, разместить виртуальные машины на ней и настроить межнодовую репликацию. Это отдельный режим работы кластера, без HA.
- Настроили простой кластер на базе Proxmox с размещением виртуальных машин на локальных дисках. Машины в ручном режиме могут перемещаться без остановки с ноды на ноду. Это актуально, когда все ноды работают. Если выйдет из строя нода с локальными дисками, виртуальные машины уже никуда не переедут в силу того, что их диски будут недоступны.
- Добавили общие сетевые диски на базе протокола iSCSI ко всем серверам кластера. Разместили виртуальные машины на них.
- Настроили кластер высокой доступности High Availability на базе трёх нод Proxmox. Выбранные виртуальные машины и контейнеры будут автоматически запускаться на работающих нодах кластера, если их родная нода будет недоступна.
Мы получили универсальное и относительно бюджетное (в сравнении с другими кластерами) решение для размещения виртуальных машин и LXC контейнеров. Оно закрывает задачи размещения нагрузки на локальных дисках для максимальной производительности и отказоустойчивой нагрузки высокой доступности на базе сетевых дисков с общим доступом.
Отдельно отмечу, что описанные сетевые диски могут использоваться в рамках разных задач. Например, вы можете арендовать недорогой одиночный сервер и подключить к нему бюджетный сетевой HDD диск большого объёма для хранения холодных бэкапов. Другой вариант для бэкапов – поднять на одной из нод PBS (Proxmox Backup Server) в виртуальной машине, подключить сетевой диск для хранения на нём бэкапов виртуальных машин.
Как вы могли убедиться на основе представленного материала, настройка кластера высокой доступности на базе Proxmox VE представляет из себя относительно простую, рядовую задачу. При этом выполнить её можно на любом железе, от самого бюджетного десктопного оборудования до серверных платформ. Сочетание софтовых решений по отказоустойчивости дисков на базе mdadm или zfs вкупе с функциональностью HA кластера Proxmox позволяют реализовать относительно (!) высокую доступность на любом поддерживаемом этой системой оборудовании. А так как сама система на базе ОС Debian и ядра Linux, поддерживает она практически любое более-менее современное железо.
Реклама, АО «Селектел» ИНН 7810962785, erid: 2SDnje2mxrZ

Добрый день, спасибо за статью. А что делаете с доступом к сервисам в вашем кейсе, у каждой ВМ свой адрес выхода в интернет, условно 1.1.1.1, 2.2.2.2, 3.3.3.3. Что происходит когда хост 2.2.2.2 отключился и ВМ переехала на 3.3.3.3? Или необходимо перенести ВМ с одного хоста на другой?
В таком виде эту схему использовать не получится. Если вам нужен прямой доступ к сервисам через внешние IP серверов, то нужно где-то во вне ставить обратный прокси и на нём управлять соединениями. Если какой-то сервер становится недоступен, то меняем IP адрес апстрима на работающий. Проще всего для этого арендовать где-то в облаке небольшую виртуалку и поставить какой-то прокси сервер на базе Nginx, Angie, Traefik или чего-то подобного.
А если говорить про самый простой и бесплатный способ - то просто менять IP адрес в DNS записи, выставив TTL в 5 минут. Если такой простой допустим, то можно этим и ограничиться. Можно найти бесплатный DNS хостинг с доступом к API и делать это автоматически в случае падения и переезда виртуалки.
Pve как и любую ОС можно устанавливать, загрузившись в rescue с помощью qemu.
https://gist.github.com/gushmazuko/9208438b7be6ac4e6476529385047bbb
https://gist.github.com/WayneWayner/c478019ba934ed8e163b5a55d46d5ffd
Лично на селектеле проверял - работает.
Да, у Selectel удобно сделан rescue режим. Загружаешься и через внешний IP напрямую попадаешь на сервер. Можно что угодно там разворачивать и настраивать.
Спасибо.
1.Почему не zfs, к-ая умеет сжатие, дедуп и проверку данных на лету?
2. Если делаем post-up iptables , то надо и post-down iptables с удалением правила nat.
3. Для ceph в проде минимум 5 нод, а не 3. Три можно, но только на "потыкать".
В рамках данной тематики выбор файловой системы не принципиален. Можно выбирать любую. Я предпочитаю для сервера общего назначения mdadm. Да и у Selectel есть готовый шаблон с ним. Быстрее и проще развернуть.
Сам столкнулся с работой VLAN-ов (не понимал как настроить)
В конечном итоге подобрали вариант
vlan вешается на интерфейс, а уже потом на этот влан вешется bridge
iface enp1s0 inet manual
iface enp1s0.10 inet manual
iface enp1s0.50 inet manual
iface enp1s0.100 inet manual
auto vmbr10
iface vmbr10 inet static
address 10.200.10.100/24
bridge-ports enp1s0.10
bridge-stp off
bridge-fd 0
auto vmbr50
iface vmbr50 inet static
address 10.200.50.100/24
gateway 10.200.50.1
metric 10
bridge-ports enp1s0.50
bridge-stp off
bridge-fd 0
auto vmbr100
iface vmbr100 inet static
address 10.200.100.10/23
bridge-ports enp1s0.100
bridge-stp off
bridge-fd 0
Я так понимаю, это без использования встроенного SDN? Просто ручная настройка одинаковых бриджей и их использование на всех нодах?
Да, верно, в данном случае у меня кластер не используется, это одиночная нода