
На днях произошла проблема с одним из серверов в ЦОД, которая разрешилась без потерь и последствий. По горячим следам решил поделиться опытом и немного порассуждать на актуальную для многих тему. Она касается покупки или аренды дорогих брендовых серверов и сопутствующей с этим переплатой за бренд.
На углубленном курсе "Архитектура современных компьютерных сетей" вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Иногда заказчики просят меня подобрать, купить и настроить сервер для каких-то задач. В общем случае я всегда предлагаю брендовый (dell, ibm, hp, реже supermicro) сервер с двумя блоками питания и железным рейдом с горячей заменой дисков. Часто такое предложение встречает непонимание, так как есть много предложений недорогих серверов за цену в 2-3 раза меньше, чем предлагаю я. Банально накидав в прайс десктопные комплектующие, можно получить цену в 3 раза меньше за ту же производительность.
Сначала опишу ситуацию, которая приключилась со мной на днях, а потом продолжу свою мысль. У меня на обслуживании есть сервер dell, на котором настроен мониторинг по snmp с помощью zabbix. Под конец рабочего дня приходит как гром среди ясного неба оповещение системы мониторинга.
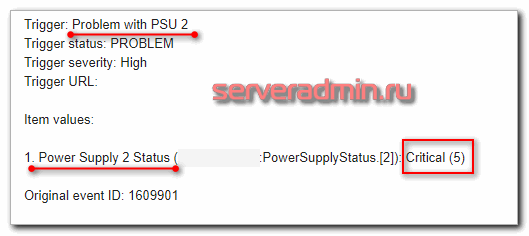
Пропало питание на одном из двух блоков питания. Если бы это был сервер с одним блоком питания, мне бы предстоял нескучный вечер, а может быть и ночь. На сервере работает гипервизор с кучей критичных виртуалок, без которых затруднится работа некоторого количества людей. Есть все бэкапы и даже подменный сервер, но в любом случае восстановление процесс хлопотный и не одномоментный.
Я оценил обстановку и решил отложить решение вопроса на утро следующего дня. Утром написал в тех. поддержку хостера:
Добрый день. На сервере 6808, который расположен в стойке 10/20 мониторинг показывает, что нет питания на одном из блоков питания. Прошу визуально посмотреть, включен ли силовой кабель в оба блока питания и есть ли на обоих линиях напряжение. Мне нужно понять, заказывать новый БП из-за того, что в сервере сломался, либо это проблема с линией. Только прошу посмотреть аккуратно, чтобы не выключить вторую оставшуюся линию. Сервер критически важен.
Через 10 минут получил ответ:
Добрый день.
Поправили кабель питания, видимо был воткнут не до конца при установке.
Сейчас индикация на 2-ом БП есть.
Если честно, я совсем не удивился, получив такой ответ. При монтаже сервера я присутствовал лично (всегда так делаю, если есть возможность, и вам советую) и уверен, что кабели были воткнуты нормально. Зная, как в цодах работает тех поддержка, я всегда в первую очередь грешу на рукожопство обслуживающего персонала. У меня есть статья с подборкой факапов тех. поддержки цодов, с которыми я сталкивался лично - как мне поменяли не тот диск. В этот раз наверняка рядом что-то монтировали и просто задели кабель. Силовые кабели обычно сидят плотно в гнездах и сами не вываливаются.
В итоге вздохнул с облегчением. Все нормализовалось.

Отделался легким испугом. А теперь представим, что было бы, если бы у меня был только один блок питания? Как минимум, все бы выключилось на некоторое время, пока я бы не заметил и не написал тикет в ТП. А так как это был вечер, не факт, что я следил бы за почтой и как-то отреагировал. В 20:30 каждый день я вообще отключаю мобильный телефон, так как начинаю укладывать детей и готовиться ко сну.
Еще не факт, что после включения внезапно обесточенного сервера с кучей виртуалок, все бы нормально стартовало. В общем, если у вас планируется к работе критический сервис, для которого простой более чем в 3-4 часа не допустим, то покупайте максимально надежное оборудование, удовлетворяющее ваши потребности по производительности.
Это не значит, что для дешевых серверов нет применения. На самом деле многие сервисы способны пережить гипотетическое отключение раз в несколько лет на 6-8 часов, которые нужны для заказа нового сервера, настройки его и восстановлению из бэкапа. Потери будут меньше, чем ежегодное дублирование мощностей или покупка более дорогого оборудования. Техническому специалисту важно просто и доступно объяснить заказчику, для чего покупается то или иное оборудование. Рассказать про риски и время восстановления в случае поломки. А дальше уже пусть заказчик сам решает, чем он готов рисковать и на что тратить деньги.
Лично у меня из-за выбора серверов никогда проблем не было. Я всегда доступно и понятно объяснял, какой сервер и за какие деньги лучше купить. И если были поломки, то они решались в штатном режиме с запланированным простоем, о котором заказчик был предупрежден. Главное всегда и с любым сервером надо помнить, что нужно делать бэкапы, регулярно их проверять и делать тестовые восстановления данных на другом железе.
К слову, блоки питания это то, что чаще всего выходит из строя, после дисков. Если есть возможность, всегда дублируйте БП. Еще я лично сталкивался с выходом из строя планок памяти. Если у вас нормальный брендовый сервер, то вы просто получите уведомление на почту о том, что один из модулей памяти не работает. Сервер при этом даже не зависнет, а продолжит работу без этого модуля. А дальше уже вам решать, останавливать сервер на замену или оставить все как есть.
В случае десктопного железа проблемы с памятью это бесконечный геморрой по выявлению этой проблемы, особенно на арендованном сервере, которому у вас нет физического доступа. Если у вас есть подозрение на проблемы с памятью, сразу переезжайте на другое железо. Это проще и быстрее. Пусть хостер сам разбирается со своим оборудованием.
На углубленном курсе "Архитектура современных компьютерных сетей" вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315

"В 20:30 каждый день я вообще отключаю мобильный телефон, так как начинаю укладывать детей и готовиться ко сну" - это просто супер.
К сожалению, как показывает практика, очень сложно донести необходимость приобретения более дорогого железа на фоне более дешёвого.
Жизнь заставит задуматься. Другое дело, если сисадмины прикрывают глючное железо своей спиной, тогда руководству нет смысла тратиться на что-то более надёжное.
Если не секрет, а по какой причине вы "недолюбливаете" supermicro? были какие то косяки с этим брендом в вашей практике?
С чего вы взяли, что недолюбливаю? Я достаточно часто его покупал и рекомендовал.
Ааа понял, просто в статье сказанно что реже, вот и сложилась неверное предположение.
Тут дело такое. Супермикро вроде и бренд известный, но все равно до большой тройки не дотягивает. Я часто беру б.у. сервера и там разница между условным supermicro и hp с dell будет очень маленькой и я предпочту dell. А вот если нужен 100% новый сервер, но условный hp слишком дорого, то я порекомендую supermicro. Так что все по обстоятельствам.
И еще.
Не забывайте, что в ЛЮБОЙ момент и Dell и HP и Supermicro могут уйти из РФ. И вы останитесь без какой либо поддержки с их стороны.
Переплатив 5-10 раз за оную ранее. Это крайне реально в нынешнем мире.Помните об этом.
Помните, что плохо не то, что человек (вы) смертен, а внезапно смертен (ц)
И вы в любой момент можете уйти не только из РФ, но и жизни, но и это ещё не точно, в смысле что это была хорошая новость.
Плохая - станете инвалидом. тогда вам меньше всего будет дела до того, ушли или пришли кто-то куда-то когда-то
У Вас в голове точно все по полочкам лежит? Причем тут смертность отдельно взятого человека и брендированные серверы? ) Я Вам так скажу, если админ завязал инфру чисто на себя, то и пароль с логином от кабинета вендора у него тоже завязаны на себя и тогда при его смерти вам от поддержки "великого" бренда придется очень с боем чего-то добиваться. Да и вообще, странно на вполне резонное замечание отвечать в духе "а так-то ты смертен" выглядит слегка как угроза )))
Ну вот и ушли) как в воду глядел.
Так других серверов всё равно нет. Вот и продолжают покупать их же.
>А кластер на чем? Proxmox? У него куча всяких затупов бывает. Это ненадежный кластер. Я бы в прод его не ставил. Видел много негативных отзывов.
Пруфы про затупы и ненадежность будут? Давайте по существу. Проблемы есть у всех. И многое зависит от персонала, к-ый настраивает ПО.
Тут давеча человек столкнулся с проблемой полного проброса сет. адаптера в ВМ с pfsense на Гипер-В. Так дошло до того, что прийдется ядро(!) пересобирать. На Proxmox VE это делается двумя строчками grub и 2-3 кликами мыши в GUI - forum.netgate.com/topic/150965/проброс-сетевой-карты-intel-i210-в-виртуальную-машину-dda/
Зы. Сохраните себе решение по ссылке. Уверен, что пригодится.
Зы2. Насчет брендового железа. Его удобно пользовать в крупных городах, когда имеется возможность БЫСТРО купить комплектующие к ним.
Для всех остальных - не рекомендую. Гораздо надежнее купить теже матплаты Asrock Rack со встроенным KVM и пользовать их. И не одну. Благо цена не так уж велика. Плюс пользовать софтовый рейд на гипере. Иначе проблема со сгоревшей брендовой матплатой и отсутствием таковой встает в ПОЛНЫЙ рост.
> когда имеется возможность БЫСТРО купить комплектующие к ним.
У-у-у, как всё запущенно...©
Щито блеад? Купить? Быстро?
Ясно-понятно, всё очень плохо, даже безнадёжно
А почему supermicro реже рекомендуете? Есть негативный опыт? Поделитесь пожалуйста.
> Под конец рабочего дня приходит как гром среди ясного неба
Почему как? Классика жанра: в питницу ночером...
> На сервере работает гипервизор с кучей критичных виртуалок, без которых затруднится работа некоторого количества людей.
Как уже написали: складывать все яйца в одну корзину (даже с дублированным чего-то там) - такое себе...
> Есть все бэкапы и даже подменный сервер, но в любом случае восстановление процесс хлопотный и не одномоментный.
В описанной вами задаче я бы предпочёл допилить автоматизацию DRP, путём максимально возможной виртуализацией. Дабы сервисы могли сами побежать на случай отказа ноды.
Мир нынче таков, что учитывать надо всё: от пожара и рейдерства до попадания сисадмина в реанимацию/морг, где нет возможности ручками удалённо погонять виртуалки. Не говоря уже о личном физическом посещении ЦОДа
Сисадмин, рассматривая объективно - такая же точка отказа, как и блок питания с рейд-массивом данных ))
Человека в любой момент может скрутить хотя бы аппендицит, в такое время больному туловищу меньше всего есть дела до чего-либо ещё, кроме заботы о собственной болезни. А у семейного человека есть ещё и домашние, которые могут обвариться-подавиться...
Не говоря уже о гибели, знамя локального DRP и павшего бойца должен мочь подхватить кто-то ещё.
вероятно втыкали тёплый кабель, в цод-е кабель замёрз и сошёл с ламелей разъёма БП)
А белый сервер или нет - это от требований задачи, бобла заказчика зависит. И там уж при желании можно обеспечить полный ЗИП рядом с сервером)
Мне чет не верится, что сам отошел. Я еще застал времена, когда почти у всех были свои серверные со шкафами. И одну такую серверную я обслуживал полностью сам. У меня ни разу кабель питания сам не отваливался за много лет, что я там проработал.
1) Касательно наличия двух БП на борту. Могу также посоветовать сразу же после приобретения такого сервера с двумя БП проверять настройку сервера на отказоустойчивость, вынимая поочередно каждый БП. Причем это нужно делать сразу после установки OS и не устанавливая каких-либо критичных приложений.
Ранее когда покупали серверы HP линейки DL, то по умолчанию в BIOS-е настроена всегда была опция Fault Tolerance (или как-то по другому называется, уже не помню). Т.е., два БП дублировали отказоустойчивость другу друга. Соот-но, при выходе одного БП аварийного выключения не было.
Но позже когда сразу купил очередную партию примерно 20 шт. HP DL 360 G6 или 7 (уже не помню), то поленился заглянуть в BIOS и начал устанавливать OS. А т.к. этот сервер должен быть в роли DC, то хорошо, что решил подстраховаться и проверить оба БП. При выдергивании первого БП сервер тут же вырубился. Заглянул в настройки BIOS и увидел, что стоит по умолчанию параметр типа Load balancing. Причем мне досталась такая вся партия серверов c такой настройкой по умолчанию.
2) Многие почему-то забывают покупать третий БП в качестве ЗИП-а, что также может сыграть злую штуку.
Да, все верно. Дельные замечания. Проверять надо всегда. Я иногда тоже забывал. Тестирую и БП, и обязательно рейд контроллеры. Это очень важно. Надо понимать, что делать в случае выхода из строя диска. Бывает, что ситуация будет разворачиваться не так, как ожидаешь (просто заменил диск и все в порядке).
Каким конкретным образом вы тестируете raid-контроллер? Выдергиваете на ходу винт и затем вместо него ставите новый из ЗИП-а и ждете окончания rebuild-а?
Или программно?
На ходу боюсь выдергивать работающий винт :) Останавливаю сервер, вынимаю винт, запускаю сервер. Убеждаюсь, что все работает. Опять останавливаю сервер, вставляю чистый диск, проверяю, что пошел ребилд и дожидаюсь его окончания. Попутно записываю, если есть какие-то нюасны в замене.
"На ходу боюсь выдергивать работающий винт :)" - а что мешает проверить работоспособность контроллера в максимально боевом режиме, если на ходу вытаскивать винт? Просто нужно тут действовать пр принципу как с БП - сразу же после установки ОС накатить пару гигов каких-нибудь неважных данных. Вытаскиваем винт и проверяем целостность рейда и данных.
В таком случае вы ничего не теряете, а только появляется бОльшее чувство уверенности, как себя поведет контроллер под нагрузкой.
Если на ходу вынимать работающий диск, он может сломаться. Мне диски жалко.
"Если на ходу вынимать работающий диск, он может сломаться. Мне диски жалко."
Это миф. Особенно на таких скоростных дисках. Головы в любом случае запаркуются тягой магнита и не важно читал он или писал. Поверьте многолетнему опыту сервисника.
На то это все и называется горячая замена, чтобы можно было работать с включенным питанием.
Уже все учтено, не услажняйте себе и так нелегкую работу такими замарочками.
Я условно выразился. У меня был опыт, когда я на горячую вытащил диск из сервера, который не поддерживал горячую замену. Умер raid контроллер, перестал видеть диски. Пришлось его менять. Я не знаю, что конкретно произошло, но наблюдал лично.
Владимир, на счёт двух БП вы все верно пишете. Но иметь кучу критических виртуалок на standalone сервере...сами понимаете думаю
Я же говорю, это вопрос обсуждаемый в каждом конкретном случае. Они критичны, но их простой не стоит постоянного дублирования мощностей. Несколько часов можно потратить на восстановление в случае чего. Конкретно в данном случае лежит на готове подменный сервер, в который по ночам заливаются бэкапы виртуалок. Это согласовано с руководством.
К тому же, нужно понимать, что полноценное резервирование это не просто x2 затрат, а гораздо больше. Тут и софт с лицензиями, и работа по обслуживанию, и железо.
Экономическую целесообразность подобных настроек утверждает не технический специалист, а руководство.
> Несколько часов можно потратить на восстановление в случае чего.
Как уже написал - надо исходить из максимально возможного худшего сценария )
Сисадмин в КПЗ/больнице/отпуске без связи, дублирующий сервер нуждается в мониторинге и диагностике
В общем, периодические/регулярные учения по планированию и отработке DRP. максимально возможно приближенные к боевым
> Экономическую целесообразность подобных настроек утверждает не технический специалист, а руководство.
Тут вопрос доверия и делегирования полномочий
Ещё бы руководство не было эффективным...Иначе часто оно не было руководством
Жадность/глупость, надежда на авось, самоуверенность, техническая некомпетентность...
И вот уже решения принимаются по другим критериям...
Но это уже совсем другая история, вечная борьба инженегров-технарей и управленцев-приказчиков
Когда в лучшем случае разумное ограничение стремления инженеров строить бункеры и потратить все бюджеты
В худшем - в счёте вместо железа, ПО и услуг пересчитывать на айфоны и иные связанные с деньгами блага
"К тому же, нужно понимать, что полноценное резервирование это не просто x2 затрат, а гораздо больше. Тут и софт с лицензиями, и работа по обслуживанию, и железо."
Вариант для небогатых - второй сервер в кластере, на котором хранятся реплики. В случае чего реплики становятся активными и всё, доп затрат не очень много., только сам гипервизор
А кластер на чем? Proxmox? У него куча всяких затупов бывает. Это ненадежный кластер. Я бы в прод его не ставил. Видел много негативных отзывов.
Есть же только 2 коммерческих платформы: Hyper-V, VmWare
Так автор выше написал, для небогатых. Это точно не про кластер на VmWare. У Hyper-V не знаю, что с ценами на кластерные лицензии.
Кластер на hyper-v отлично собирается из бесплатных версий (который урезанный hyper-v server).
Но тут нужно иметь ввиду что:
- нужна AD обязательно для работы кластера, причём КД хотя бы один должен находиться не в кластере, иначе нормально кластер не стартует. Это доп. ресурсы, лицензии итд.
- если в кластере крутятся windows-машины, то каждая вм должна быть пролицензирована на всех нодах кластера. Например, если в кластере 5 машин и две ноды, то надо 10 лицензий. Либо юзать datacenter, что уже не дёшево.
"Конкретно в данном случае лежит на готове подменный сервер, в который по ночам заливаются бэкапы виртуалок."
У вас на сайте случайно нет статьи, как реализовано автоматическое разворачивание боевых вирт. машин из бекапов?
Если я конечно правильно понял, что функционал именно таков.
Статьи нет, так как это очень сильно зависит от каждой конкретной ситуации. Какой гипервизор используется, и как бэкапится. Проще всего это через Veeam организовать.