
Во время работы с базой данных postgresql в 1С необходимо периодически выполнять задачи по бэкапу базы данных и ее восстановлению. Для увеличения производительности рекомендуется регулярно проводить очистку, анализ и переиндексацию базы 1С. Для автоматизации процессов по архивации и обслуживанию я написал небольшие скрипты с пояснениями. Ими и хочу поделиться с вами.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном онлайн-курcе по администрированию MikroTik. Автор курcа – сертифицированный тренер MikroTik Дмитрий Скоромнов. Более 40 лабораторных работ по которым дается обратная связь. В три раза больше информации, чем в MTCNA.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Содержание:
Данная статья является частью единого цикла статьей про сервер Debian.
Введение
Ранее я рассказывал о том, как установить и настроить postgresql для работы с 1С, а затем как провести анализ производительности базы 1С и по возможности увеличить быстродействие. После успешного выполнения первых двух задач, мы можем приступать к эксплуатации системы. Когда рабочая база 1С уже на сервере, обязательно нужно настроить ее регулярный бэкап. Желательно так же периодически проводить очистку и переиндексацию sql базы. Это увеличит ее быстродействие. Выполнять эти операции лучше всего автоматически, в нерабочее время. Именно этим мы и займемся в этой статье.
Бэкап и восстановление базы 1C в бд postgresql
Способов бэкапа базы данных postgresql много. Я буду использовать самый простой - выгрузка базы данных в обычный текстовый sql скрипт с помощью pg_dump. Подробно о работе этой утилиты и ее настройках можно прочитать вот тут - https://postgrespro.ru/docs/postgrespro/9.6/app-pgdump. В сети много примеров и готовых скриптов для решения вопроса архивации баз postgresql. Например, есть вот такой скрипт. Когда я его увидел, мне просто стало лень с ним разбираться. Написать простенький свой мне гораздо проще.
Прежде чем делать непосредственно архив 1С базы, нам нужно разрешить подключаться локально к серверу бд без авторизации. Я единственный пользователь сервера, доступа к нему никто больше не имеет, в интернет он не опубликован, поэтому я сознательно иду на этот шаг, чтобы упростить себе работу. Если для вас этот вариант не подходит, то все дальнейшие скрипты вам нужно будет самим изменить, добавив в них авторизацию. Это не сложно, в описании команд все есть. Я буду все команды выполнять локально от пользователя root.
Редактируем в файле /etc/postgresql/9.6/main/pg_hba.conf строку, приведя ее к такому виду:
local all all trust
После этого надо перезапустить постгрес, чтобы изменения вступили в силу.
# systemctl restart postgresql
Бэкап базы данных выполняется простой командой:
# pg_dump -U postgres base1c | pigz > /backup/base1c.sql.gz
| postgres | имя пользователя базы данных |
| base1c | название бд с 1С |
| pigz | архиватор |
| base1c.sql.gz | файл, куда будет сохранена резервная копия |
Обращаю внимание на архиватор pigz. Я его использую, потому что он умеет жать данные, нагружая все ядра процессора, в отличие от gzip. Прирост производительности 2-3 раза. Рекомендую. На debian он ставится из стандартного репозитория:
# apt-get -y install pigz
В centos из epel:
# yum -y install epel-release # yum -y install pigz
Попробуйте вручную в консоли выполнить команду и посмотреть на результат. Вы должны получить заархивированный файл с текстовыми sql командами в открытом виде. Теперь попробуем восстановить базу данных 1С из архива. Тут будут нюансы. Первым делом разархивируем файл:
# unpigz /backup/base1c.sql.gz
Файл будет распакован, а архив удален. Чтобы сохранить архив, можно использовать такую команду:
# unpigz -c /backup/base1c.sql.gz > base1c.sql
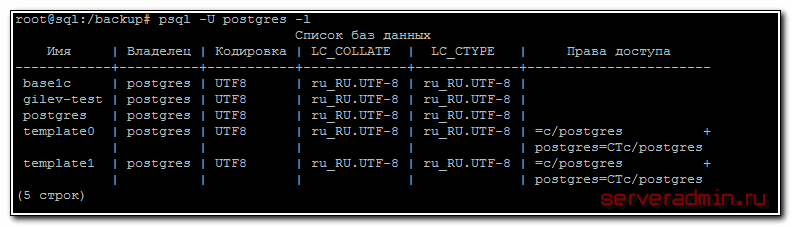
Создадим на сервере новую базу данных, в которую будем восстанавливать резервную копию. Перед этим посмотрим список баз данных на сервере:
# psql -U postgres -l
Создаем новую базу данных:
# createdb --username postgres -T template0 base1c-restored
Смотрим, что получилось:
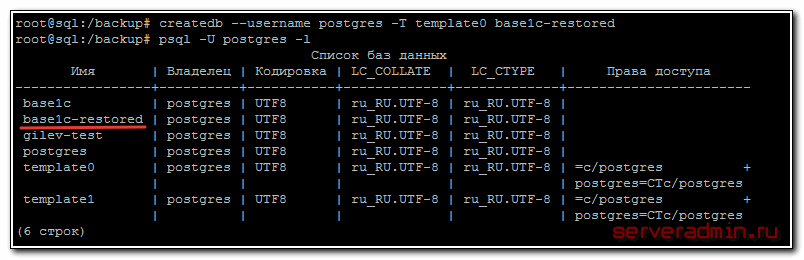
Базу данных создали. Теперь загружаем в нее наш бэкап 1с:
# psql -U postgres base1c-restored < /backup/base1c.sql
Ждем приличное время. Оно будет зависеть от размера базы. После того, как восстановление завершено, можно идти в консоль кластера 1С и добавлять новую базу, указывая в качестве базы postgresql только что созданную базу с загруженным архивом.
Я сначала пошел по другому пути. Создал в консоли пустую базу, загрузил в нее бэкап через консоль postgresql. Архив вроде бы загрузился, но в базу я не мог войти, не проходила авторизация. То есть возникли какие-то проблемы. Когда сделал, как описал выше, без проблем все заработало сразу. Проверил базу, все было в порядке.
После того, как вы убедитесь, что все в порядке, можно написать небольшой скрипт, который мы добавим в cron для регулярного бэкапа нашей базы 1С. Я его сделал совсем простым, ничего лишнего, только 1 база. Я считаю, что если баз не много и вручную не представляет труда написать несколько строчек скрипта, то лучше все сделать без циклов и лишних переменных. Если у вас больше одной базы, то просто скопируйте строки и замените названия баз. Вот сам скрипт:
# cat /root/bin/backup-sql.sh
#!/bin/sh
# Устанавливаем дату
DATA=`date +"%Y-%m-%d_%H-%M"`
# Записываем информацию в лог с секундами
echo "`date +"%Y-%m-%d_%H-%M-%S"` Start backup base1c" >> /var/log/postgresql/service.log
# Бэкапим базу данных base1c и сразу сжимаем
/usr/bin/pg_dump -U postgres base1c | pigz > /backup/$DATA-base1c.sql.gz
echo "`date +"%Y-%m-%d_%H-%M-%S"` End backup base1c" >> /var/log/postgresql/service.log
# Удаляем в папке с бэкапами архивы старше 3-х дней
/usr/bin/find /backup -type f -mtime +3 -exec rm -rf {} \;
Я указал в названии файла с бэкапом 1с базы использовать текущую дату с точностью до минуты. В лог я пишу информацию с точностью до секунды, чтобы было точно видно, сколько длился бэкап. Просто для справки информация, можно обойтись и без лога совсем. В конце удаляю из папки все архивы старше 3-х дней. Я обычно сервером с бэкапами забираю информацию с целевых хостов. То есть я буду подключаться к sql серверу и забирать с него архивы и уже на сервере бэкапов буду их хранить и ротировать в зависимости от желаемой глубины архива. А здесь я удаляю почти сразу архивы, не храню их, чтобы не занимать место. Если вы будете хранить их долгосрочно на этом же сервере, то просто измените цифру 3 на нужное вам число дней, за которые вы хотите иметь архивную копию своей базы 1С.
Использование программы PostgreSQL Backup

Для бэкапа базы данных постгрес есть удобная и бесплатная для двух баз программа под windows - PostgreSQL Backup. Я ее установил, проверил, сделал бэкап, потом восстановил из бэкапа. Все отлично работает. Из полезных функций:
- встроенный планировщик
- автоматическое сжатие бэкапа
- отправка оповещений на email
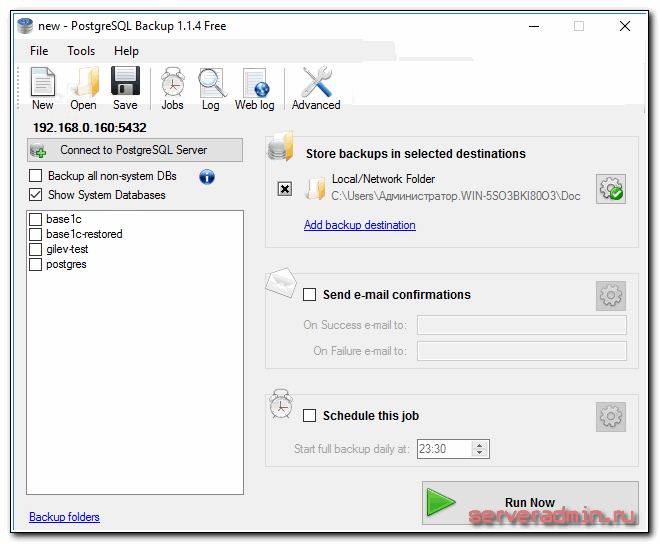
Программа, простая, понятная и приятная на вид. Попробуйте, возможно вам будет достаточно такого варианта. К сожалению, она не умеет восстанавливать из бэкапа. Для этого архив придется перенести на сервер, распаковать и загрузить в базу через консоль, как я показывал выше.
Обновление статистики и реиндексация в postgresql
С бэкапами разобрались, теперь настроим регламентные операции на уровне субд, чтобы поддерживать быстродействие базы данных. Тут особых комментариев не будет, в интернете очень много информации на тему регламентных заданий для баз 1С. Я просто приведу пример того, как это выглядит в postgresql.
Выполняем очистку и анализ базы данных 1С:
# vacuumdb --full --analyze --username postgres --dbname base1c
Реиндексация таблиц базы данных:
# reindexdb --username postgres --dbname base1c
Завернем все это в скрипт с логированием времени выполнения команд:
# cat /root/bin/service-sql.sh
#!/bin/sh # Записываем информацию в лог echo "`date +"%Y-%m-%d_%H-%M-%S"` Start vacuum base1c" >> /var/log/postgresql/service.log # Выполняем очистку и анализ базы данных /usr/bin/vacuumdb --full --analyze --username postgres --dbname base1c echo "`date +"%Y-%m-%d_%H-%M-%S"` End vacuum base1c" >> /var/log/postgresql/service.log sleep 2 echo "`date +"%Y-%m-%d_%H-%M-%S"` Start reindex base1c" >> /var/log/postgresql/service.log # Переиндексирвоать базу /usr/bin/reindexdb --username postgres --dbname base1c echo "`date +"%Y-%m-%d_%H-%M-%S"` End reindex base1c" >> /var/log/postgresql/service.log
Сохраняем скрипт и добавляем в планировщик. Хотя я для удобства сделал еще один скрипт, который объединяет бэкап и обслуживание и уже его добавил в cron:
# cat all-sql.sh
#!/bin/sh /root/bin/backup-sql.sh sleep 2 /root/bin/service-sql.sh
Добавялем в /etc/crontab:
# Бэкап и обслуживание БД 1 3 * * * root /root/bin/all-sql.sh
Проверяем лог файл и наличие бэкапа. Не забывайте делать проверочное регулярное восстановление бд из архива.
Описанные выше операции очистки и переиндексации можно делать в ручном режиме в программе под windows - pgAdmin. Рекомендую ее установить на всякий случай. Достаточно удобно и быстро можно посмотреть информацию или выполнить какие-то операции с базой данных посгрес.
Заключение
Вот и все, что я хотел рассказать по поводу бэкапа и обслуживания баз postgresql в связке с 1С. Если у кого есть еще полезная информация, прошу поделиться в комментариях. Возможно с бэкапом есть какие-то нюансы, особенно на больших базах. Но мне негде тестировать, больших рабочих баз более 10 гб у меня нет под рукой, а с теми что были, все отлично работает.
Напоминаю, что данная статья является частью единого цикла статьей про сервер Debian.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном онлайн-курcе по администрированию MikroTik. Автор курcа – сертифицированный тренер MikroTik Дмитрий Скоромнов. Более 40 лабораторных работ по которым дается обратная связь. В три раза больше информации, чем в MTCNA.
Реклама ИП Скоромнов Д.А. ИНН 331403723315

Вот эта часть скрипта:
# Удаляем в папке с бэкапами архивы старше 3-х дней
/usr/bin/find /backup -type f -mtime +3 -exec rm -rf {} \;
у меня почему-то не отрабатывает. Старые бэкапы не удаляются.
postgres 14
при создании дампа указанным способом, и дальнейшем его восстановлении
/opt/pgpro/1c-14/bin/psql -U postgres BASE < Backup.sql летят ошибки psql: ошибка: неверная команда \
Лучшие использовать не текстовый дамп, а бинарный, и восстанавливать через pg_restore
create backup
pg_dump -h localhost -p 5432 -U postgres -F c -b -v -f
"/usr/local/backup/10.70.0.61.backup" old_db
-F c is custom format (compressed, and able to do in parallel with -j N) -b is including blobs, -v is verbose, -f is the backup file name.
restore from backup
pg_restore -h localhost -p 5432 -U postgres -d old_db -v
"/usr/local/backup/10.70.0.61.backup"
important to set -h localhost - option
Сравнение лучше или хуже тут неуместно. Это разные инструменты и они оба имеют право на жизнь. У каждого есть как плюсы, так и минусы.
При создании базы через rac:
./rac infobase create --create-database --name=mcfo --dbms=PostgreSQL --db-server=db-server --db-name=mcfo --db-user=mcfo --db-pwd="password" --cluster="ed39808b-bef7-4ea3-b1d3-9091039104a5" --locale="ru_RU.UTF8"
Error of administration operation
Invalid or missing connection parameters required for Infobase creation
Incorrect localization name 'ru_RU.UTF8'
При создании через оснастку с клиента:
---------------------------
Внимание!
---------------------------
Ошибка создания информационной базы:
Ошибка операции администрирования
Ошибка при выполнении операции с информационной базой
У пользователя недостаточно прав на исполнение операции над базой данных.
---------------------------
ОК
---------------------------
При этом из оснастки база, создается
postgres=> \l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+----------+----------+-------------+-------------+-----------------------
mcfo_vgo | mcfo | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 |
mcfo_vgo2 | mcfo | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 |
postgres | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =Tc/postgres +
| | | | | postgres=CTc/postgres+
| | | | | mcfo=c/postgres
template0 | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | ru_RU.UTF-8 | ru_RU.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
(5 rows)
postgres=> \du+
List of roles
Role name | Attributes | Member of | Description
-----------+------------------------------------------------------------+-----------+----------------
mcfo | Create DB | {} |
postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {} |
postgres=>
Может есть у кого дамп пустой 1Сной базы, поделитесь плз.
Разобрался, как минимум для создания БД нужны SU права..
Здравствуйте.
Столкнулся с ошибкой
"19.05.2022 13:43:03 [Error] Failed to backup "zup3" database with "Full" backup type: C:\Program Files (x86)\SQLBackupAndFTP\DBMS\PostgreSql\pg_dump.exe process has finished with "-1073741515" code. The error message: ""."
при попытке бэкапа SQLBackupAndFTP.
Возможно это связано с тем, что журналы pg_wal на сервере у меня через символьную ссылку перенаправлены на другой жесткий диск, смонтированный в /mnt. Но ничего вразумительного по указанной ошибке найти не смог.
Подскажите.
Есть дамп выгруженный командой
pg_dumpall -U postgres /file.sql
В этой базе несколько информационных баз 1с
Как то можно восстановить данные из него для 1с баз ?
Забыл указать на ИТС указано
Следует обратить внимание, что утилиты pg_dump и pg_dumpall создают логическую копию, которая не содержит информации для дальнейшего воспроизведения журнала транзакций и потому не подходит для решения задачи восстановления Point-in-Time.
Это очевидно из самой сути подобных дампов - конкретная копия базы на момент создания дампа. Журнал транзакций не сохраняется.
Только если вручную разбить этот дамп на базы. Мне так приходилось иногда делать. Использовал утилиту sed.
в итоге пришел к варианту с использованием pg_basebackup
pg_dump может выгрузить одну базу из кластера, т.е. обратно ее можно загрузить, если все остальные сущности (необходимые для работы базы) будут в наличии
на вновь развернутом сервере, при восстановлении сыпет страшными ошибками
pg_basebackup "предназначена для создания базовых копий работающего кластера", т.е. создает бинарную копию каталога БД
т.е. делаем полный архив для последующего восстановление на свежем сервере, путем копирования и восстановления каталога main (конечно с остановкой постгреса)
по объему у меня вышло:
dump - 1,8 Gb
pg_basebackup - 2,5 Gb
вот список команд:
# т.к. архивирую с реплики, то ставалю ее на паузу
psql -Upostgres -c "SELECT pg_wal_replay_pause();"
#создание бинарного архива
pg_basebackup -U postgres -D - -Ft -z -Xf | pigz -c > /mnt/arh/base1c/1cbase_"$(date +\%d-\%m-\%y)".gz
#распаковка
unpigz < /mnt/arh/base1c/1cbase_07-02-22.gz | tar -zxC /mnt/121hdd/arh/base1c/pg_main/
периодически освежаем на архивном сервере распакованый main
потом кода понадобилась архивная база
запускаем виртуалку с постгресом
останавливаем на ней постгрес
очищаем директорию main
копируем распакованный архив
запускаем постгрес
#переводим реплику в мастер
sudo -u postgres /usr/lib/postgresql/11/bin/pg_ctl promote -D /var/lib/postgresql/11/main/
смотрим чтобы файл primary_conninfo.conf превратился в primary_conninfo.done
Топ статья. давно искал софт для автоматического бекапа postgresql
Устарела уже. Пора обновлять. Давно писал ее.
Ждем
Добрый день, а не подскажите, какие изменения для новой версии будут? У меня к примеру 12 версия.
Может есть опыт на pg probackup ?
Новую статью не писали?
Новое ничего не писал. А обычные дампы работают в любой версии. Я 1C на 13-й так же бэкаплю через дампы, никаких проблем.
А не пробовали использовать pg_probackup ?
Спасибо вам за сайт, очень много полезной информации.
Не пробовал ничего другого. Всё руки не доходят. По факту мне достаточно простого дампа. Я его потом автоматом разворачиваю на другой сервак и делаю выгрузку из базы в dt файл, чтобы проверить валидность. Всё это автоматически. Уже написан черновик статьи по этой теме, но всё не хватает времени доделать.
решил поставить 1с на постгрес (версия 11.10-2.1C)
спасибо большое за Ваши статьи, очень помогают
столкнулся с задачей архивации, у меня будет одна база и надо делать один архив b чем проще - тем лучше, 1с-ники сказали что база будет 50 ГБ
пустая база - 1,2 ГБ, Вашим скриптом ужимается до 771 МБ, архивируется около 1 мин, это более чем в 2 раза быстрее чем другими архиваторами
но столкнулся с проблемой, при архивации выдает ошибку, нагуглил что надо увеличить параметры
max_standby_archive_delay
max_standby_streaming_delay
надо выставить в них время побольше, но это тоже не дело, потому как 50 ГБ будет архивироваться час
нагуглил, что перед архивацией надо ставить на паузу WAL, а после его восстанавливать
архивирую конечно с реплики, так что она потом догоняется
ну и немного логов добавил, куда ж без них
в общем в качестве простого варианта архива получилась такая вот строка в кроне:
0 1 * * * log="/mnt//arh/base1c/1carh.log"; echo $(date) >> $log && psql -Upostgres >> $log 2>&1 -c "SELECT pg_wal_replay_pause();" && pg_dump -U postgres 1cbase | pigz -c >> $log 2>&1 > /mnt/arh/base1c/1cbase"$(date +\%d-\%m-\%y)".sql.gz && echo $(date) >> $log && psql -Upostgres >> $log 2>&1 -c "SELECT pg_wal_replay_resume();"
Спасибо за информацию. Для бэкапов postgresql есть много готового софта - wal-g, pgbackrest_auto и т.д. Лучше подобрать какой-то готовый софт. Это будет надежнее.
надо будет почитать, по первому взгляду там все круто
в 1С архивы, в большинстве случаев, нужны для 1С-ников, а им нужен просто файл, желательно с датой в названии и простой механизм развертывания, чтоб хватало их мозговых ресурсов для понимания схемы развертывания без привлечения админа
А разве одинесники смогут зайти в консоль postresql сервера и залить архив из дампа? Мне кажется, для них это слишком сложно. Они обычно из dt что-то могут загрузить. Иногда через консоль mssql. Но консоль линукса это оверскилл для них.
не согласен, я одинэсник успешно использую советы из статьи за которую большое спасибо! пароль админа к постгри скл раздобыл из скриптов в общей папке 😈🤩😁
Такая настройка бекапа подходит только для админа локалхоста.
В продакшене надо использовать basebackup раз в сутки + выгрузку и архивирование логов, т.е модель непрерывной архивации.
Настраивается ненамного сложнее, но позволяет восстановить базу на любой момент времени, а не на дату последнего бекапа.
Это не вопрос локалхост или не локалхост. Это зависит от требований, предъявляемым к бэкапам в конкретном случае. Непрерывная архивация нужна не везде и не всем.
Я смутно представляю среду, где пропажа данных из 1С за день не приведет к проблемам в сторону админа.
Где это не так, то там скорее всего такая связка и не нужна.
Да почти весь малый и средний бизнес, не затрагивающий напрямую финансы и массовое обслуживание людей. Где бы я не работал, нигде не требовался непрерывный бэкап 1с. Задачи такой не ставили. И сейчас не стоит, хотя базы 1с на поддержке есть. Та же бухгалтерия или зуп восстанавливаются и по бумажкам в самом крайнем случае. 1 день пропажи трагедией не станет.
Привет . Почитал тему и очень грамотно а так же просто все.
Здравствуйте, Вы встречались с проблемой когда служба постгреса не стартует после сбоя по питанию? Как быть в таких случаях?
это всё хорошо только на одном и том же серваке, перенести такой дамп не получилось, ругается на отсутствие "отношений"
пробовал пилить дамп на структуру, foreign keys и данные, потом загружать в порядке 1,3,2 - не получилось
https://www.sinyawskiy.ru/relation_not_exist.html
Другой сервер только физически другой или версии софта тоже разные? Это принципиальный момент. Я восстанавливал всегда на те же самые версии. Правда и "железо" было то же. Я вместе с дампом БД всегда делал и бэкап виртуалки, где она работала.
рад, что ответили
если собрать новый сервер с теми же версиями софта, то поднять такой бэкап в чистый постгрес у меня не получилось
у вас такой "перенос" работает? или вы создавали новую базу в 1С потом туда разворачивали дамп?
мне пришлось переносить средствами 1С (через dt), но если бы данные померли - даже не знаю
в общем, буду теперь разбираться и эксперементировать
Не проверял такой перенос. Я всегда бэкаплю и виртуалки как раз, чтобы не было таких сюрпризов.
Исключать такой случай не стоит.
Согласен, это нужно обязательно проверить. Сейчас у меня нет на поддержки таких систем, поэтому тема неактуальна. Если буду еще настраивать, обязательно проверю. Я всегда проверяю восстановление из резервных копий.
PS рестор на тот же сервер работает, да
например, если надо сделать копию базы там же
Acrinis - делаю всегда полную копию сервера и клиент докупает диск для копии . Linux копия стартует на любом железе!)) главное что б HDD был ровно такого же размера для восстановления копии ( желательно купить их 2ва сразу и одной фирмы) это спасает Вас . Быстрее конечно восстановится но Ваш труд меньше оценится.
Таки я был не совсем прав. Проблемы возникают если делать бэкап в кастомном формате (зачем он нужен?) pg_dump -Fc
Обычный вариант, который Вы используете - вполне переносится.
Отличная статья. Добавлю: если Postgresql установлен на Linux машине то и pg_dump тоже используйте Linuxовый . Проблема в следующем: если запускаем pg_dump из Linix создаётся дамп с командами вот такими для создания OPERATOR с указанием PROCEDURE-это правильно и срабатывает pg_restore и psql без проблем по вышеуказанной статье.
CREATE OPERATOR имя (
PROCEDURE = имя_функции
[, LEFTARG = тип_слева ] [, RIGHTARG = тип_справа ]
[, COMMUTATOR = коммут_оператор ] [, NEGATOR = обратный_оператор ]
[, RESTRICT = процедура_ограничения ] [, JOIN = процедура_соединения ]
[, HASHES ] [, MERGES ]
)
при запуске pg_dump из винды для бекапа базы из linux создаётся OPERATOR где указывается FUNCTION
CREATE OPERATOR имя (
FUNCTION = имя_функции
[, LEFTARG = тип_слева ] [, RIGHTARG = тип_справа ]
[, COMMUTATOR = коммут_оператор ] [, NEGATOR = обратный_оператор ]
[, RESTRICT = процедура_ограничения ] [, JOIN = процедура_соединения ]
[, HASHES ] [, MERGES ]
)
ЭТА ФИЧА может быть только на некоторых конфигурациях 1с 8.2 8.3 , точно выловил на Комплексной и Кортес, на Бухгалтерии и Зуп проблем таких нет.
pg_dump ОБЯЗАТЕЛЬНО надо использовать той версии на версию которого будет делаться востановление.
Если сервер куда будет происходит восстановление Postgresql 11 , версия pg_dump тоже должна быть не ниже 11. Если сделали pg_dump 11 версии, восстановить на сервер Postgresql 9 версии вероятно не получиться. Если сделали сделали pg_dump 9 ,восстановление на Posgtresql 11 так же может вызвать затруднения(не всегда и не на всех application).
Я сделал скрипт которому ты в кроне указываешь названия баз для бэкапа, таким образом меня список нужных баз уже в кроне, что удобнее, чем переписывать сам скрипт, имхо.
#!/bin/bash
set -e -u -o pipefail
db_list=( "$@" )
SHORTHOSTNAME="${HOSTNAME/.*/}"
DATE="$(printf '%(%Y-%m-%d)T')"
DIRECTORY="/var/backup/postgresql/$DATE"
if [ ! -d "$DIRECTORY" ]; then
echo "Creating backup directory: $DIRECTORY"
mkdir --parents "$DIRECTORY"
fi
PROC_NUM=$(( $(nproc) / 2 ))
if [ "$PROC_NUM" -lt 1 ]; then
PROC_NUM=1
fi
for i in ${db_list[@]}; do
TIME="$(printf '%(%H-%M-%S)T')"
FILE="${DATE}_${TIME}_${i}_pg_dump.sql.gz"
echo "Dumping PostgreSQL to $DIRECTORY/$FILE"
sudo -u postgres pg_dump -d $i --clean --verbose | pigz --processes "$PROC_NUM" --stdout > "$DIRECTORY/$FILE"
done
Если очень надо, то можно использовать массив данных db_list чтобы распараллелить по процессам.
В любом случае, спасибо за еще одно мнение.
Автор, спасибо за статью. Есть одно дополнение для конфигураций 1С УПП, при котором pg_dump не работает.
Если размер таблицы public.config (конфигурации 1С) превысит 1Гб, а для PostgreSQL это является пределом для поля большого размера, после чтения и распаковки в стандартный поток вывода stdout pg_dump.exe завершится с ошибкой:
pg_dump: Ошибка выгрузки таблицы "config": сбой в PQgetResult().
pg_dump: Сообщение об ошибке с сервера: invalid memory alloc request size 11173708065
pg_dump: Выполнялась команда: COPY public.config (filename, creation, modified, attributes, datasize, binarydata) TO stdout;
Резервную копию тогда надо будет делать вот так: http://infostart.msk.ru/public/956734/
_
Вот мой скрипт:
#!/bin/sh
# Скрипт резервного копирования баз данных PostgreSQL
# Копирование базы 1С на лету во время работы пользователей с сохранением целостности с помощью команд pg_dump.exe, psql.exe
# Для этого в общем случае алгоритм следующий:
# Шаг 1. Выгружаем с помощью pg_dump все таблицы из базы данных, кроме данных таблицы config (т.е. для config выгружаем только ее схему)
# Шаг 2. Выгружаем с помощью psql данные таблицы public.config с помощью COPY WITH BINARY
# Шаг 3. Производим очистку и переиндексацю базы данных
PATH=/etc:/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin
#Логин и пароль пользователя, имеющего право выполнять резервные копии баз данных
dbUser=postgres
PGPASSWORD=password
export PGPASSWORD
slog=/var/log/postgresql/service.log
#Путь резервных копий
pathB=/backups/sdb1/sql/databases
#Резервирование базы данных
#Задаем имя резервируемой базы данных
database=gilev
#Задаем переменную date для того чтобы резервная копия базы данных и таблицы config имели одно и то же время
date=$(date "+%Y-%m-%d_%H-%M")
# Записываем информацию в лог с секундами
echo "`date +"%Y-%m-%d_%H-%M-%S"` Запуск резервного копирования базы - ${database}" >> ${slog}
#Выгружаем все таблицы из базы данных, кроме данных таблицы config (т.е. для config выгружаем только ее схему)
#pg_dump -U $dbUser --exclude-table-data=config $database | pigz > $pathB/${database}_${date}_without_public.config.sql.gz
#Выгружаем в несколько потоков (10 потоков)
pg_dump --format=directory --jobs=10 --blobs -U $dbUser --exclude-table-data=config --file=$pathB/${database}_${date}_without_public.config $database
#Выгружаем данные таблицы public.config с помощью COPY WITH BINARY:
psql -U $dbUser --command="COPY public.config TO '$pathB/${database}_${date}_public.config.sql' WITH BINARY;" $database
# Записываем информацию в лог с секундами
echo "`date +"%Y-%m-%d_%H-%M-%S"` Резервное копирование базы - ${database}" выполнено >> ${slog}
#Для выгрузки в сжатом состоянии. Как показала практика, не поддается сжатию
#psql -U $dbUser --command="COPY public.config TO PROGRAM 'pigz -0 > $pathB/${database}_${date}_public.config.sql.gz' WITH BINARY;" $database
#Выполняем очистку и анализ базы данных 1С
echo "`date +"%Y-%m-%d_%H-%M-%S"` Запуск очистки базы - ${database}" >> ${slog}
vacuumdb -U $dbUser --full --analyze --dbname=${database}
echo "`date +"%Y-%m-%d_%H-%M-%S"` Очистка базы - ${database} выполнена" >> ${slog}
# Переиндексировать базу
echo "`date +"%Y-%m-%d_%H-%M-%S"` Запуск реиндексации базы - ${database}" >> ${slog}
reindexdb -U $dbUser --dbname=${database}
echo "`date +"%Y-%m-%d_%H-%M-%S"` Реиндексация базы - ${database} выполнена" >> ${slog}
# Удаляем в папке с бэкапами архивы старше 31-х дней
find /${pathB} -type f -mtime +31 -exec rm -rf {} \;
find /${pathB} -type d -mtime +31 -exec rm -rf {} \;
unset PGPASSWORD
Спасибо за информацию.
Подскажите, этот скрипт для выполнения bat-ником из по windows?
Нет, это скрипт на bash для linux.
Поддерживает ли Postgres дифференциальные бекапы, как вы решаете это проблему?
Не знаю, никак не решаю. Делаю полные выгрузки. Я так понимаю, что понятие дифференциального бэкапа не применимо к базам данных. Там другие механизмы используются. К примеру, полный бэкап и потом журнал транзакций нему.
Допустим если мне нужно откатить базу на 3 часа назад, мне что каждые 3 часа делать полный бекап. MS SQL это все решено.
Это во всех бд решено так или иначе. В postgres используется WAL журнал для таких целей - https://postgrespro.ru/docs/postgrespro/10/continuous-archiving
Спасибо дружище!
Не знаю в способе ли дело, но после восстановления бэкапа в базу не зайти ))) "Невосстановимая ошибка
Ошибка при выполнении запроса POST к ресурсу /e1cib/login:
по причине:
Ошибка при выполнении операции с информационной базой
Запись не найдена в менеджере имен базы данных."
Менял релизы платформы 1с (8.3.12.1595, 8.3.12.1790, 8.3.14.1565) , менял версии PostgreSQL ( 9.6, 10.5 )
Тестирован на нескольких базах которые находятся в разных местах, на разных серверах...
Так что коллеги этот PostgreSQL на Ваш страх и риск
Я 100% проверял все это и не раз. При обновлении postgresql делал дамп на старой версии и заливал в новую. Используется стандартная утилита pg_dump. Тут нечему не работать. Возможно проблема в чем-то другом.
К Вам никаких претензий. Пару месяцев назад у меня тоже получилось восстановить 5 баз разом, бэкапы были сделаны по Вашему примеру. Но после этого удачного случая не смог более его повторить... Я тут написал чтобы люди понимали что что-то может пойти не так и особо не расслаблялись. Сейчас я делаю автоматические бэкапы .dt файлов средствами 1с, проверенный вариант годами. Сама связка Linux + 1c + PostgreSQL вполне устраивает, но бэкапы PostgreSQL это конечно удручает. А может это и не в бэкапах PostgreSQL дело, а просто в кривых руках программеров 1с...
Тут есть нюансы. Я знаю, что начиная с версии 8.3.14 1с не работает с базами postgresql 9.x Я уже не помню точно, какую ошибку выдает, но возможно именно такую же, как вы описали. То есть тут много нюансов именно по всей связке. Сами бэкапы postgresql через pg_dump работают надежно.
Помогу тебе.. Уважаемые СИСКЫ !! базу не добавлять надо в 1с после восстановления надо а СОЗДАТЬ УКАЗЫВАЯ ИМЯ ВОССТАНОВЛЕННОЙ БАЗЫ!!! при добавлении 1ска не втыкается что от нее хотят и пути не видит.
Как в вашем скрипте перечислить базы 1с? Просто копировать рядом такую же строку, только менять имя базы ?
В общем случае да. Только надо не забыть строки лога поменять и имя файла, куда база будет записываться. Все разное должно быть.
Так можно делать?
#!/bin/sh
# Записываем информацию в лог
echo "`date +"%Y-%m-%d_%H-%M-%S"` Start vacuum BASE1" >> /var/log/postgresql/service.log
echo "`date +"%Y-%m-%d_%H-%M-%S"` Start vacuum BASE2" >> /var/log/postgresql/service.log
# Выполняем очистку и анализ базы данных
/usr/bin/vacuumdb --full --analyze --username postgres --dbname BASE1
echo "`date +"%Y-%m-%d_%H-%M-%S"` End vacuum BASE1" >> /var/log/postgresql/service.log
/usr/bin/vacuumdb --full --analyze --username postgres --dbname BASE2
echo "`date +"%Y-%m-%d_%H-%M-%S"` End vacuum BASE2" >> /var/log/postgresql/service.log
sleep 3
echo "`date +"%Y-%m-%d_%H-%M-%S"` Start reindex BASE1" >> /var/log/postgresql/service.log
echo "`date +"%Y-%m-%d_%H-%M-%S"` Start reindex BASE2" >> /var/log/postgresql/service.log
# Переиндексировать базу
/usr/bin/reindexdb --username postgres --dbname BASE1
echo "`date +"%Y-%m-%d_%H-%M-%S"` End reindex BASE1" >> /var/log/postgresql/service.log
/usr/bin/reindexdb --username postgres --dbname BASE2
echo "`date +"%Y-%m-%d_%H-%M-%S"` End reindex BASE2" >> /var/log/postgresql/service.log
Можно, но логичнее сделать вот так:
Хорошо бы увидеть в обновлении статьи как Вы решаете задачу одним скриптом с бекапом, вакуумом и индексированием одновременно 5 баз, к примеру :-)
Пожалуйста, можете добавить в статью. Добавить бекаприрование не составит труда.
#!/bin/bash
IFS=$'\n'
DATA=`date +"%Y.%m.%d %H:%M"`
echo "$DATA Start Postgres DB service" >> /var/log/postgresql/service.log
for var in `psql -l -p 6432 | awk '{ print $1,$2}' | grep -v "(" | grep -v "template*" | grep -v "test*" | grep -v "Список" | grep -v "Имя" | grep -v "+" | sed 's,|,,g' | sed 's/[ \t]*$//' | awk 'NF > 0'`
do
#echo $var
vacuumdb -p 6432 --full --analyze --dbname $var
reindexdb -p 6432 --dbname $var
done
echo "`date +"%Y.%m.%d %H:%M"` END Postgres DB service" >> /var/log/postgresql/service.log
echo "----------------------------------------------------" >> /var/log/postgresql/service.log
А в чем тут проблема? Можно последовательно работать с каждой базой, перечислив базы вручную, или как предложил автор выше, циклом.
Проблема в том, что пример выше выполняет команды ПОСЛЕДОВАТЕЛЬНО. А нужно чтобы скрипт запускал каждую команду в фоне. Чтобы команды выполнялись ПАРАЛЛЕЛЬНО. Так как приходится ждать пока скрипт забекапит одну базу, потом приступит ко второй, затем третьей и тд. А надо, чтобы р-раз и htop показывает одновременный pg_dump каждой базы в отдельном процессе и нагружает соответственно ВСЕ ядра. А не 1.
вот надёргал из инетов что-то похожее https://pastebin.com/KRSnzcuB
А какой в этом смысл? Как мне кажется, дамп базы данных в первую очередь нагружает по полной программе диск, а не процессор. Распараллеливание дампа приведет только к увеличению времени выполнения процедуры, а не уменьшению.
И вообще, хотелось бы увидеть от Вас обзор на barman :-)
Спасибо за статью!
createdb --username postgres -T template0 base1c-restored
Чем отличается template0 от template1?
Отвечу сам себе :)
template0 - создать пустую базу данных без дополнительных объектов
template1 - создать пустую базу данных но с какие-либо дополнениями
Подробнее описано тут: https://postgrespro.ru/docs/postgresql/9.6/app-pgrestore
статья хуйня. после рестора такого бэкапа 1с орет на несоответствие структуры
Способ рабочий. Я регулярно бэкаплю сервера по такой схеме. И проверяю восстановление.
как проверяете? разворачиваете, заходите и всё?
Разворачиваю, захожу в базу, делаю выгрузку в dt.
подскажите пожалуйста, а обязательно ли делать - Обновление статистики и реиндексация, а в конфигах postgres есть параметр autovacum
Не обязательно. Но работать будет быстрее после обновления статистики. Не вижу причин ее не делать.
спасибо за ответ
Уважаемый Zerox, мне очень нужна ваша помощь по базам 1С в бд postgresql, хотел бы задать вам пару вопросов, думаю вы бы смогли мне помочь! прошу вас откликнутся на почту arm-gora@yandex.ru спасибо Вам большое
Добрый день. Не подскажете, как с паролем скрипт запускать? я все не могу добиться работы через файл .pgpass.
В файле pg_hba.conf строка такая должна быть?
local all all peer
D cronetab, где
# Бэкап и обслуживание БД
1 3 * * * root /root/bin/all-sql.sh
Вместо root укажите postgres, тогда команды внутри скрипта будут запускаться от имени пользователя postgres и пароль для авторизации не понадобится. Своего рода использование su - postgres
Автор!
Спасибо тебе за то, что ты есть и публикуешь свои наработки!
Отличная статья, спасибо!