
Некоторое время назад я показал, как очень быстро можно организовать сбор логов с web сервера в Elastic Cloud. Сегодня расскажу, как сохранять не просто логи, а php session id посетителей сайта, чтобы потом анализировать их перемещения по нему. Инструкция будет универсальная и подойдет для всех, кто занимается сбором логов в Elastic Stack с обработкой в filebeat или logstash.
На углубленном курсе "Архитектура современных компьютерных сетей" вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Введение
Суть задачи сводится к тому, чтобы добавить новое поле в index elasticsearch, в котором будет содержаться id сессии пользователя в простом текстовом виде. Далее по этому полю можно будет делать группировку, чтобы посмотреть перемещение пользователя по сайту и другую информацию о его запросах.
Для того, чтобы организовать просмотр перемещения посетителя по сайту, нам необходимо выводить в лог apache информацию об этой сессии и реальном ip адресе клиента. Рассказываю далее, как все это сделать.
Я буду показывать настройку на примере сайта на Bitrix. В WordPress все это настраивается точно так же, один в один.
Реальный ip адрес посетителя bitrix в логах apache
Если вы используете преднастроенное окружение bitrixenv, то ничего особенного для вывода реального ip адреса в лог apache делать не надо. Напомню, для тех, кто не в курсе, о чем идет речь. Bitrixenv - набор рецептов ansible, которые автоматически разворачивают веб сервер на основе nginx и apache. На nginx приходят все запросы клиентов, а дальше проксируются на apache для исполнения php кода. Если ничего дополнительно не настраивать, то в логах apache все запросы будут с ip адреса 127.0.0.1.
При этом, в bitrixenv в настройках nginx для сайтов указано, что реальный ip адрес посетителя надо записывать в отдельный заголовок.
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
В apache можно взять информацию из этого заголовка и поместить сразу в лог файл.
LogFormat "%{X-Forwarded-For}i %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"" combined
Все, этого достаточно, чтобы в лог файле apache выводился реальный ip адрес посетителя. Теперь разберемся с session id.
Вывод Session ID посетителя Битрикс в лог apache

Каждому посетителю сайта на Битриксе прописывается в Cookie PHPSESSID с уникальным идентификатором сеанса. Он остается постоянным в рамках одного посещения. По крайней мере на первый взгляд это так. Я не занимался подробно исследованием того, как это работает. Задачи не стояло.

Host: 10.20.1.5 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8 Accept-Language: ru-RU,ru;q=0.8,en-US;q=0.5,en;q=0.3 Accept-Encoding: gzip, deflate Connection: keep-alive Referer: http://10.20.1.5/photo/ Cookie: BITRIX_SM_GUEST_ID=2; BITRIX_SM_LAST_VISIT=22.04.2020+15%3A19%3A08; BITRIX_CONVERSION_CONTEXT_s1=conversion_visit_day; PHPSESSID=f62568ad389b9ef0bba3c6d3650f7155; BITRIX_SM_SOUND_LOGIN_PLAYED=Y Upgrade-Insecure-Requests: 1 Pragma: no-cache Cache-Control: no-cache
Идентификатор PHPSESSID мы и будем выводить в лог файл apache. Сделать это очень просто, так как apache по умолчанию умеет анализировать куки и выводить информацию из них в лог. Делается это вот так.
LogFormat "%{X-Forwarded-For}i %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\" %{PHPSESSID}C" combined
Если хотите вывести в лог все содержимое куки, то используйте такую конструкцию - %{Cookie}i. В нашем случае это излишне. Хватит только PHPSESSID. Перезапускаем apache и смотрим, что у нас будет в логе.
10.20.1.1 - - [22/Apr/2020:15:45:59 +0300] "GET / HTTP/1.0" 200 47747 "http://10.20.1.5/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:75.0) Gecko/20100101 Firefox/75.0" f62568ad389b9ef0bba3c6d3650f7155
IP адрес и ID сессии присутствуют в логе. В данном случае ip адрес серый, потому что тестовое окружение настроено в локальной сети. Теперь нам нужно настроить grok фильтр elastic на парсинг измененного лог файла. Затем добавить новое поле в индекс elasticsearch, чтобы с ним можно было работать.
Добавление произвольного поля в Elastic Cloud
Перемещаемся в Kibana. Первым делом проверим, какой pipeline для обработки логов загружен в Elasticsearch. Для этого идем в интерфейс Kibana, в раздел Dev Tools -> Console и вводим туда запрос
GET _ingest/pipeline/filebeat-*access*
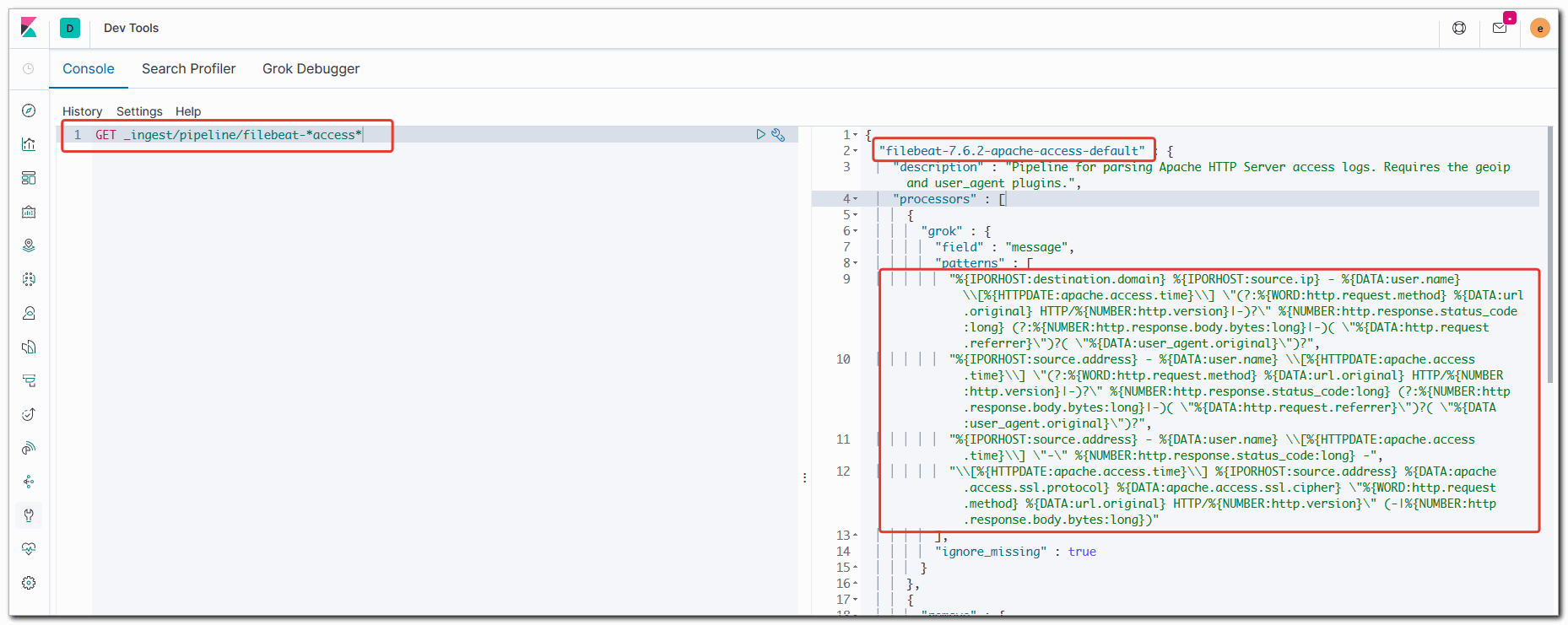
Запоминаем точное название пайплайна - filebeat-7.6.2-apache-access-default. Напоминаю, что такое pipeline. Мы используем легковесный filebeat для передачи логов в elastic. В отличие от logstash, filebeat сам не умеет выполнять сложный парсинг логов на основе grok фильтров. Этим занимается сама нода elastic на основе pipeline, который ей передает filebeat.
Теперь идем на целевой сервер, где работает apache и filebeat. Дефолтный pipeline должен располагаться в файле /usr/share/filebeat/module/apache/access/ingest/default.json. Необходимо проверить, что его содержимое соответствует тому, что было в выводе в консоли Kibana. В дефолтной установке это должно быть так.
Нам нужно изменить этот pipeline. Для этого останавливаем filebeat.
# systemctl stop filebeat
Редактируем default.json, предварительно сохранив копию исходного файла на всякий случай.
Берем следующий блок:
"grok": {
"field": "message",
"patterns": [
"%{IPORHOST:destination.domain} %{IPORHOST:source.ip} - %{DATA:user.name} \\[%{HTTPDATE:apache.access.time}\\] \"(?:%{WORD:http.request.method} %{DATA:url.original} HTTP/%{NUMBER:http.version}|-)?\" %{NUMBER:http.response.status_code:long} (?:%{NUMBER:http.response.body.bytes:long}|-)( \"%{DATA:http.request.referrer}\")?( \"%{DATA:user_agent.original}\")?",
"%{IPORHOST:source.address} - %{DATA:user.name} \\[%{HTTPDATE:apache.access.time}\\] \"(?:%{WORD:http.request.method} %{DATA:url.original} HTTP/%{NUMBER:http.version}|-)?\" %{NUMBER:http.response.status_code:long} (?:%{NUMBER:http.response.body.bytes:long}|-)( \"%{DATA:http.request.referrer}\")?( \"%{DATA:user_agent.original}\")?",
"%{IPORHOST:source.address} - %{DATA:user.name} \\[%{HTTPDATE:apache.access.time}\\] \"-\" %{NUMBER:http.response.status_code:long} -",
"\\[%{HTTPDATE:apache.access.time}\\] %{IPORHOST:source.address} %{DATA:apache.access.ssl.protocol} %{DATA:apache.access.ssl.cipher} \"%{WORD:http.request.method} %{DATA:url.original} HTTP/%{NUMBER:http.version}\" (-|%{NUMBER:http.response.body.bytes:long})"
],
И приводим его к следующему виду:
"grok": {
"field": "message",
"patterns": [
"%{IPORHOST:source.address} - %{DATA:user.name} \\[%{HTTPDATE:apache.access.time}\\] \"(?:%{WORD:http.request.method} %{DATA:url.original} HTTP/%{NUMBER:http.version}|-)?\" %{NUMBER:http.response.status_code:long} (?:%{NUMBER:http.response.body.bytes:long}|-)( \"%{DATA:http.request.referrer}\")?( \"%{DATA:user_agent.original}\")? ?%{WORD:session_id}"
],
Важно соблюдать структуру файла, все табуляции, отступы и пробелы.
Мы добавили в конец новое поле для парсинга через встроенный grok фильтр ?%{WORD:session_id} и удалили лишние фильтры, которые нужны для совместимости с разными версиями apache. Предложенный фильтр проверен на версии Apache/2.4.6 и его стандартном формате логов, плюс текстовое поле с сессией.
Так же для удобства рекомендую удалить строки ниже:
{
"remove": {
"field": "message"
}
},
Тогда в elastic будут в том числе сохраняться строки из лога в оригинальном виде, а не только распарсенные значения. Это бывает полезно для разбора полетов. По-умолчанию они удаляются для экономии места.
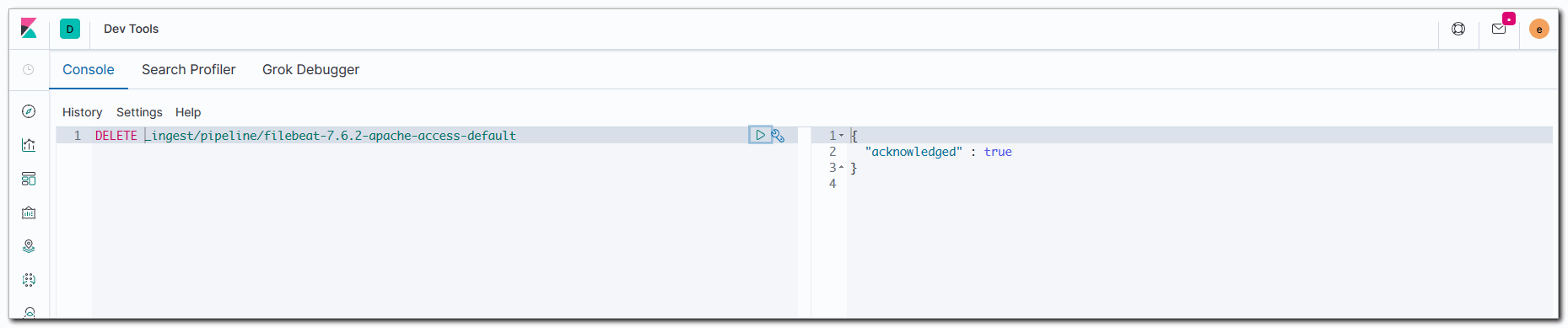
Теперь возвращаемся в консоль Kibana и удаляем текущий pipeline из elastic, так как мы туда загрузим новый.
DELETE _ingest/pipeline/filebeat-7.6.2-apache-access-default
Идем на сервер и запускаем filebeat
# systemctl start filebeat
Смотрим его лог на наличие ошибок. Их быть не должно. Если есть, то надо проверять внимательно default.json, не нарушен ли его формат при редактировании. Расположение пробелов и отступов важно. При проверке статуса сервиса ошибок быть не должно.
# systemctl status filebeat
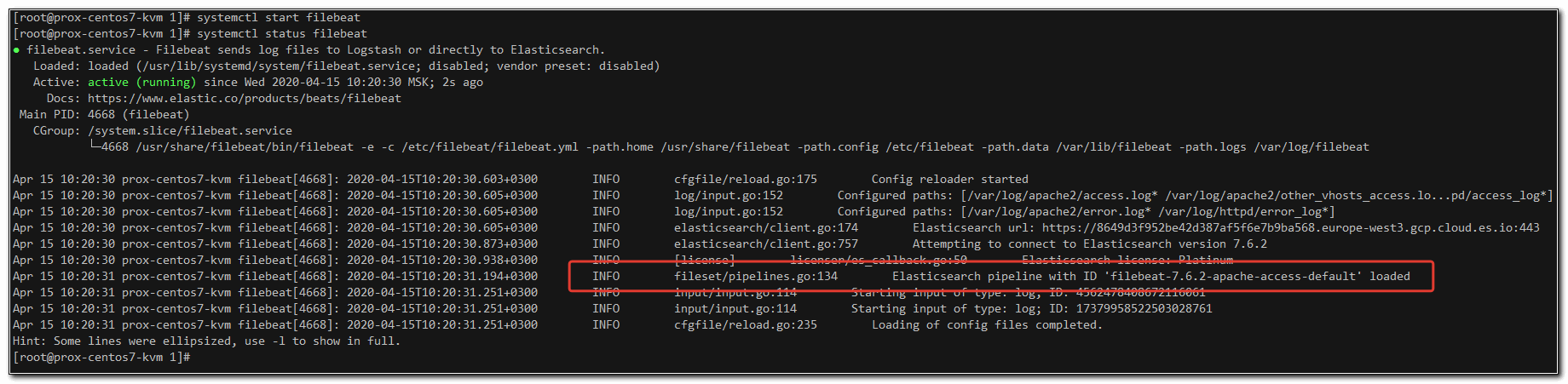
Видим, что новый pipeline загружен. Идем в консоль Kibana и проверяем, что это так.
GET _ingest/pipeline/filebeat-7.6.2-apache-access-default
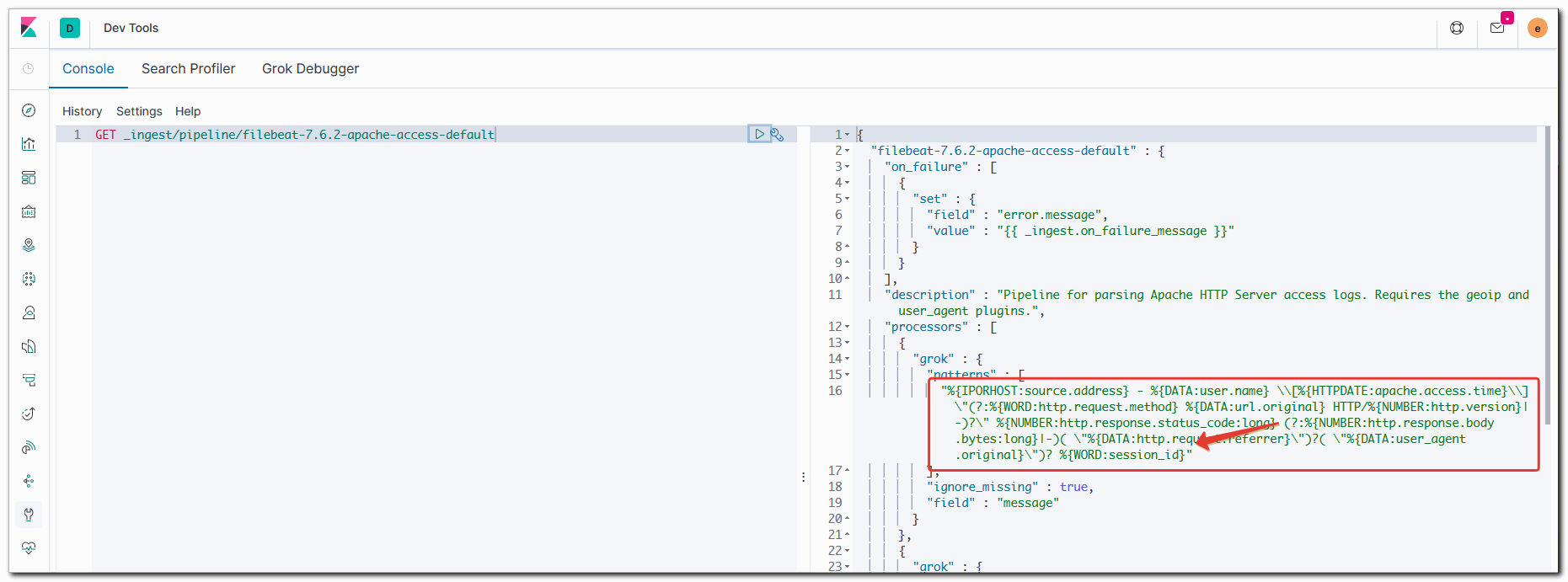
Идем в Discovery и проверяем наличие нового поля session_id. Рядом с ним должен быть восклицательный знак.
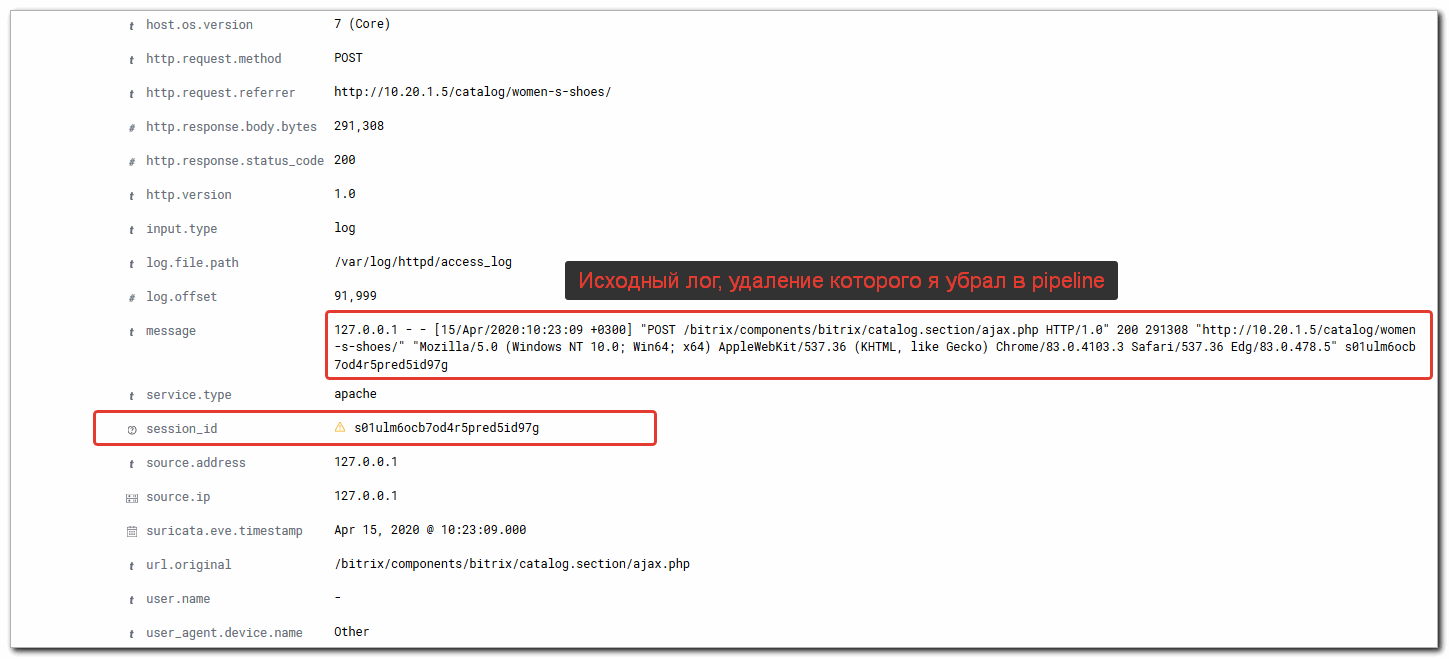
Идем в Management -> Kibana -> Index Patterns. Выбираем индекс filebeat-* и жмем справа вверху на обновление - refresh field list.

После этого тут же проверяем через поиск, что в индексе появилось новое поле session_id.

Теперь можно вернуться в Discovery и осуществлять поиск по полю session_id.
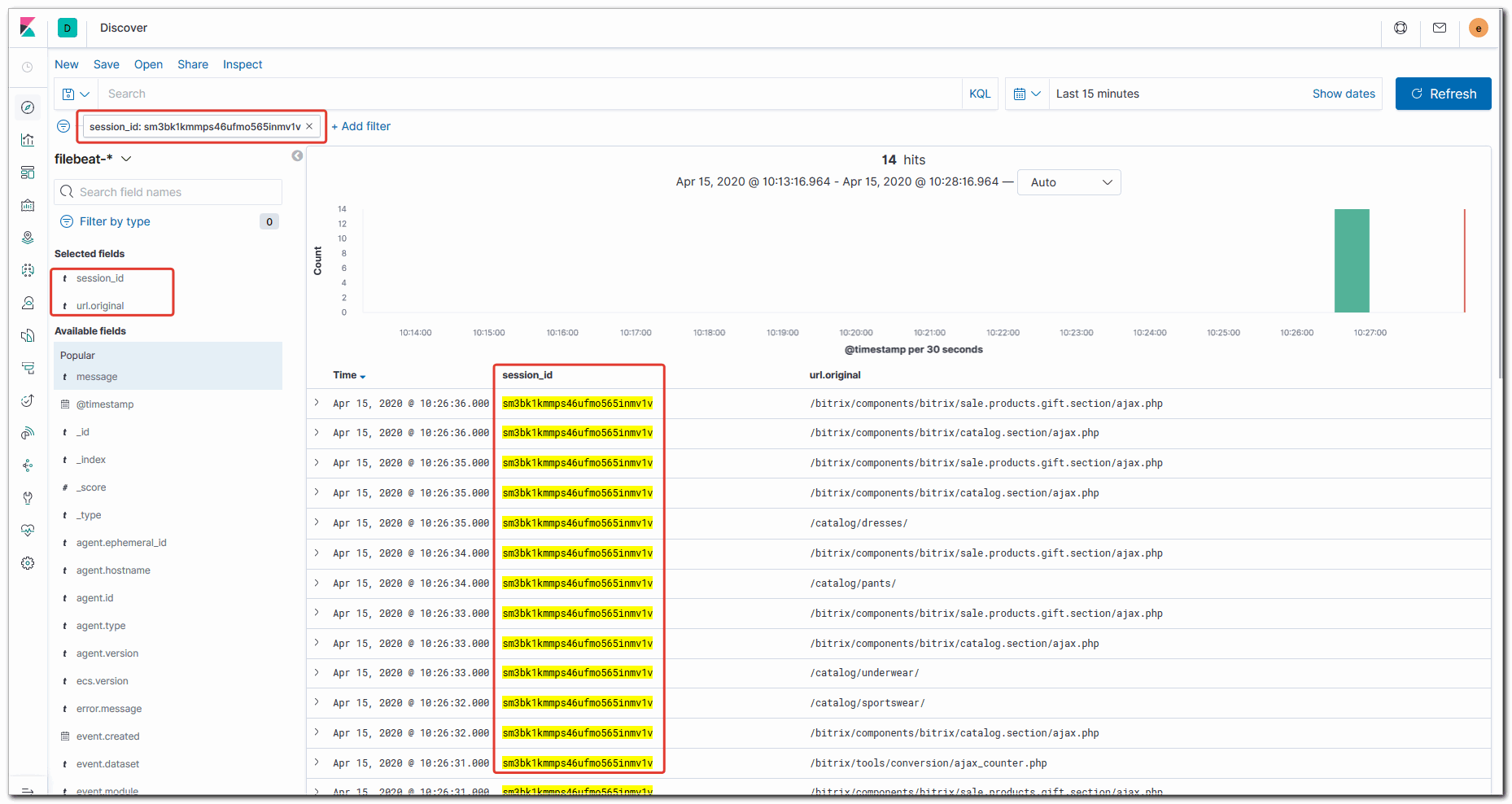
На этом все. Новое поле в elasticsearch добавлено. Можно использовать в визуализациях и дашбордах.
Часто задаваемые вопросы по теме статьи (FAQ)
Да, подойдет. Формат grok фильтров одинаков и в ingest node, где в данном случае происходит обработка логов, и в logstash.
Принципиальной разницы в настройке нет. Это абсолютно одинаковые продукты. Первый развернут в публичном облаке, второй на ваших собственных серверах.
Да, будут. В фильтре перед %{WORD:session_id} стоит вопросительный знак, который делает необязательным наличие этой строки в логе.
Заключение
Еще один пример, как можно быстро и легко организовать сбор и анализ логов с помощью Elastic Stack. Другие примеры смотрите у меня в разделе, посвящённому этой теме. Если есть советы и замечания по данному материалу, делитесь в комментариях. Было бы здорово, если бы кто-то показал свои рабочие Dashboards в Kibana. Всегда интересно посмотреть, кто как облегчает себе работу с помощью удобных визуализаций.
На углубленном курсе "Архитектура современных компьютерных сетей" вы с нуля научитесь работать с Wireshark и «под микроскопом» изучите работу сетевых протоколов. На протяжении курса надо будет выполнить более пятидесяти лабораторных работ в Wireshark.
Реклама ИП Скоромнов Д.А. ИНН 331403723315

Добрый день коллега! Спасибо за то что делишься знаниями.
Я тоже немного поделюсь, если не возражаешь.
Для того чтобы апач писал в лог реальный IP, а он передается из запроса, который передает прокси, достаточно поменять %h на %a
LogFormat "%a %l %u %t \"%r\" %>s %b \"%{Referer}i\" \"%{User-Agent}i\"
http://httpd.apache.org/docs/current/mod/mod_log_config.html
Так же в лог апач добавить любую переменную из php.
https://www.php.net/manual/ru/function.apache-note.php
Я добавлю id-пользователя из битрикс. Часто нужно разбирать инциденты. Сессии посещения кстати и битрикс хранит, но id-пользователя в логе апач удобнее.
Так же не забыть что эта функция доступна только в модуле php для апач, в cli её не будет, это нужно предусмотреть в коде.
Может по этому поводу напишу статью на хабре...
Насколько я понимаю, слежение за пользователем лучше всего реализовывать на уровне приложения, расставляя какие-то метки в запросах, или как-то еще. Не сильно разбираюсь. А тут типовой сайт, который часто используют как есть, как и тот же wordpress. И вывод инфы о сессии из кук самый простой и доступный, который у меня сходу получилось настроить, когда такая потребность возникла.