
Сегодня открываю новый цикл статей, которые будут иметь непосредственное отношение к Devops и всему, что с этим связано. Начну с того, что расскажу, как установить и запустить кластер Kubernetes на собственном железе. Буду использовать установку через Kubespray с использованием ingress контроллера в кластере.
Содержание:
Цели статьи
- Коротко рассказать о том, что такое Kubernetes и для чего он нужен.
- Перечислить основные системные требования для разворачивания своего кластера Kubernetes.
- Выполнить непосредственно установку кластера на свое железо.
Введение
Хочу сразу обратить внимание на важный момент. У меня нет опыта промышленной эксплуатации кластера Kubernetes. Я нахожусь в состоянии обучения и исследования этого инструмента. Я прошел обучение Слёрм, это дало базовые знания и понимание принципов работы. Дальше стал разворачивать свои кластера и исследовать их. Изначально я не хотел писать статьи по этой теме до тех пор, пока не накопится достаточного опыта, но сейчас поменял свое мнение.
В рунете очень мало материалов по kubernetes с конкретикой и практикой, по которым можно было бы учиться. Думаю, что даже те знания, что есть сейчас у меня, будут многим полезны и интересны. Плюс, когда пишешь статьи, систематизируешь свои знания, запоминаешь и получаешь обратную связь. Ускоряется процесс обучения. Так что статьям по kubernetes и devops в целом быть. Думаю, что в ближайшее время я сфокусируюсь именно на этом.
Могу однозначно сказать, что если у вас есть необходимость в продакшене использовать Kubernetes, не тяните время и не откладывайте. Идите учиться на курсы. Самостоятельно вы не освоите в достаточном объеме материал, чтобы можно было переносить рабочую нагрузку в свой кластер. Очень много нюансов и подводных камней. Вы потратите больше времени, нервов и денег на самостоятельное освоение, если будете сами все с нуля изучать.
Лично у меня сейчас нет цели становиться администратором Kubernetes. Мой формат занятости не подразумевает обслуживание таких крупных систем и в планах этого тоже пока нет. Мне просто любопытно его исследовать, узнавать что-то новое, поэтому я этим занимаюсь. Знания карман не тянут, особенно современные и востребованные.
Kubernetes простыми словами
Попробую рассказать своими словами, что такое кластер Kubernetes для чайников, без отсылок к описаниям и документации. По своей сути это кластер для обслуживания docker контейнеров. Я слышал, что он может управлять не только докером, но практически ничего про это не знаю. Все в основном используют Kubernetes в связке с Docker.
В Kubernetes все крутится вокруг докер контейнеров. Это инструмент для их запуска, поднятия в случае падения, распределения ресурсов и т.д. Под капотом никакой магии. Там обычный docker, iptables, etcd, nat, dns, ceph, nfs и т.д. Просто все собрано в одном месте для решения конкретных задач. Таким образом, для эффективного управления кластером кубера нужен хороший бэкграунд классического linux админа. Без этих знаний будет трудно.
Есть много способов разворачивания кластера, так как он модульный. Не всем и не всегда нужны все его компоненты. К примеру, есть ingress контроллер для распределения входящих запросов по сервисам. Под капотом там обычный nginx в режиме proxy_pass, интегрированный в инфраструктуру кластера. Реализация сети в кластере тоже может быть разной - на уровне l2 или l3 с помощью тех или иных технологий. То же самое с файловыми хранилищами - локальные хранилища серверов, nfs хранилища, ceph и т.д.
В зависимости от того, какой функционал вам нужен, выбирается способ установки кластера kubernetes. Мы можете его установить полностью вручную, добавляя один компонент за другим. А можно использовать готовое средство, к примеру Kubespray, где весь необходимый для установки функционал реализуется с помощью ролей ansible. На Слёрме нас учили ставить кластер, используя свой форк компании southbridge. Они там немного изменили функционал под свои потребности. Я ставил и по их форку, и по оригинальному Kubespray. Основное отличие от классического Kubespray в том, что не используется kubeadm и сертификаты для общения компонентов кластера сразу выпускаются то ли на 10, то ли на 100 лет, не помню точно. В Kubespray сертификаты выписываются только на год и надо отдельно следить за их актуальности и своевременно обновлять.
Подведу итог о том, что же такое Kubernetes. Кубернетис - средство оркестрации (управления) контейнерами Docker. Это удобный инструмент для их автоматического запуска, выделения ресурсов, контроля состояния, обновления.
Кому нужен Kubernetes
Теперь порассуждаем о том, кому может пригодиться Kubernetes. В первую очередь это крупные компании со своими разработками в ИТ и командами программистов, для которых нужна большая производственная среда. Кластер Кубера добавляет серьезные накладные расходы на свое содержание, поэтому в небольших проектах выгоды от него не будет. Нет смысла объединить 5 маленьких виртуалок в кластер и эксплуатировать его. Если только для тестов. Или если вы точно уверены, что у проекта будет серьезный рост в ближайшее время. Под небольшую структуру и нагрузки лучше подыскать решения попроще, чем кубернетис.
Kubernetes накладывает серьезные требования к приложениям, которые в нем работают. Они должны быть изначально спроектированы и написаны по принципу микросервисов. У вас не получится взять и перенести в кластер сайт на wordpress или bitrix, даже если они очень большие и нагруженные. Вернее, перенести то вы их сможете, но вряд ли вам от этого будет проще и удобнее. Основное преимущество кластера - гибкость в разработке, деплое приложения, а так же в распределении ресурсов.
Примерная схема работы с кластером кубернетис на пальцах будет такая:
- Разработчики какого-то одного сервиса проекта выпускают обновление, запушив его в репозиторий.
- Система сборки формирует докер контейнер с этими изменениями и кладет в registry.
- Контейнер уезжает на тесты и если все в порядке, выкатывается в продакшн кластер kubernetes.
Это я очень просто и условно описал. Все процессы после пуша кода в репозиторий могут быть автоматизированы. Команд разработчиков, как и микросервисов, может быть десятки. Они могут условно независимо друг от друга выкатывать обновления. У каждого сервиса могут быть свои языки программирования, свои системные требования, свои файловые хранилища и базы данных. Все эти сущности отдельно описываются в конфигурациях кластера. Каждый микросервис получает то, что ему нужно для работы.
Теперь смотрим на Bitrix или WordPress. Они являются монолитными приложениями, написанными на php с использованием базы Mysql. В них нет микросервисов. Вам нужно либо как-то разбивать их на части, либо постоянно выкатывать все целиком. Но в этом случае смысл кластера кубернетис теряется, его гибкость настроек и выделения ресурсов под потребности не используются. Вам проще поставить обычный балансер на вход, сделать несколько нод для обработки php и за ними кластер БД.
Резюмируя все сказанное. Kubernetes - нишевое решение под конкретные проекты. Оно подходит далеко не всем и не надо его пихать туда, где от него не будет толку. Думаю, находятся люди, которые так делают. Сужу по тому, что мне в комментариях к некоторым статьям, например, про установку zabbix, пишут, а почему вы не в докере его ставите. Люди не понимают, что такое докер, для чего он нужен и какие проблемы решает. Смысла в использовании zabbix в docker нет никакого вообще. Docker создан для удобной разработки и деплоя приложений в продакшн. Этакий расширенный пакетный менеджер. В первую очередь он инструмент разработчиков.
Системные требования
Как таковых жестких системных требований у Kubernetes нет. Он с очень маленьких установок расширяется до огромных кластеров. Для того, чтобы его просто попробовать и посмотреть, достаточно следующих виртуальных машин:
- 2-3 мастер ноды с 2 cpu и 4 gb ram
- ingress нода с 1 cpu и 2 gb ram
- рабочие ноды для контейнеров от 2 cpu и 4 gb ram
Для того, чтобы просто запустить кластер, достаточно буквально двух виртуальных машин, которые одновременно будут и мастер и рабочими нодами. Но я рекомендую сразу планировать более ли менее полную структуру, которую можно брать за основу для последующего превращения в рабочий кластер. Я буду разворачивать кластер на следующих виртуальных машинах.
| Название | IP | CPU | RAM | HDD |
| kub-master-1 | 10.1.4.36 | 2 | 4G | 50G |
| kub-master-2 | 10.1.4.37 | 2 | 4G | 50G |
| kub-master-3 | 10.1.4.38 | 2 | 4G | 50G |
| kub-ingress-1 | 10.1.4.39 | 2 | 4G | 50G |
| kub-node-1 | 10.1.4.32 | 2 | 4G | 50G |
| kub-node-2 | 10.1.4.33 | 2 | 4G | 50G |
В моем случае это виртуальные машины на двух гипервизорах Hyper-V. Как я уже сказал в системных требованиях, для теста ресурсов можно и чуть меньше дать, но у меня есть запас, поэтому я такие ресурсы выделил для кластера Kubernetes. Перед установкой кластера рекомендую сделать снепшоты чистых систем, чтобы можно было оперативно вернуться к исходному состоянию, если что-то пойдет не так. Вручную готовить и переустанавливать виртуалки хлопотно.
По гипервизорам виртуальные машины распределил следующим образом.
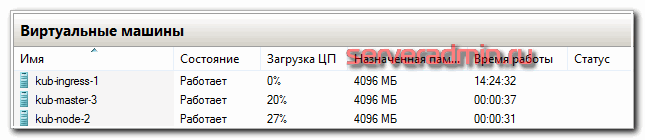
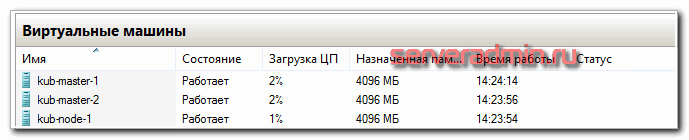
Упомяну про еще одну рекомендацию. Мастер ноды с etcd дают приличную нагрузку на диск. Их рекомендуется размещать на быстрых ssd дисках. Чем больше кластер - тем больше нагрузка. В наших тестах сойдет и hdd диск под мастер. Но если будете использовать в продакшене с учетом расширения и роста, лучше сразу планируйте быстрые диски под мастера.
Подготовка к установке
Кластер Kubernetes я буду разворачивать на виртуальных машинах Centos 7. На них она установлена в минимальной конфигурации. Напоминаю, что установка будет проходить с помощью Kubespray. Я рекомендую склонировать к себе репозиторий, чтобы у вас сохранилась версия kubespray, с которой вы устанавливали кластер. Это позволит без проблем создавать копию кластера для тестов, дебага, обновления и т.д. Я для этого использую свой сервер Gitlab. Рекомендую озаботиться его наличием. Он нам очень пригодится и дальше в процессе знакомства и изучения кластера.
На виртуальных машинах нужно отключить следующие сущности:
- SELinux (привет любителям безопасности, считающим, что selinux отключают только дилетанты).
- Swap.
- FirewallD, либо любой другой firewall.
На все сервера должен быть разрешен доступ пользователя root по ssh с одним и тем же паролем.
Установка кластера Kubernetes
Я буду устанавливать кластер Kubernetes с сервера kub-master-1. Установим на него некоторые пакеты, которые нам понадобятся в дальнейшем.
# yum install mc epel-release # yum install wget curl git screen python-pip sshpass
Теперь клонируем себе локально репозиторий kubespray.
# cd ~ # git clone https://github.com/kubernetes-sigs/kubespray
Устанавливаем зависимости kubespray через pip, которые перечислены в файле requirements.txt.
# cd kubespray # pip install -r requirements.txt
Теперь нам нужно заполнить инвентарь ansible, исходя из нашего набора серверов. Для этого скопируем стандартный инвентарь sample и будем редактировать его.
# cp -R ~/kubespray/inventory/sample ~/kubespray/inventory/dev
Приводим файл inventory.ini к следующему виду.
kub-master-1 ansible_host=10.1.4.36 ip=10.1.4.36 kub-master-2 ansible_host=10.1.4.37 ip=10.1.4.37 kub-master-3 ansible_host=10.1.4.38 ip=10.1.4.38 kub-ingress-1 ansible_host=10.1.4.39 ip=10.1.4.39 kub-node-1 ansible_host=10.1.4.32 ip=10.1.4.32 kub-node-2 ansible_host=10.1.4.33 ip=10.1.4.33 [kube-master] kub-master-1 kub-master-2 kub-master-3 [etcd] kub-master-1 kub-master-2 kub-master-3 [kube-node] kub-node-1 kub-node-2 kub-ingress-1 [kube-ingress] kub-ingress-1 [k8s-cluster:children] kube-master kube-node
В принципе, тут все понятно, если вы знакомы с работой ansible. Мы распределили хосты по ролям. Обращаю внимание, что сервер ingress по сути является обычной нодой, только с дополнительным функционалом, поэтому он присутствует в том числе в группе kube-node. Далее вы можете его использовать и как ingress, и как обычную ноду одновременно.
Теперь редактируем некоторые параметры. Для удобства восприятия, я их прокомментировал прямо тут, рядом со значениями. Переносить комментарии в реальные конфиги не надо. Они только для инфомрации на сайте. Начнем с файла ~/kubespray/inventory/dev/group_vars/all/all.yml. Добавляем туда параметры:
kubelet_load_modules: true # автоматом загружает модули в ядро системы, не спрашивая админа сервера kube_read_only_port: 10255 # порт для мониторинга кублетов, нужен, к примеру, для prometeus
В файл ~/kubespray/inventory/dev/group_vars/all/docker.yml добавляем:
docker_storage_options: -s overlay2 # использует сторейдж overlay2 для докера
В файл ~/kubespray/inventory/dev/group_vars/etcd.yml добавляем:
etcd_memory_limit: 0 # дефолтного ограничения в 512 мб может не хватать в больших кластерах, надо либо увеличить значение, либо отключить ограничение
В файл ~/kubespray/inventory/dev/group_vars/k8s-cluster/k8s-cluster.yml добавляем:
kube_network_plugin: flannel kube_proxy_mode: iptables kubeconfig_localhost: true # устанавливаем локально инструменты для управления кластером
Я буду использовать сетевой плагин flannel и iptables. Это хорошо проверенное и полностью готовое к production решение. Никаких особых настроек не требует, кроме пары параметров. Добавляем их в файл ~/kubespray/inventory/dev/group_vars/k8s-cluster/k8s-net-flannel.yml.
flannel_interface_regexp: '10\\.1\\.4\\.\\d{1,3}'
flannel_backend_type: "host-gw"
В данном случае 10\\.1\\.4\\.\\d{1,3} это регулярное выражение, которое описывает подсеть 10.1.4.0/24, в которой у меня размещены виртуальные машины под кластер. Если у вас подсеть машин для кластера, к примеру, 192.168.55.0, то регулярка будет 192\\.168\\.55\\.\\d{1,3}
Теперь настроим ingress. Добавляем параметры в ~/kubespray/inventory/dev/group_vars/k8s-cluster/addons.yml.
ingress_nginx_enabled: true
ingress_nginx_nodeselector:
node-role.kubernetes.io/ingress: "true" # указываем, какая метка должна быть у ноды, чтобы туда установился ingress
ingress_nginx_tolerations:
- key: "node-role.kubernetes.io/ingress"
operator: "Exists"
ingress_nginx_configmap:
server-tokens: "False"
proxy-body-size: "2048M"
proxy-buffer-size: "16k"
worker-shutdown-timeout: "180"
Создаем файл ~/kubespray/inventory/dev/group_vars/kube-ingress.yml и добавляем параметры:
node_labels: node.kubernetes.io/ingress: "true" # всем серверам в группе kube-ingress ставить соответствующую метку node_taints: - "node.kubernetes.io/ingress=:NoSchedule"
Трудно кратко и понятно описать настройки ingress, так как тут используются не тривиальные возможности kubernetes в виде taints и tolerations. Общий смысл в том, что мы задаем метку для ingress и поведение на основе этой метки. На ноды в группе kube-ingress ставится ограничение NoSchedule (не распределять поды на ноду) с помощью taints. Это ограничение могут преодолевать только только те, у кого в tolerations прописана метка ingress. Таким образом, на нодах ingress, кроме самого ингресса ничего запускаться не будет.
Вот и все. Мы готовы к тому, чтобы начать установку кластера Kubernetes. Запускаем ее с помощью ansible-playbook. Рекмоендую делать это в screen, чтобы не прерывался процесс из-за обрыва связи.
# ansible-playbook -u root -k -i inventory/dev/inventory.ini -b --diff cluster.yml
Процесс обычно длится 15-20 минут. У меня сервера старые, на hdd, длилось 30 минут. В конце вы должны увидеть примерно такую картину.
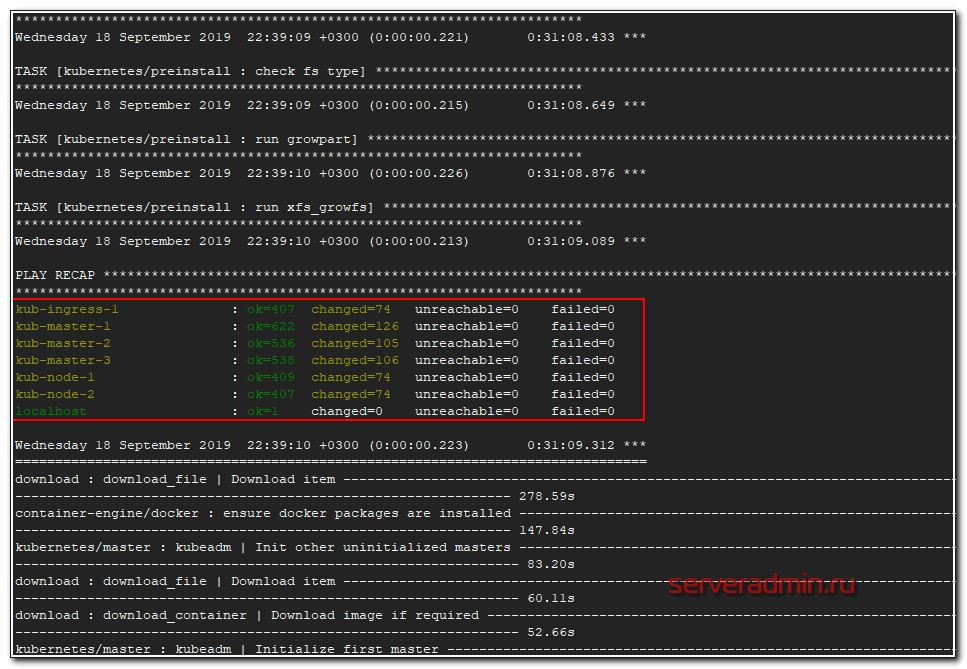
Ошибок быть не должно. Если есть ошибки, внимательно ищите их в выводе ansible и исправляйте. Основные ошибки возникают из-за неправильно заполненного инвентаря, из-за неправильной маски ip в свойствах flannel, из-за ошибок загрузки докер образов в процессе установки. После исправления ошибки можно запускать этот же плейбкук снова. Чаще всего все будет нормально донастроено.
Проверить состояние кластера можно командой:
# kubectl get nodes
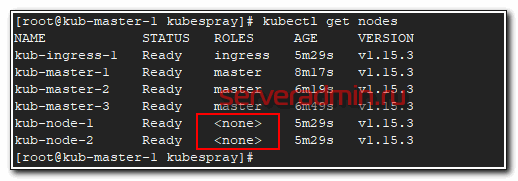
Вы увидите список всех нод и их роли. Я не знаю по какой причине, но при разворачивании кластера для этой статьи, у меня рабочие ноды не получили роли node. Исправить это можно командами.
# kubectl label node kub-node-1 node-role.kubernetes.io/node= # kubectl label node kub-node-2 node-role.kubernetes.io/node= # kubectl label node kub-ingress-1 node-role.kubernetes.io/node=
Для сервера ingress смотрите сами, хотите вы на него дополнительно вешать роль node или оставите только в качестве ingress контроллера. В продакшене лучше оставить его отдельно. Если у вас тестовый кластер, то можете объединить эти роли на одном сервере.
Если же вы захотите убрать какую-то роль, то команда будет такой.
# kubectl label node kub-ingress-1 node-role.kubernetes.io/node-
Мы убрали роль node на сервере kub-ingress-1. Проверяем снова состояние кластера.
# kubectl get nodes # kubectl cluster-info
Посмотреть подробную информацию о ноде можно командой.
# kubectl describe node kub-master-1
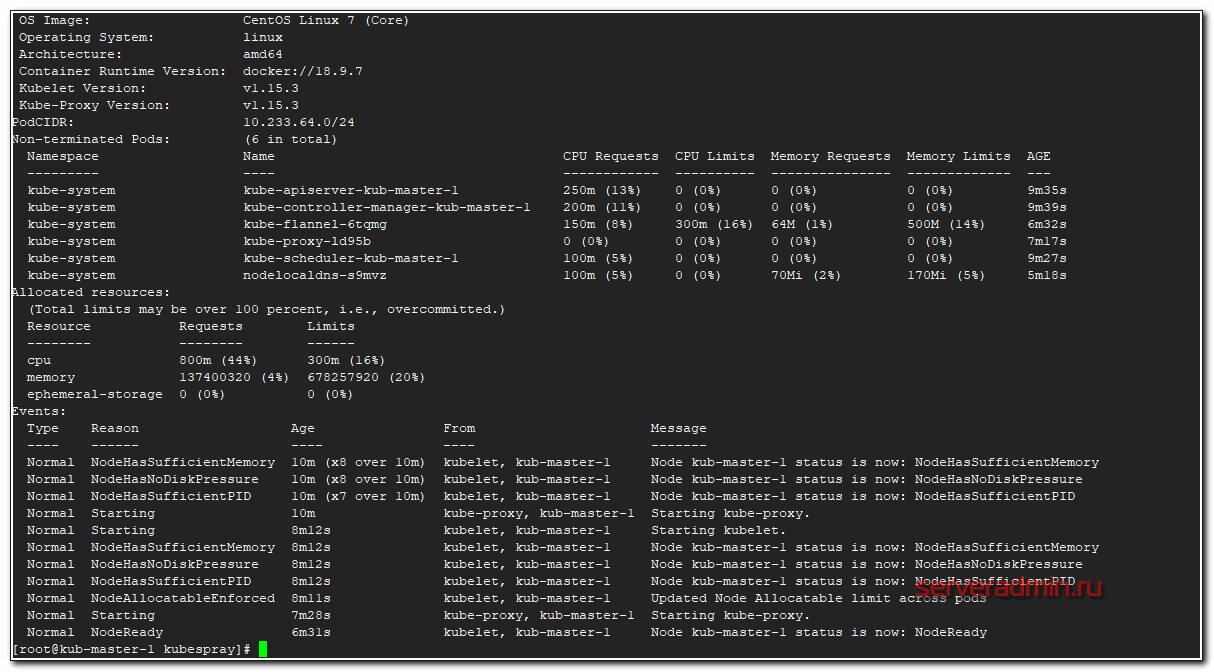
Рекомендую запомнить эту команду. Она очень пригодится в процессе эксплуатации кластера и дебага. Особое внимание на раздел Events. Именно он будет очень полезен при разборе ошибок на нодах.
Посмотрим список всех запущенных подов.
# kubectl get pod -A
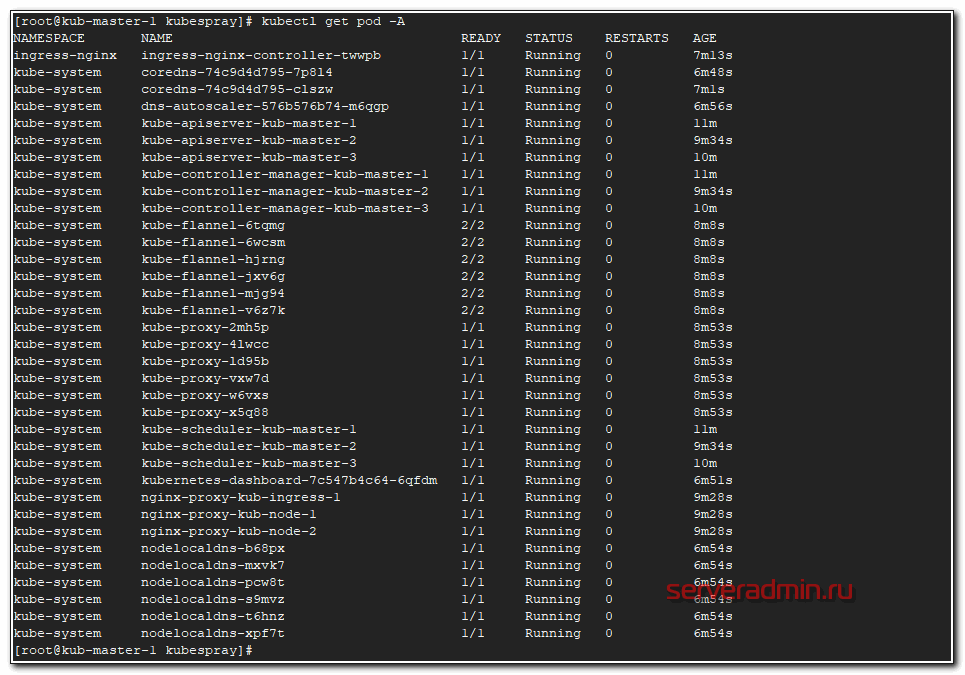
Они все должны быть в состоянии Running. Если это не так, то у вас какие-то ошибки, с которыми надо разбираться. В общем случае ошибок быть не должно, если вы все сделали правильно на моменте подготовки инвентаря.
На этом непосредственно установка кластера Kubernetes закончена. Он готов к эксплуатации. Если вы только знакомитесь с ним, то, думаю, вам совсем не понятно, что делать дальше и как его эксплуатировать. Об этом будут мои последующие статьи. Следите за обновлениями.
Проблема с сертификатами
Сразу обращаю внимание на очень важный момент. Необходимо тем или иным способом настроить мониторинг сертификатов, которые установил и настроил kubespray для обмена информацией мастеров. Сертификатов много и у них срок действия 1 год. Пока сертификаты не просрочились, их относительно легко обновлять. Если упустить этот момент, то все становится сложнее.
Я до конца не понял и не проработал вопрос обновления сертификатов, но это нужно будет сделать. Пока просто покажу, как за ними можно следить.
Сертификат api-server, порт 6443
# echo -n | openssl s_client -connect localhost:6443 2>&1 | sed -ne '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' | openssl x509 -text -noout | grep Not
Not Before: Sep 18 19:32:42 2019 GMT
Not After : Sep 17 19:32:42 2020 GMT
Сертификат controller manager, порт 10257.
# echo -n | openssl s_client -connect localhost:10257 2>&1 | sed -ne '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' | openssl x509 -text -noout | grep Not
Not Before: Sep 18 18:35:36 2019 GMT
Not After : Sep 17 18:35:36 2020 GMT
Сертификат scheduler, порт 10259.
# echo -n | openssl s_client -connect localhost:10259 2>&1 | sed -ne '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' | openssl x509 -text -noout | grep Not
Not Before: Sep 18 18:35:35 2019 GMT
Not After : Sep 17 18:35:35 2020 GMT
Это все разные сертификаты и они выпущены на год. Их надо будет не забыть обновить. А вот сертификат для etcd. Он выпущен на 100 лет.
# echo -n | openssl s_client -connect localhost:2379 2>&1 | sed -ne '/-BEGIN CERTIFICATE-/,/-END CERTIFICATE-/p' | openssl x509 -text -noout | grep Not
Not Before: Sep 18 19:28:50 2019 GMT
Not After : Aug 25 19:28:50 2119 GMT
Я не понял, почему этого не сделали для всех сервисов, а оставили такой головняк на потом. Если у кого-то есть информация о том, как корректно и безпроблемно обновлять сертификаты, прошу поделиться. Я пока видел только вариант с полуручным обновлением и раскидыванием этих сертификатов по мастерам.
Заключение
На этом начальную статью по Kubernetes заканчиваю. На выходе у нас получился рабочий кластер из трех мастер нод, двух рабочих нод и ingress контроллера. В последующих статьях я расскажу об основных сущностях kubernetes, как деплоить приложения в кластер с помощью Helm, как добавлять различные стореджи, как мониторить кластер и т.д. Да и в целом, хочу много о чем написать, но не знаю, как со временем будет.
В планах и git, и ansible, и prometeus, и teamcity, и кластер elasticsearch. К сожалению, доход с сайта не оправдывает временных затрат на написание статей, поэтому приходится писать их либо редко, либо поверхностно. Основное время уходит на текущие задачи по настройке и сопровождению.

Ого, что нашел в вашем блоге! Отлично! Я вас постоянно читаю и считаю ваши статьи крайне полезными.
Разрешите нести поправку?)))
Мастер нод если на них находится etcd должно быть нечетное количество, иначе беды не избежать. Убирайте двойку в самом начале статьи.
Спасибо за блог!
Привет!
А не подскажите где можно посмотреть инфу о опциях, выставляемых в ямлах кубеспрея? Большинство нативно понятно, но уверенности нет.
И, по моему несостыковка в статье:
ingress_nginx_nodeselector:
node-role.kubernetes.io/ingress: "true"
и:
node_labels:
node.kubernetes.io/ingress: "true"
Метки на ноды ставятся, но при установке ингресса нода ищется по роли
(хотя, не уверен, буду пробовать)
В данной статье не указана какая версия кубера ставится?, так как последний кубер уже сильно отличается по установке. Не будет обновления статьи? или вообще статей по DevOps?
Не знаю, пока планов по обновлению нет. Да и в целом сайтом нет желания заниматься системно. Рекламу все блокируют, дохода с сайта мало, времени уходит много. Я всю активность перенёс в Telegram канал.
Ошибка после запуска ansible-playbook
Error from server (NotFound): configmaps \"kube-proxy\" not found
---
- server: https://127.0.0.1:6443
+ server: https://localhost:6443
name: cluster.local
contexts:
- context:
changed: [kub-node-1]
ok: [kub-ingress-1]
Tuesday 08 February 2022 12:23:54 +0300 (0:03:46.268) 20:33:26.578 *****
TASK [kubernetes/kubeadm : Update server field in kube-proxy kubeconfig] ****************************************************************************************************
fatal: [kub-master-1 -> kub-master-1]: FAILED! => {"changed": true, "cmd": "set -o pipefail && /usr/local/bin/kubectl --kubeconfig /etc/kubernetes/admin.conf get configmap kube-proxy -n kube-system -o yaml | sed 's#server:.*#server: https://127.0.0.1:6443#g' | /usr/local/bin/kubectl --kubeconfig /etc/kubernetes/admin.conf replace -f -", "delta": "0:00:00.349701", "end": "2022-02-08 12:24:40.590762", "msg": "non-zero return code", "rc": 1, "start": "2022-02-08 12:24:40.241061", "stderr": "Error from server (NotFound): configmaps \"kube-proxy\" not found", "stderr_lines": ["Error from server (NotFound): configmaps \"kube-proxy\" not found"], "stdout": "", "stdout_lines": []}
В конфигах другой ip адрес , не 127.0.0.1
prometheus
а не prometeus
~/kubespray/inventory/dev/group_vars/k8s-cluster/k8s-cluster.yml
опечатка. Должно быть
~/kubespray/inventory/dev/group_vars/k8s_cluster/k8s-cluster.yml
Спасибо за мануал.
Возникли проблемы с pip на чистой ос Centos7
pip install --upgrade pip
Cache entry deserialization failed, entry ignored
Collecting pip
Using cached https://files.pythonhosted.org/packages/88/d9/761f0b1e0551a3559afe4d34bd9bf68fc8de3292363b3775dda39b62ce84/pip-22.0.3.tar.gz
Complete output from command python setup.py egg_info:
Traceback (most recent call last):
File "", line 1, in
File "/tmp/pip-build-dmhhzc/pip/setup.py", line 7
def read(rel_path: str) -> str:
^
SyntaxError: invalid syntax
----------------------------------------
Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-dmhhzc/pip/
You are using pip version 8.1.2, however version 22.0.3 is available.
You should consider upgrading via the 'pip install --upgrade pip' command.
-------
Решилась проблема обновление до Python 3
https://serveradmin.ru/ustanovka-python-3-na-centos-7/
По умолчанию Python 2.7 был установлен.
Добрый день!
Спасибо за отличную статью - четко, понятно, доходчиво! )
Есть одна проблема с использованием kubrspray.
По умолчанию на мастер нодах он генерит kube-apiserver.yaml с параметром
spec:
containers:
- command:
- kube-apiserver
***
- --enable-admission-plugins=NodeRestriction
***
Теперь возникла необходимость добавить поддержку NodeSelector.
Если я руками поправлю эту переменную на мастерах и приведу к виду:
- --enable-admission-plugins=NodeRestriction,PodNodeSelector
то всё отлично - параметр применяется и работает.
Но!
Я никак не могу заставить kubespray менять этот параметр через ansible-playbook.
Согласно документации надо указать значение переменной:
kube_apiserver_enable_admission_plugins:
- PodNodeSelector
В каком виде и где надо указывать этот параметр?
Многократно пытался, но изменения не применяются.
Я прописал в трех файлах:
inventory/my_cluster/group_vars/etcd.yml
inventory/my_cluster/group_vars/all/all.yml
inventory/fceki_prod_cluster/group_vars/k8s_cluster/k8s_cluster.yml
строку в виде:
kube_apiserver_enable_admission_plugins: NodeRestriction,PodNodeSelector
даже дополнительно - напрямую указал значение переменной в командной строке при запуске:
ansible-playbook -i inventory/my_cluster/inventory.ini --become --become-user=root cluster.yml -e "enable-admission-plugins=NodeRestriction,PodNodeSelector"
но никак это значение на мастер нодах не меняется... файлы kube-apiserver.yaml не затрагиваются.
Подскажите пожалуйста - как заставить kubespray применить эту переменную для всех мастер нод?
Спасибо!
Сегодня узнал про kubespray из этой статьи, до этого обычно руками, и это был сущий ад.
Спасибо за простые и детальные шаги,
Но не хватает блока решения типичных ошибок,
Некторые проблемы, которые сегодня встретил (конфигурация как в статьи, только ip другие, ну и делал виртуалки в KVM + на рейде из 4х HDDx4TB потому таки лучше быстрый винт, а в идеале - отдельная машина, пусть и с hdd):
- устанавливал на centos 8.3, двум мастер-нодам сделал апдейт пакетов, они получали ошибки и конфликты при установке кластера, в основном `runc`, `conteinerd.io` и тп связанное с докером или с контейнеризацией (не сохранил лог)
- переустановил на нодах ОС, выбрал centos 8.5, пакеты и тп. не апгрейдил, оставил как есть
- выключил свап и SELinux
- начался процесс.. получил ошибки etcd: no route to host, health check for peer , и т.п.
- - свап остался выключенным, SELinux включился в permissive, вырубил, + вырубил фаирвол: systemctl stop firewalld.service;systemctl disable firewalld.service;iptables -F;iptables-save
- рестартнул ansible-playbook и спустя минут 15ть таки увидел заветное:
k8s-ingress-1 : ok=322 changed=33 unreachable=0 failed=0 skipped=622 rescued=0 ignored=0
k8s-master-1 : ok=497 changed=61 unreachable=0 failed=0 skipped=1109 rescued=0 ignored=1
k8s-master-2 : ok=433 changed=47 unreachable=0 failed=0 skipped=975 rescued=0 ignored=0
k8s-master-3 : ok=435 changed=48 unreachable=0 failed=0 skipped=973 rescued=0 ignored=0
k8s-node-1 : ok=320 changed=33 unreachable=0 failed=0 skipped=626 rescued=0 ignored=0
k8s-node-2 : ok=320 changed=33 unreachable=0 failed=0 skipped=624 rescued=0 ignored=0
localhost : ok=4 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
Всё не учтешь в статье, тем более про Kubernetes. Это большая и сложная система. Удивительно, что у вас по статье получилось разобраться с первого раза. Она написана пару лет назад и многое уже устарело. Я сам её давно не проверял. У Centos 8 есть проблемы с установкой обычного докера как раз из-за проблем с зависимостями conteinerd.io. Они то появляются, то исчезают. Я даже не слежу. Обычно для Docker ставлю Ubuntu. Там таких проблем нет.
Парни, не было ни у кого проблемы следующего рода:
worker ноды почему-то роль ingress принимают после развертывания, ранее такого у меня не было, так как эту роль не ставил. В принципе не страшно, кластер тестовый, но все равно непорядок))
Делаю все строго по ману Zerox + видос Слерма просмотрел по развертыванию кластера, там все идентично что и у Zerox.
Мой файл инвенторя:
[kube_control_plane]
masterkub
[kube_master]
masterkub
[etcd]
masterkub
[kube_node]
node1kub
node2kub
ingresskub
[kube_ingress]
ingresskub
[k8s_cluster:children]
kube_master
kube_node
kube-ingress.yml:
node_labels:
node-role.kubernetes.io/ingress: "true"
node_taints:
- "node-role.kubernetes.io/ingress=:NoSchedule"
addons.yml: поменял все, что описано в мане выше.
Все файлы перепроверил много раз.
Все круто, но не могу понять одного, зачем ingress ставим на отдельную машину, он же через kubespray ставится на каждую ноду как DaemonSet. Это же надежнее. Или я что то не правильно понимаю?
Это на случай, если нагрузка будет значительная. Выделяем отдельную ноду только под ingress. Но так делать необязательно. Ingress можно где угодно поднять.
КАКИЕ НАФИГ КУРСЫ
ЭТО ДРЯНЬ ПРОСТАЯ КАК БРЕВНО, - НО В НЕЙ НЕТУ НИКАКОГО СМЫСЛА.
Приветствую.
Такая же ошибка - при выполнении команды ansible-playbook -u root -k -i inventory/dev/inventory.ini -b --diff cluster.yml ошибка, что не найден cluster.yml , подскажите как исправить?
Обнаружил, что данная ошибка возникает, если запускать плейбук из папки отличающейся от ~/kubespray
Это же очевидно, в команде указан файл cluster.yml, который лежит в папке ~/kubespray. Если запускаете из другого места, то путь нужно полный указывать ~/kubespray/cluster.yaml.
Судя по трем одинаковым вопросам - не очевидно. Вероятно, при предлагаемой последовательности действий оператор перемещается в другой каталог а при запуске плейбука не предлагается вернуться в исходную папку. Так что формально - ошибка в алгоритме (описании последовательности действий).
Kubernetes не освоить по готовым алгоритмам. Нужно понимать, что ты делаешь. Разбираться, а не бездумно копировать команды.
ERROR! the playbook: cluster.yml could not be found
вот такая ошибка при попытке установить кластер
Добрый день.
На команду ansible-playbook -u root -k -i inventory/dev/inventory.ini -b --diff cluster.yml выдаёт ошибку -bash: ansible-playbook: command not found
Подскажите, как её решить?
Ansible может не стоит? Странно, вы пытаетесь поставить кластер Kubernetes, но при этом спрашиваете, что делать, когда в командной строке получаете ошибку на тему того, что бинарник не найден. Что вы с кластером делать хотите? Там возникнут посложнее вопросы.
Всё делалось по инструкции, как в статье, ни ошибок, ни пропущенных команд не было
Установите ansible вручную через yum:
# yum install ansible
Возможно через pip ansible-palybook не установился, либо в какой-то нестандартный путь попал.
Добрый день! Подскажите что не так с сертификатами? В самом конце выполнение playbook'a выдает ошибку следующего содержания:
fatal: [master]: FAILED! => {"msg": "The conditional check '(not etcd_member_certs.results[0].stat.exists|default(false)) or (not etcd_member_certs.results[1].stat.exists|default(false)) or (not etcd_member_certs.results[2].stat.exists|default(false)) or (not etcd_member_certs.results[3].stat.exists|default(false)) or (not etcd_member_certs.results[4].stat.exists|default(false)) or (etcd_member_certs.results[0].stat.checksum|default('') != etcdcert_master.files|selectattr(\"path\", \"equalto\", etcd_member_certs.results[0].stat.path)|map(attribute=\"checksum\")|first|default('')) or (etcd_member_certs.results[1].stat.checksum|default('') != etcdcert_master.files|selectattr(\"path\", \"equalto\", etcd_member_certs.results[1].stat.path)|map(attribute=\"checksum\")|first|default('')) or (etcd_member_certs.results[2].stat.checksum|default('') != etcdcert_master.files|selectattr(\"path\", \"equalto\", etcd_member_certs.results[2].stat.path)|map(attribute=\"checksum\")|first|default('')) or (etcd_member_certs.results[3].stat.checksum|default('') != etcdcert_master.files|selectattr(\"path\", \"equalto\", etcd_member_certs.results[3].stat.path)|map(attribute=\"checksum\")|first|default('')) or (etcd_member_certs.results[4].stat.checksum|default('') != etcdcert_master.files|selectattr(\"path\", \"equalto\", etcd_member_certs.results[4].stat.path)|map(attribute=\"checksum\")|first|default(''))' failed. The error was: no test named 'equalto'\n\nThe error appears to be in '/root/kubespray/roles/etcd/tasks/check_certs.yml': line 108, column 3, but may\nbe elsewhere in the file depending on the exact syntax problem.\n\nThe offending line appears to be:\n\n\n- name: \"Check_certs | Set 'etcd_member_requires_sync' to true if ca or member/admin cert and key don't exist on etcd member or checksum doesn't match\"\n ^ here\nWe could be wrong, but this one looks like it might be an issue with\nunbalanced quotes. If starting a value with a quote, make sure the\nline ends with the same set of quotes. For instance this arbitrary\nexample:\n\n foo: \"bad\" \"wolf\"\n\nCould be written as:\n\n foo: '\"bad\" \"wolf\"'\n"}
Я пробовал удалять папку ssl в директории /etc/ssl/etcd/, пересоздавал сертификаты ни чего не помогло, ошибка как была так и осталась. Centos7.
ПАГАГИТЕ разобраться.
Всем привет. А на других нодах должны команды запускаться или только на Master?
Для установки кластера только на Master. Да и потом на ноды нет нужды ходить руками.
Просто залил контейнер с апач. Он появился не другой ноде. Делаю port-forward, а страница не открывается в браузере. При этом на самой ноде при выполнении kubectl get nodes получаю следующее:
The connection to the server localhost:8080 was refused - did you specify the right host or port?
Апач на той ноде без кубернетеса работает нормально.
На какой ноде вы делаете запрос kubectl get nodes? После установки кластера через kubespray, подобные запросы к кластеру можно делать только с мастера, так как на нем лежат сертификаты, необходимые для подключения к кластеру. Их надо копировать на другие ноды, если вы хотите оттуда делать запросы кластеру. Но я лично не очень понимаю, зачем это может быть нужно.
Спасибо. Понял.
А можно уточнить, почему с физической машины, на которой запущены 3 виртуальных в VirtualBox я не могу открыть веб-страницу, хотя port-forward с master запустил? Физическая и виртуальные находятся в одной сети 192.168.1.1/24. По SSH они подключаются, пинги проходят.
Это я не знаю, надо разбираться. Про публикацию сервисов в кластере у меня есть отдельная статья в этом же разделе - https://serveradmin.ru/nastroyka-kubernetes
Коллеги, а можете показать кусок конфига для оперделения прокси? Не въезжаю в синтаксис.
Парни, а версию Kubernetes (а точнее kubeadm) которая будет установлена, можно задать? Просто мне нужно потестировать продукт с конкретной версией, которая у заказчика стоит.
Ну походу в файле kubeadm-version.yml
Кусочек файла:
- name: sets kubeadm api version to v1beta2
set_fact:
kubeadmConfig_api_version: v1beta2
when: kubeadm_output.stdout is version('v1.15.0', '>=')
Полагаю, в моем случае так:
when: kubeadm_output.stdout is version('v1.17.0', '=')
Для этого в k8s-cluster.yml есть параметр:
kube_version: v1.19.3
Тут можно указать необходимую версию. Если не ошибаюсь, то текущий kubeadm позволяет откатиться назад на пару версий. Если надо еще старее, то необходимо на ветки с предыдущими версиями kubeadm переходить.
Могли бы Вы пояснить, почему разворачивать Zabbix в Docker контейнере не имеет смысл, с Вашей точки зрения.
Что Вы можете посоветовать для оркестровки Docker контейнерами, если не Kubernetes?
Что плохого в том, чтобы развернуть ряд сервисов(Zabbix, GPLI) под свои нужды или некоторые сайты организации в кластере? Хоть и не нужно обеспечивать CI\CD, но как способ обеспечения отказоустойчивости и мониторинга за всеми этими контейнерами.
Я прошу прощение, за уточнение!
1) Я тоже решил использовать flannel у меня подсеть 10.10.0.0/23, как мне задать ее? '10\\.10\\.0\\.\\d{1,3}' ? и что значит {1,3}?
2) В файле inventory.ini все понятно с параметром ansible_host=, а вот для чего нужен параметр ip=?
Если я не ошибаюсь, то d{1,3} означает любое одно, двух или трехзначное число. То есть любое число от 1 до 999.
\d{1,3}
Это две любые цифры от 0 до 9 подряд
Есть хороший сервис наглядно расшифровывает регулярки
https://regexper.com/#%5Cd%7B1%2C3%7D
Нет, не верно. Это числа от 0 до 999. То есть не меньше 1 цифры от 0 до 9, а максимум - 3.
ДД! Получаю такую ошибку почти под конец, что это может быть ?
TASK [download : prep_kubeadm_images | Copy kubeadm binary from download dir to system path] ******************************************************************
fatal: [kub-master-2 -> 192.168.50.16]: FAILED! => {"changed": false, "cmd": "sshpass", "msg": "[Errno 2] No such file or directory", "rc": 2}
fatal: [kub-master-3 -> 192.168.50.17]: FAILED! => {"changed": false, "cmd": "sshpass", "msg": "[Errno 2] No such file or directory", "rc": 2}
fatal: [kub-master-1 -> 192.168.50.15]: FAILED! => {"changed": false, "cmd": "sshpass", "msg": "[Errno 2] No such file or directory", "rc": 2}
sshpass может не стоит на хостах?
Спасибо , верно .Установил sshpass
Спасибо за статьи(не только кубер).
Просмотр всех сертов:
kubeadm alpha certs check-expiration
Обновление всех сертов:
kubeadm alpha certs renew all
Полагаю, что можно как LetsEncrypt просто добавляют в крон тут сделать аналогично и забыть о проблеме. Но делать это на каждой ноде? Пока тоже лучше решения не нашел :)
При указании 2х нод в группе etcd получаем ругань:
fatal: [k8s-master01]: FAILED! => {
"assertion": "groups.etcd|length is not divisibleby 2",
"changed": false,
"evaluated_to": false,
"msg": "Assertion failed"
}
...
Причина в проверке перед созданием кластера. Счет ведется как localhost + указанные ноды.
В инете основных совета 3:
1) Оставить 1 ноду для etcd в inventory
2) редактировать ./roles/kubernetes/preinstall/tasks/0020-verify-settings.yml
- name: Stop if even number of etcd hosts
assert:
that: groups.etcd|length is not divisibleby 2
2 заменить на "цифру" = ваше количество нод в inventory +1 (localhost)
3) добавить флаг -e ignore_assert_errors=yes.
Так себе решение помоему.
Может кому поможет. Тестил 1) и 2)
Спасибо.
Я говорю спасибо тебе, сэй.
Пункт 2 помог.
Добрый вечер. Есть вопрос. Например в файле inventory.ini для ingress ноды, если у моей ноды будет еще один ip внешний скажем 1.2.3.4 и внутренний 10.1.4.39 Как сделать так чтобы все вешалось на внешний ip чтобы с него были доступны все сервисы ингресса? Если она торчит во внутреннюю и во внешнюю сеть что куда прописывать?
kub-master-1 ansible_host=10.1.4.36 ip=10.1.4.36
kub-master-2 ansible_host=10.1.4.37 ip=10.1.4.37
kub-master-3 ansible_host=10.1.4.38 ip=10.1.4.38
kub-ingress-1 ansible_host=10.1.4.39 ip=10.1.4.39
kub-node-1 ansible_host=10.1.4.32 ip=10.1.4.32
kub-node-2 ansible_host=10.1.4.33 ip=10.1.4.33
[kube-master]
kub-master-1
kub-master-2
kub-master-3
[etcd]
kub-master-1
kub-master-2
kub-master-3
[kube-node]
kub-node-1
kub-node-2
kub-ingress-1
[kube-ingress]
kub-ingress-1
[k8s-cluster:children]
kube-master
kube-node
Если речь идет об установке кубера, то в любом случае надо указывать внутренний ip адрес. Внешний ip адрес нужно будет указывать позже, при настройке ingress.
Владимир, спасибо вам за то, что вы делаете!
Добрый день!
Столкнулся с такой проблемой. Интересно то, что эта ошибка у меня появилась после того как я решил пересобрать уже работающий кластер. То есть до этого момента я сделал OVF трех виртуалок, потом их задеплоил и поменял айпишки. В плейбуке я тоже сделал необходимые манипуляции. В чем может быть причина?
fatal: [kub-master-1]: FAILED! => {"attempts": 4, "changed": false, "cmd": "/usr/local/bin/etcdctl endpoint --cluster status && /usr/local/bin/etcdctl endpoint --cluster health 2>&1 | grep -q -v 'Error: unhealthy cluster'", "delta": "0:00:05.019701", "end": "2020-09-18 14:09:19.071324", "msg": "non-zero return code", "rc": 1, "start": "2020-09-18 14:09:14.051623", "stderr": "{\"level\":\"warn\",\"ts\":\"2020-09-18T14:09:19.069+0300\",\"caller\":\"clientv3/retry_interceptor.go:61\",\"msg\":\"retrying of unary invoker failed\",\"target\":\"endpoint://client-41f36a72-b68a-45bd-936b-50076596f740/172.18.141.1:2379\",\"attempt\":0,\"error\":\"rpc error: code = DeadlineExceeded desc = latest connection error: connection error: desc = \\\"transport: Error while dialing dial tcp 172.18.141.1:2379: connect: connection refused\\\"\"}\nError: failed to fetch endpoints from etcd cluster member list: context deadline exceeded", "stderr_lines": ["{\"level\":\"warn\",\"ts\":\"2020-09-18T14:09:19.069+0300\",\"caller\":\"clientv3/retry_interceptor.go:61\",\"msg\":\"retrying of unary invoker failed\",\"target\":\"endpoint://client-41f36a72-b68a-45bd-936b-50076596f740/172.18.141.1:2379\",\"attempt\":0,\"error\":\"rpc error: code = DeadlineExceeded desc = latest connection error: connection error: desc = \\\"transport: Error while dialing dial tcp 172.18.141.1:2379: connect: connection refused\\\"\"}", "Error: failed to fetch endpoints from etcd cluster member list: context deadline exceeded"], "stdout": "", "stdout_lines": []}
У вас четко видно, что проблема сетевая: "Error while dialing dial tcp 172.18.141.1:2379: connect: connection refused"
Нет подключения по указанному адресу и порту. Разбирайтесь с сетью. Либо с тем, что на порту tcp 2379 никто не отвечает.
Может кому пригодится:
для сети 192.168.123.xxx/27 регулярка сработала такая: flannel_interface_regexp: '192\\.168\\.123\\.\\d{1,2}'
на все сервера устанавливал sshpass
'192\\.168\\.123\\.\\d{1,3}' то же бы подошло. В данном случае это количество символов. При {1,2} максимальный адрес был бы 192.168.123.99, то есть два символа в конце.
Добрый день! Спасибо за интересную статью. Всё поднялось, работает. Уже запустил для теста несколько подов. Супер!)
Вопрос мой такого характера. Если мне нужно будет добавить еще одну worker node, мне просто нужно будет по этому шаблону так же настроить ее до момента подброса, установить необходимые компоненты и поправить на мастере inventory.ini и перезапустить плейбук или есть более элегантное решение?
Я уже немного подзабыл, но вроде бы, чтобы добавить ноду, вам надо просто добавить в инвентори ее в дополнение к существующим и запустить плейбук еще раз по всем нодам. Так что рекомендуется клонировать к себе репозиторий с установкой и держать у себя локально, чтобы можно было без проблем управлять именно своей версией кластера.
Инструкция до сих пор актуальна? По ней все получилось запустить?
инструкция актуальна. Местами нужно просто на ноды где-то что-то добавить, но это пустяки. В ошибках при деплое всё подробно написано. Так что кто будет пробовать ставить- ваш туториал очень здорово всё описывает. Спасибо!)
Добрый день! Подскажите. Запускаю плейбук, доходит до конца и валится с ошибкой такого рода и не поднимается первый мастер. Кто-нибудь сталкивался?
FAILED - RETRYING: Configure | Wait for etcd cluster to be healthy (4 retries left).
FAILED - RETRYING: Configure | Wait for etcd cluster to be healthy (3 retries left).
FAILED - RETRYING: Configure | Wait for etcd cluster to be healthy (2 retries left).
FAILED - RETRYING: Configure | Wait for etcd cluster to be healthy (1 retries left).
TASK [etcd : Configure | Wait for etcd cluster to be healthy] **********************************************************fatal: [kub-master-1]: FAILED! => {"attempts": 4, "changed": false, "cmd": "/usr/local/bin/etcdctl endpoint --cluster status && /usr/local/bin/etcdctl endpoint --cluster health 2>&1 | grep -q -v 'Error: unhealthy cluster'", "delta": "0:00:05.020026", "end": "2020-08-03 12:06:09.933587", "msg": "non-zero return code", "rc": 1, "start": "2020-08-03 12:06:04.913561", "stderr": "{\"level\":\"warn\",\"ts\":\"2020-08-03T12:06:09.932+0300\",\"caller\":\"clientv3/retry_interceptor.go:61\",\"msg\":\"retrying of unary invoker failed\",\"target\":\"endpoint://client-56aec222-a9c5-4fea-941d-819295ff9221/172.24.178.1:2379\",\"attempt\":0,\"error\":\"rpc error: code = DeadlineExceeded desc = latest connection error: connection error: desc = \\\"transport: Error while dialing dial tcp 172.24.178.3:2379: connect: no route to host\\\"\"}\nError: failed to fetch endpoints from etcd cluster member list: context deadline exceeded", "stderr_lines": ["{\"level\":\"warn\",\"ts\":\"2020-08-03T12:06:09.932+0300\",\"caller\":\"clientv3/retry_interceptor.go:61\",\"msg\":\"retrying of unary invoker failed\",\"target\":\"endpoint://client-56aec222-a9c5-4fea-941d-819295ff9221/172.24.178.1:2379\",\"attempt\":0,\"error\":\"rpc error: code = DeadlineExceeded desc = latest connection error: connection error: desc = \\\"transport: Error while dialing dial tcp 172.24.178.3:2379: connect: no route to host\\\"\"}", "Error: failed to fetch endpoints from etcd cluster member list: context deadline exceeded"], "stdout": "", "stdout_lines": []}
NO MORE HOSTS LEFT *****************************************************************************************************
PLAY RECAP *************************************************************************************************************kub-ingress-1 : ok=248 changed=2 unreachable=0 failed=0 skipped=296 rescued=0 ignored=0
kub-master-1 : ok=356 changed=5 unreachable=0 failed=1 skipped=406 rescued=0 ignored=0
kub-master-2 : ok=331 changed=5 unreachable=0 failed=0 skipped=353 rescued=0 ignored=0
kub-master-3 : ok=331 changed=5 unreachable=0 failed=0 skipped=353 rescued=0 ignored=0
kub-node-1 : ok=248 changed=2 unreachable=0 failed=0 skipped=298 rescued=0 ignored=0
kub-node-2 : ok=248 changed=2 unreachable=0 failed=0 skipped=296 rescued=0 ignored=0
localhost : ok=1 changed=0 unreachable=0 failed=0 skipped=0 rescued=0 ignored=0
Надо идти на мастер и смотреть, что с ним. Судя по ошибке, какие-то проблемы со связью, либо etcd не поднимается.
Error while dialing dial tcp 172.24.178.3:2379: connect: no route to host
Добрый день, удалось решить?
Здравствуйте, подскажите такой момент когда создали этот файл "Создаем файл ~/kubespray/inventory/dev/group_vars/kube-ingress.yml и добавляем параметры:" как kubespray понимает к каки хостам ее применить,не нашел связи
@Zerox
Добрый день. Наткнулся в инете на ваши статьи. Хорошее и доходчивое изложение материала. Всё получилось с первого раза вот только с ингрессом небольшие проблемы. Конроллер ингресса не разворачивается.
Попробуйте через helm чарт его развернуть.
есть несколько. есть сообшества и nginx. который из них посоветуете?
Не знаю, что лучше. У меня всегда получалось установить через Kubespray.
Для того чтобы многие не повторяли моих ошибок:
При установке CentOs разделы диска в EXT4, по умолчанию он использует XFS с параметром d_type = 0 - это критично для свежих версий докера! При запуске playbook будет ставиться свежая версия.
Если используете proxy:
В моём случае понадобилось в environment указывать еще и no_proxy=192.168.x.x,127.0.0.1,localhost,192.x.0.0/x в таком духе продублировал настройки командой export.
В файле cluster.yml везде где упоминается о proxy выставил такие настройки: proxy=http://proxy.domain.com:3128 + я не знаю как это работает с авторизацией, я поднял дополнительный прокси без авторизации, а сам он ходит на корпоративный с авторизацией (цепочка прокси).
Вот так, осталось порешать вот эту ошибку (она на всех нодах одна):
fatal: [kub-master-1 -> 192.168.x.x]: FAILED! => {"attempts": 4, "changed": true, "cmd": ["/usr/bin/docker", "pull", "k8s.gcr.io/k8s-dns-node-cache:1.15.10"], "delta": "0:00:15.099489", "end": "2020-04-15 10:32:51.182714", "msg": "non-zero return code", "rc": 1, "start": "2020-04-15 10:32:36.083225", "stderr": "Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)", "stderr_lines": ["Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)"], "stdout": "", "stdout_lines": []}
Эту проблему тоже порешал, не удивительно, что все оказалось просто - установленному докеру нужно было настроить proxy (на всех нодах) и перезапустить плейбук:
cat > /etc/systemd/system/docker.service.d/http-proxy.conf < {"attempts": 4, "changed": false, "cmd": "/usr/local/bin/etcdctl --no-sync --endpoints=https://192.168.х.х:2379 cluster-health | grep -q 'cluster is healthy'", "delta": "0:00:00.062629", "end": "2020-04-15 11:53:40.451823", "msg": "non-zero return code", "rc": 1, "start": "2020-04-15 11:53:40.389194", "stderr": "Error: client: etcd cluster is unavailable or misconfigured; error #0: Forbidden\n\nerror #0: Forbidden", "stderr_lines": ["Error: client: etcd cluster is unavailable or misconfigured; error #0: Forbidden", "", "error #0: Forbidden"], "stdout": "", "stdout_lines": []}
Решил вышестоящую проблему тем, что во первых хост мастера (я думаю этого достаточно) добавил в no_proxy в /etc/environment, не забывайте делать source /etc/environment, а также на всякий, все остальные ноды. Можно продублировать при помощи export (export no_proxy=192.ваши настройки - все это выполнить просто в консольной среде).
Но далее вылезла такая ошибка: {"changed": false, "cmd": "sshpass", "msg": "[Errno 2] No such file or directory", "rc": 2} (она касалась всех нод за исключением мастера): ставим на всех нодах (на мастере не стоит, если на нем нет этой ошибки) yum install sshpass, ну и по классике перезапускаем ansible-playbook -u root -k -i inventory/dev/inventory.ini -b --diff cluster.yml
Жду офигительных историй которые мне сейчас выплюнет ansible
Жесть какая-то. Мне кажется, все это будет глючить при работе через прокси. Для прода не годится. Я бы руками кластер настраивал в вашем случае.
Парни, еще вопрос (возможно глупый), Flannel предварительно разворачивать на всех нодах кластре, включая мастер? Ну в моем случае, у меня 4ре ноды, 2ве воркс, один мастер, одна с воркс+ingress, ставить на все? И второй вопрос, Flannel просто ставлю, больше ни как не конфигурирую, сразу перехожу к действиям которые в статье?
Предварительно ничего ставить не надо. Flannel ставится этим же плейбуком вместе с остальным кластером. В статье все рассказано, вся последовательность.
Парни, кто подскажет? У меня все начинается за здравие, а стопориться на это (уже после запуска ansible-playbook -u root -k -i inventory/dev/inventory.ini -b --diff cluster.yml):
Выполняется таск:
TASK [kubernetes/preinstall : Update common_required_pkgs with ipvsadm when kube_proxy_m ode is ipvs] ***
ok: [kub-master-1]
Friday 10 April 2020 11:23:34 +0300 (0:00:00.635) 0:01:56.899 **********
А затем:
FAILD - RETRYING: install packages requirements (4 retries left).
На этом все виснет....
По плейбу мне не ясно что в этот момент происходит.
У четыре тачки виртуальные centos 7, 1н мастер, две чисто ворк ноды и 1на ingress с бриджами, тачки друг-друга видят.
Еще тонкий момент приходится ходить через proxy (без авторизации), я настроил прокси для wget, yum, environment, git тоже в итоге удалось пустить через проксю на мастере, и запускал установку через pip тоже передавая в этой команде настройки proxy. - я подозреваю, что затыка может быть в том, что есть еще пакеты для которых нужно прокси настраивать. Мимо прокси к сожалению пустить ни чего не смогу((( от меня это не зависит.
И да, прокси настроен на всех тачках.
Ansible когда валится с ошибкой, показывает ее текст полностью. Надо внимательно смотреть вывод плейбука. Ошибки там обычно видны достаточно четко. По тексту видно, что не получается поставить какие-то пакеты.
Возможно будет проще настроить какой-то шлюз для всего кластера, который сам будет ходить в инет через прокси, а всех остальных пускать напрямую. На первый взгляд это не кажется простой задачей, но тем не менее, это надежнее будет, чем для всех настраивать прокси. Где-то ошибки все равно вылезать будут.
Zerox
Хм.. Возможно, вы правы! Да нет, думаю сложного тут точно ничего нет, сейчас статей как тот-же ubuntu настроить в качестве шлюза пруд пруди.
Спасибо за идею!
После выполнения команды ansible-playbook -u root -k -i inventory/dev/inventory.ini -b --diff cluster.yml я заметил что ansible удаляет настройки прокси в файле /etc/yum.conf, точнее, если смотреть лог после выполнения плейбука, то она пытается подставить откуда-то настройки proxy, а вот откуда непонятно:
bootstrap-os : Gather host facts to get ansible_os_family --------------- 1.52s
Проблема скорее в этом
Увидел настройки прокси в самом плейбуке:
- hosts: all
gather_facts: false
tasks:
- name: "Set up proxy environment"
set_fact:
proxy_env:
http_proxy: "{{ http_proxy | default ('') }}"
HTTP_PROXY: "{{ http_proxy | default ('') }}"
https_proxy: "{{ https_proxy | default ('') }}"
HTTPS_PROXY: "{{ https_proxy | default ('') }}"
no_proxy: "{{ no_proxy | default ('') }}"
NO_PROXY: "{{ no_proxy | default ('') }}"
Собственно там и передал правильное значение proxy формата: proxy=http://proxy.domain.ru:3128 Помогло!!!))))))))
Теперь только 1 ошибку осталось решить, сервис докера не на одной тачке не стартует.
С докером тоже интересная тема, если тщательно изучить журнал journalctl -xe, то ошибка запуска службы упирается в это:
14:53:22 kub-master-1 dockerd[14507]: Error starting daemon: error initializing graphdriver: overlay2: the backing xfs filesystem is formatted without d_type support, which leads to incorrect behavior. Reformat the filesystem with
апр 13 14:53:22 kub-master-1 systemd[1]: docker.service: main process exited, code=exited, status=1/FAILURE
14:53:22 kub-master-1 dockerd [14507]: Ошибка запуска демона: ошибка инициализации graphdriver: overlay2: файловая система поддержки xfs отформатирована без поддержки d_type, что приводит к некорректному поведению. Переформатировать файловую систему с
13 апреля 14:53:22 kub-master-1 systemd [1]: docker.service: основной процесс завершен, код = завершен, статус = 1 / НЕИСПРАВНОСТЬ
)))) Вот так вот (Александр Курицын)
Такая ошибка только в старых версиях CentOs, простого пути обойти эту проблему нет((((((((((( Остается только такое решение:
У вас есть два варианта: либо добавить новый диск и создать на нем новый раздел XFS, либо создать резервную копию существующих данных и заново создать файловую систему XFS с включенной поддержкой d_type. Создать новую файловую систему XFS с включенным d_type так же просто с помощью следующей команды:
$ mkfs.xfs -n ftype=1 /mount-point
К сожалению, невозможно включить поддержку d_type в существующей файловой системе.
Для того чтобы многие не повторяли моих ошибок:
При установке CentOs разделы диска в EXT4, по умолчанию он использует XFS с параметром d_type = 0 - это критично для свежих версий докера! При запуске playbook будет ставиться свежая версия.
Если используете proxy:
В моём случае понадобилось в environment указывать еще и no_proxy=192.168.x.x,127.0.0.1,localhost,192.x.0.0/x в таком духе продублировал настройки командой export.
В файле cluster.yml везде где упоминается о proxy выставил такие настройки: proxy=http://proxy.domain.com:3128 + я не знаю как это работает с авторизацией, я поднял дополнительный прокси без авторизации, а сам он ходит на корпоративный с авторизацией (цепочка прокси).
Вот так, осталось порешать вот эту ошибку (она на всех нодах одна):
fatal: [kub-master-1 -> 192.168.x.x]: FAILED! => {"attempts": 4, "changed": true, "cmd": ["/usr/bin/docker", "pull", "k8s.gcr.io/k8s-dns-node-cache:1.15.10"], "delta": "0:00:15.099489", "end": "2020-04-15 10:32:51.182714", "msg": "non-zero return code", "rc": 1, "start": "2020-04-15 10:32:36.083225", "stderr": "Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)", "stderr_lines": ["Error response from daemon: Get https://k8s.gcr.io/v2/: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)"], "stdout": "", "stdout_lines": []}
Добрый день. Кластер установился и поднялся. Добавил сисьемного пользователя для доступа к дашбоард по инструкции. Но токен не проходит. Не сталкивались ?
К какому дашборду, не понял. Их много разных.
Привет, у тебя версия дашборда и кубера несовместимы.
kubespray разворачивает старую версию морды, поэтому удаляй, устанавливай новую, создавай пользователя и вытаскивай его токен
Выглядит примерно так (на мастере):
kubectl delete deployments kubernetes-dashboard -n kube-system
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-rc2/aio/deploy/recommended.yaml
kubectl create serviceaccount k8sadmin -n kube-system
kubectl create clusterrolebinding k8sadmin --clusterrole=cluster-admin --serviceaccount=kube-system:k8sadmin
kubectl get secret -n kube-system | grep k8sadmin | cut -d " " -f1 | xargs -n 1 | xargs kubectl get secret -o 'jsonpath={.data.token}' -n kube-system | base64 --decode
К моему посту выше нужно длинные черты заменить на два прочерка
Спасибо помогло
Привет! статья очень полезная!
у меня такая проблемка:
[root@master1 ~]# ansible-playbook -u root -k -i /root/kubespray/inventory/dev/inventory -b --diff cluster.yml
ERROR! the playbook: cluster.yml could not be found
Друг, если ты самостоятельно не можешь решить эту проблему, тебе нет смысла настраивать кластер. Без обид.
Тут просто написано, что файл cluster.yml не найден. Найди его.
На второй день выяснилось, что токен валиден только сутки, и если возникла необходимость добавить ноду по истечении этого времени, то токен надо перевыпустить
на мастере
# kubeadm token create
zfvcf0.domneur62fwy33mx
Не уверен, что следующие две команды нужны, т.к. у меня вывод совпал с первоначальным, но в мануале они были
# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
zfvcf0.domneur62fwy33mx 23h 2019-11-08T17:17:44+09:00 authentication,signing system:bootstrappers:kubeadm:default-node-token
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
5340ec383b25e0c52736970727c4a6f4c8b4ace09c023e1e9e9d26eb037fa9fe
Обратите внимание, что апостроф в sed должен быть прямым.
на новой ноде
# kubeadm reset
# kubeadm join 95.216.223.21:6443 --token zfvcf0.domneur62fwy33mx --discovery-token-ca-cert-hash sha256:5340ec383b25e0c52736970727c4a6f4c8b4ace09c023e1e9e9d26eb037fa9fe
Не забываем подставлять свой IP
Нужно запускать из папки kubespray.
подскажите пожалуйста - в чем может быть причина проблемы с подключением к кластеру:
kub-master-2:~$ kubectl get nodes
The connection to the server localhost:8080 was refused - did you specify the right host or port?
порт 8080 не слушает ни одно из приложений ни на одном из мастеров :(
повторная установка проходит без ошибок (ОС Ubuntu 18.04)
PLAY RECAP ***********************************************************************************************************
kub-ingress-1 : ok=359 changed=18 unreachable=0 failed=0
kub-master-1 : ok=527 changed=35 unreachable=0 failed=0
kub-master-2 : ok=486 changed=33 unreachable=0 failed=0
kub-master-3 : ok=488 changed=33 unreachable=0 failed=0
kub-node-1 : ok=389 changed=21 unreachable=0 failed=0
kub-node-2 : ok=357 changed=18 unreachable=0 failed=0
localhost : ok=1 changed=0 unreachable=0 failed=0
Friday 31 January 2020 10:15:09 +0300 (0:00:00.488) 0:13:57.031 ********
===============================================================================
container-engine/docker : Docker | reload docker ------------------------------------------------------------- 31.32s
kubernetes/master : Master | wait for kube-scheduler --------------------------------------------------------- 22.32s
kubernetes/preinstall : Update package management cache (APT) ------------------------------------------------- 9.40s
kubernetes-apps/ansible : Kubernetes Apps | Start Resources --------------------------------------------------- 6.99s
download : download | Download files / images ----------------------------------------------------------------- 6.79s
kubernetes-apps/network_plugin/flannel : Flannel | Wait for flannel subnet.env file presence ------------------ 5.53s
download : download_container | Download image if required ---------------------------------------------------- 5.35s
kubernetes-apps/ansible : Kubernetes Apps | Lay Down CoreDNS Template ----------------------------------------- 5.14s
kubernetes-apps/cluster_roles : PriorityClass | Create k8s-cluster-critical ----------------------------------- 4.78s
container-engine/docker : ensure docker packages are installed ------------------------------------------------ 4.52s
download : download | Sync files / images from ansible host to nodes ------------------------------------------ 4.52s
kubernetes/preinstall : Hosts | populate inventory into hosts file -------------------------------------------- 4.25s
kubernetes/master : kubeadm | write out kubeadm certs --------------------------------------------------------- 3.99s
bootstrap-os : Fetch /etc/os-release -------------------------------------------------------------------------- 3.88s
download : download | Sync files / images from ansible host to nodes ------------------------------------------ 3.61s
kubernetes/master : Generate new kubeconfigs with correct apiserver ------------------------------------------- 3.56s
download : download | Sync files / images from ansible host to nodes ------------------------------------------ 3.43s
download : download_container | Download image if required ---------------------------------------------------- 3.35s
download : download | Download files / images ----------------------------------------------------------------- 3.23s
download : download | Sync files / images from ansible host to nodes ------------------------------------------ 3.21s
Так трудно сказать. Надо смотреть, что с докер контейнерами на хосте. Раз порт никто не слушает, значит они не запущены. Надо смотреть логи докера.
сам отвечу на свой вопрос:
ansible kub-master-* -m shell -a 'mkdir -pv ~/.kube/ && sudo cp /etc/kubernetes/admin.conf ~/.kube/config'
ansible kub-master-* -m shell -a 'sudo chown $(whoami) ~/.kube/config'
По какой-то причине конфиги не разошлись по кластеру в домашние директории рута. Кстати, не помню, должны ли они вообще это делать. Я обычно с первого мастера кластер смотрю, откуда и запускаю изначально установку. Но ты писал, что порт никто не слушает. Получается, порт активен, просто доступа не было.
Порт слушается теперь только secure - 6443. Ещё возникли странные глюки с токеном для доступа к дашбоарду...Могу как-нибудь описать мои действия...
Во время установки /
1.
Thursday 12 December 2019 12:14:28 +0000 (0:00:00.146) 0:00:00.146 *****
ok: [localhost] => {
"changed": false,
"msg": "All assertions passed"
}
[WARNING]: Could not match supplied host pattern, ignoring: bastion
2. На этом подвисает
TASK [bootstrap-os : Fetch /etc/os-release] **********************************************************************************************************************
Thursday 12 December 2019 12:14:30 +0000 (0:00:00.790) 0:00:02.803 *****
Спасибо за статью.
Небольшой апдэйт: в 16 релизе немного подтюнили метки и файл kube-ingress.yml должен выглядеть следующим образом:
node_labels:
node.kubernetes.io/ingress: "true"
node_taints:
- "node.kubernetes.io/ingress=:NoSchedule"
Ямл корректно не отобразился при публикации - отступы съелись...
Вместо node-role стало просто node?
да, kubelet ругался с node-role
Не уверен. Возможно у вас это был баг конкретной версии.
Ставил на 22 релизе в варианте:
node_labels:
node-role.kubernetes.io/ingress: "true"
node_taints:
- "node-role.kubernetes.io/ingress=:NoSchedule"
Все отработало штатно.
Если без -role, то роль не назначается, только метка и соот-но ингресс кубспреем не поднимается.
P.S. Вообще весь гайд практически один в один курс Slurm.io базовый :-) от 2019 года и его надо малость актуализировать :-)
"В данном случае 10\\.1\\.4\\.\\d{1,3} это регулярное выражение, которое описывает подсеть 10.1.4.0/24, в которой у меня размещены виртуальные машины под кластер. Если у вас подсеть машин для кластера, к примеру, 192.168.55.0, то регулярка будет 192\\.168\\.55\\.\\d{1,3}"
Как описать разные подсети, если предположим, что kub-master-1 находится в сети 172.30.172.0, а остальные хосты в 172.30.168.0?
Я не силен в регулярных выражениях. Плюс, не проверял на практике, как работает flannel в разных подсетях. Я бы попробовал так:
172\\.30\\.\\d{1,3}\\.\\d{1,3}
По идее, это должно подойти, если я правильно понял логику данного выражения. У меня самого даже для моего примера не получилось с первого раза правильно описать подсеть. Я просто не сразу понял это выражение - \\d{1,3}.
Про сертификаты - nagios-ом мониторю, остаётся 20 дней - матюгальников на почту. Всё, не продевается. Думаю, такое умеют и другие системы мониторинга.
С мониторингом нет вопросов, настроить не сложно. А как сертификаты обновляете? Там же целая процедура, не оставляющая права на ошибку.
Возможно это поможет:
https://github.com/kubernetes-sigs/kubespray/issues/5464#issuecomment-647022647
Спасибо за статью, после прочтения остался вопрос: Nginx Ingress Controller привязывается к конкретной ноде kub-ingress-1. Чем это обусловленно? Ведь получается, если упадет нода kub-ingress-1 - кластер превратиться в тыкву или подразумевается, что гипервизор нод обеспечивает HA и мы не рассматриваем варианта падения ноды?
Это тестовая установка для демонстрации возможностей. Как я понимаю, в проде ingress обычно бывает 2 и более ноды. По крайней мере я видел это. Можно ingress вешать дополнительно на рабочую ноду, но я не разбирался, как там распределяется нагрузка и можно ли остальные ingress пометить как запасные, и как всем этим управлять, когда ingress несколько штук. Подробно до ingress еще не дошел.
Еще важный момент, что для нескольких ингресс надо как-то решать вопрос с плавающим ip, чтобы все продолжало работать после смены ноды. Я пока не знаю, как все это корректно настроить, не разбирался.
Для этого Nginx Ingress Controller деплоится как kind: DaemonSet, то есть Nginx Ingress будет задеплоин на всех воркерах (или на всех воркерах с нужным label, если указанно). Балансировку, если говорить про bare metal за nat, можно организовать на роутере если он может в l4 l7, metallb или поставить перед k8s HAproxy и др.
А какой в итоге ip адрес будет на ingress контроллере, чтобы на него слать запросы с внешнего балансера? Это будет dns имя со списком ip всех нод, где запущен ingress или какой-то плавающий ip, который кубер будет сам перекидывать между ингрессами? Как это технически реализуется, на какой технологии?
Раз поднимается такая тема как Kubernetes, то может быть хотя бы параллельно сначала запустить цикл статьей про Docker? Так сказать, чтобы начать с основ.
Нет возможности писать об этом. К тому же в интернете полно материалов про docker, хотя лично я бесплатных хороших курсов не видел. Но можно на хабре поискать статьи. Там было много best practices, по которым можно научиться правильно с ним работать.
Может я, конечно и лох, но под Centos 7 мне ни разу не удалось через кубеспрея установить кубер, если в его настройках была опция настройки докера. Сие чудо так раздалбывает system.d -скрипт, что запуск docker'a становится невозможным :) Вот если на все ее хосты заранее поставить докер запретить кубеспрею его настройку, то усё пройдет ОК
Вот мой пример, как установить на Centos 7. Я ни разу проблем не испытывал. Думаю, проблема была в том, что до какого-то обновления, вроде 7.4, если не ошибаюсь, у Centos 7 было старое ядро, в которое не портировали некоторые нововведения для нормальной работы докера. Вот в то время проблемы реально были, приходилось ставить новое 4.х ядро перед работой с докером. Но сейчас все это в прошлом и проблем нет.
В качестве Ingress Controller можно же использовать HAProxy? Не будет ли гибче ситсема управления?
Можно, конечно. Удобство ingress именно в том, что он интегрирован в работу кластера, его легко и удобно настраивать. С HAProxy, как я понимаю, будет больше возни для получения того же результата.
про ансибл , гит и тимсити особенно интересно ) Было бы здорово если бы у вас получилось написать статьи
Мне кажется важный момент, что желательно перед изучением кубика изучить докер
Это само собой. Зачем тебе кубернетис, если ты не знаешь докер.
Владимир после того как ты вплотную занялся технологиями Devops не чувствуется необходимости на рабочей станции иметь или линукс или MacOS?
Вообще не ощущаю. В Windows у меня есть все необходимые рабочие инструменты. Да и в целом, вся настройка идет по ssh. В системе по сути нужен только удобный ssh клиент и все. Дальше уже не важно, что там за ОС.
xshell?
Да, одна из старых версий. Подробно о своих программах писал в статье - https://serveradmin.ru/programmyi-sistemnogo-administratora/
Статье уже целый час! Когда продолжение?