
Продолжаю цикл статей про кластерные решения, который был начат с установки kubernetes. Я расскажу как установить и настроить кластер ceph, также покажу, как им потом пользоваться. Статья с практическими примерами от и до - поднятие кластера и подключение дисков к конечным серверам.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном онлайн-курcе по администрированию MikroTik. Автор курcа – сертифицированный тренер MikroTik Дмитрий Скоромнов. Более 40 лабораторных работ по которым дается обратная связь. В три раза больше информации, чем в MTCNA.
Реклама ИП Скоромнов Д.А. ИНН 331403723315
Цели статьи
- Рассказать своими словами о том, что такое Ceph, для чего нужен и какие есть аналоги.
- Развернуть тестовый кластер ceph с помощью ansible-playbook.
- Показать работу с кластером - подключение rbd дисков, запись данных в cephfs.
- Проверить поведение кластера при отказе одного из узлов.
Что такое Ceph
Ceph - программная объектная отказоустойчивая сеть хранения данных. Для чего нужна Ceph? Она реализует возможность файлового и блочного доступа к данным. Оба этих варианта я рассмотрю в своей статье. Это бесплатное программное обеспечение, которое устанавливается на Linux системы и может состоять из огромного количества узлов.
Для того, чтобы потестировать ceph, достаточно трех практически любых компьютеров или виртуальных машин. Моя тестовая лаборатория, на которой я буду писать статью, состоит из 3-х виртуальных машин с операционной системой Debian со следующими характеристиками.
| CPU | 2 |
| RAM | 4G |
| DISK | /dev/sda 20G, /dev/sdb 20G |
Это минимальная конфигурация для ceph, с которой стоит начинать тестирование. Из трех машин будет собран кластер ceph, а к четвертой я буду монтировать диски для проверки работоспособности.
Архитектура Ceph
Кластерная система хранения данных ceph состоит из нескольких демонов, каждый из которых обладает своей уникальной функциональностью. Расскажу о них кратко своими словами.
- MON, Ceph monitor - монитор кластера, который отслеживает его состояние. Все узлы кластера сообщают мониторам информацию о своем состоянии. Когда вы монтируете хранилища кластера к целевым серверам, вы указываете адреса мониторов. Сами мониторы не хранят непосредственно данные.
- OSD, Object Storage Device - элемент хранилища, который хранит сами данные и обрабатывает запросы клиентов. OSD являются основными демонами кластера, на которые ложится большая часть нагрузки. Данные в OSD хранятся в виде блоков.
- MDS, Metadata Server Daemon - сервер метаданных. Он нужен для работы файловой системы CephFS. Если вы ее не используете, то MDS вам не нужен. К примеру, если кластер ceph предоставляет доступ к данным через блочное устройство RBD, сервер метаданных разворачивать нет необходимости. Разделение метаданных от данных значительно увеличивает производительность кластера. К примеру, для листинга директории нет необходимости дергать OSD. Данные берутся из MDS.
- MGR, Manager Daemon - сервис мониторинга. До релиза Luminous был не обязательным компонентом, теперь - неотъемлемая часть кластера. Демон обеспечивает различный мониторинг кластера - от собственного дашборда до выгрузки метрик через json. Очень удобно. Мониторинг кластера не представляет особых сложностей.
Кластер ceph состоит из пулов для хранения данных. Каждый pool может обладать своими настройками. Пулы состоят из Placement Groups (PG), в которых хранятся объекты с данными, к которым обращаются клиенты.
В каждом кластере ceph имеется понятие фактора репликации - это уровень избыточности данных, или по простому - сколько копий данных будет храниться на разных дисках. Фактор репликации можно задавать разным для каждого пула и менять на лету.
Аналоги
Вообще говоря, Ceph достаточно уникальное кластерное решение, прямых аналогов которого нет. Но есть некоторые системы, схожие по решаемым проблемам. Основным аналогом Ceph является GlusterFS, которую я рассмотрю ниже отдельно. Так же к аналогам можно отнести следующие кластерные системы хранения данных:
- Файловая система ocfs2.
- OpenStack Swift.
- Sheepdog.
- HDFS (Hadoop Distributed File System)
- LeoFS
Список не полный. Это только то, что вспомнил я из того, что слышал. Сразу оговорюсь, что перечисленные системы мне практически не знакомы. Список привожу только для того, что, чтобы вам было проще потом самим найти о них информацию и сравнить. Они не являются полными аналогами ceph, но в каких-то вариантах могут подойти больше, нежели он. К примеру, Sheepdog намного проще система и потребности только в хранилище для виртуальных машин может закрывать лучше, чем ceph.
Теперь рассмотрим отдельно GlusterFS.
CephFS vs GlusterFS
Я не буду строить из себя эксперта и пытаться что-то объяснить в том, в чем не разбираюсь. На хабре есть очень подробная статья о сравнении Cephfs с GlusterFS от человека, который использовал обе системы. Если вам интересна тема подобного сравнения, то внимательно прочитайте. Я приведу краткие выводы, которые вынес сам из этой статьи.
- Glusterfs менее стабильная и у нее больше критических багов, которые приводят к повреждению данных.
- Ceph более гибкая и функциональная система.
- В ceph можно добавлять диски любого размера и каждый будет иметь зависимый от размера вес. Данные будут размещаться по дискам почти равномерно. В glusterfs диски добавляются парами или тройками в зависимости от фактора репликации. В итоге в glusterfs не получится просто вытащить старые диски меньшего объема и поставить новые больше. Вам нужно будет менять диски сразу у всей группы, выводя ее из работы. В ceph такой проблемы нет, можно спокойно заменять старые диски на новые большего объема.
- Архитектурно ceph быстрее и надежнее обрабатывает отказы дисков или серверов.
- GlusterFS лучше масштабируется. Есть примеры огромных инсталляций.
- В случае фактора репликации 2 у GlusterFS есть отличное решение с внешним арбитром.
Подводя итог статьи, автор отмечает, что CephFS более сложное но и более функциональное решение. Я так понял, он отдает предпочтение ему.
Опыт использования
Своего опыта поддержки Ceph в production у меня нет. Я его устанавливал для тестовых окружений у себя и по просьбе со стороны. Так что как и в предыдущем разделе поделюсь сторонними материалами на эту тему, которые изучал сам и они мне показались полезными.
Во-первых, очень интересная и популярная статья - Ceph. Анатомия катастрофы. Автор очень подробно рассматривает, как развивается ситуация в случае деградации кластера и дает советы по проектированию, чтобы восстановление прошло с наименьшими потерями. К слову, я тестировал на своем кластере отказ одной из трех нод и наблюдал примерно ту же картину, что описывает автор. Кластер начинает очень-очень сильно тормозить и привести его в чувство не так просто. После ввода в работу упавшей ноды, кластер вставал колом. Без подготовки и тренировки вся заявленная отказоустойчивость кластера ceph может вылететь в трубу и вы получите остановленный сервис. Там же в статье автор дает совет не отключать swap. А, к примеру, при установке Kubernetes, его наоборот нужно обязательно отключить.
Еще одна статья, которой хотел бы с вами поделиться на эту тему - А вот вы говорите Ceph… а так ли он хорош? Автор обращает внимание на огромное количество настроек ceph, большая часть из которых не понятно, что означает и за что отвечает :) Так же он делится своим опытом эксплуатации большого и нагруженного кластера. Некоторые вещи удивляют, и становится не понятно, как это ставить в production. Тем не менее люди ставят и это вроде как даже нормально работает. Но однозначно это путь смелых! В комментариях автор явно не ответил, но стало понятно, что его кластер не имеет бэкапа! Как вам такое? Сложнейшая распределенная система, которая может превратиться в тыкву и нет бэкапов. Админам таких систем нужно доплачивать за риск. Я бы не стал работать в такой должности. Мне спокойная жизнь дороже даже повышенной оплаты за обслуживание таких систем.
Как я понял из этих статей, нагруженный ceph требует очень внимательного мониторинга и обслуживания. Требуется постоянно дежурный инженер и готовые инструкции на наиболее популярные инциденты - замена дисков, отказ сервера, переполнение osd и т.д. Всё это нужно заранее тестировать и документировать.
Подготовка настроек
Ну что же, с теоретической частью закончили, начинаем практику. Мы будем устанавливать ceph с помощью официального playbook для ansible. Отмечу, что в настоящий момент этот способ установки признан устаревшим. Взамен предлагается использовать cephadm. Подробности установки подобным образом можно посмотреть в документации. Тем не менее, установка через ansible пока ещё поддерживается. Свежую стабильную версию поставить можно, чем мы и займёмся.
Клонируем к себе репозиторий на машину, откуда будет выполнять установку. У меня это одна из VM кластера.
# git clone https://github.com/ceph/ceph-ansible
Переключаемся на последнюю стабильную ветку 7.0.
# cd ceph-ansible # git checkout stable-7.0
Устанавливаем pip:
# apt install python3-pip
К сожалению, в репозиториях Debian хранится довольно старая версия pip, с которой потом в процессе установки ceph возникнут проблемы с модулем pyopenssl, поэтому сверху я устанавливаю более свежую версию. Использую для этого сторонний установщик. Насколько ему можно доверять, судить не берусь. Вы можете сами обновить pip любым образом.
# curl -sSL https://bootstrap.pypa.io/get-pip.py -o get-pip.py # python3 get-pip.py
После этого необходимо завершить сеанс и подключиться заново, чтобы обновилось окружение. Устанавливаем дополнительные зависимости:
# pip install -r requirements.txt # ansible-galaxy install -r requirements.yml
Если во время установки вы будете подключаться к нодам с использованием пароля, а не сертификатов, то дополнительно поставьте sshpass.
# apt install sshpass
Теперь подготовим инвентарь для playbook. Создаем в корне репозитория папку inventory.
# mkdir inventory && cd inventory
В ней создаем файл hosts примерно следующего содержания.
[mons] cluster-01 monitor_address=10.20.1.41 cluster-02 monitor_address=10.20.1.42 cluster-03 monitor_address=10.20.1.43 [osds] cluster-01 cluster-02 cluster-03 [mgrs] cluster-01 cluster-02 cluster-03 [mdss] cluster-01 cluster-02 cluster-03 [monitoring] cluster-01 cluster-02 cluster-03
Для примера я взял 3 виртуальные машины: cluster-01, cluster-02, cluster-03 с двумя жесткими дисками:
- sda под систему
- sdb под данные кластера ceph
В инвентаре несколько групп серверов:
- mons - монитор кластера
- osds - демон хранения
- mgrs - менеджер
- mds - сервер метаданных
- monitoring - сервер мониторинга prometheus и grafana
У меня все сервера равнозначные, поэтому на всех будет стоять всё.
Дальше нам нужно указать некоторые параметры кластера. Делаем это в файле all.yml в директории group_vars.
ceph_origin: repository
ceph_repository: community
ceph_stable_release: quincy
public_network: "10.20.1.0/24"
cluster_network: "10.20.1.0/24"
cluster: ceph
osd_objectstore: bluestore
osd_scenario: lvm
devices:
- '/dev/sdb'
ntp_service_enabled: true
ntp_daemon_type: chronyd
dashboard_enabled: True
dashboard_protocol: http
dashboard_admin_user: admin
dashboard_admin_password: p@ssw0rd
grafana_admin_user: admin
grafana_admin_password: p@ssw0rd
ceph_conf_overrides:
global:
osd_pool_default_pg_num: 64
osd_journal_size: 5120
osd_pool_default_size: 3
osd_pool_default_min_size: 2
Небольшие пояснения к некоторым переменным:
- ceph_origin - откуда будет выполняться установка. В моем случае из репозитория.
- ceph_repository - название репозитория. В данном случае community, есть еще rhcs от redhat.
- ceph_stable_release - название последнего стабильного релиза.
- public_network - сеть, откуда будут приходить запросы в кластер.
- cluster_network - сеть для общения самого кластера. У меня небольшой тестовый кластер, поэтому сеть общая. Для больших кластеров cluster_network надо делать отдельной с хорошей пропускной способностью.
- osd_objectstore - тип хранения данных, bluestore - общая рекомендация для использования.
- osd_scenario - как будут храниться данные, в данном случае в lvm томах.
- devices - устройства, которые будет использовать ceph. Если их не указать, будут использованы все незадействованные диски.
- osd_pool_default_pg_num - кол-во placement groups. Стандартная формула для расчета этой штуки - (OSD * 100) / кол-во реплик. Результат должен быть округлён до ближайшей степени двойки. Если получилось 700, округляем до 512.
- osd_pool_default_pgp_num - настройка для размещения pg, служебная штука, рекомендуется ее выставлять такой же, как количество pg. В последних версиях установщика её лучше не указывать, так как финальные проверки после установки кластера проходят с параметром autoscale_mode=on, что приводит к конфликту и ошибке, если pgp_num указан явно. Этот параметр остался от прошлых версий статьи. Решил не убирать его для справки.
- osd_journal_size - размер журнала в мегабайтах. Я оставил дефолтное значение в 5 Гб, но если у вас маленький тестовый кластер можно уменьшить, или наоборот увеличить в больших кластерах.
- osd_pool_default_size - количество реплик данных в нашем кластере, 3 - минимально необходимое для отказоустойчивости.
- osd_pool_default_min_size - количество живых реплик, при которых пул еще работает. Если будет меньше, запись блокируется.
С инвентарем и параметрами разобрались. У нас почти все готово для установки ceph. Осталось создать файл site.yml в корневой папке репозитория, скопировав site.yml.sample.
# cp site.yml.sample site.yml
В файле оставляем все значения дефолтными.
В завершении на все хосты кластера добавьте записи в файлы /etc/hosts, чтобы ноды могли общаться друг с другом по имени.
10.20.1.41 cluster-01 10.20.1.42 cluster-02 10.20.1.43 cluster-03
Если у вас настроен DNS сервер и имена и так резолвятся в ip адреса, то делать этого не надо.
Вычисление Placement Groups (PG)
Самая большая трудность в вычислении PG это необходимость соблюсти баланс между количеством групп на OSD и их размером. Чем больше PG на одной OSD, тем больше вам надо памяти для хранения информации об их расположении. А чем больше размер самой PG, тем больше данных будет перемещаться при балансировке.
Получается, что если у вас мало PG, они у вас большого размера, надо меньше памяти, но больше трафика уходит на репликацию. А если больше, то все наоборот. Теоретически считается, что для хранения 1 Тб данных в кластере надо 1 Гб оперативной памяти.
Как я уже кратко сказал выше, примерная формула расчета PG такая - Total PGs = (Number OSD * 100) / max_replication_count. Конкретно в моей установке по этой формуле получается цифра 100, которая округляется до 128. Но если задать такое количество pg, то роль ansible отработает с ошибкой:
Error ERANGE: pg_num 128 size 3 would mean 768 total pgs, which exceeds max 750 (mon_max_pg_per_osd 250 * num_in_osds 3)
Суть ошибки в том, что максимальное количество pg становится больше, чем возможно, исходя из параметра mon_max_pg_per_osd 250. То есть не более 250 на один OSD. Я не стал менять этот дефолтный параметр, а просто установил количество pg_num 64. Более подробная формула есть на официальном сайте - https://old.ceph.com/pgcalc/.
Существует проблема выделения pg и состоит она в том, что у нас в кластере обычно несколько пулов. Как распределить pg между ними? В общем случае поровну, но это не всегда эффективно, потому что в каждом пуле может храниться разное количество и типов данных. Поэтому для распределения pg по пулам стараются учитывать их размеры. Для этого тоже есть примерная формула - pg_num_pool = Total PGs * % of SizeofPool/TotalSize.
Количество PG можно изменять динамически. К примеру, если вы добавили новые OSD, то вы можете увеличить и количество PG в кластере. В последней версии ceph, которая еще не lts, появилась возможность уменьшения Placement Groups.
Установка ceph
Запускаем установку Ceph с помощью playbook ansible.
# cd ~/ceph-ansible/ # ansible-playbook -u root -k -i inventory/hosts site.yml -b --diff
Если вы используете авторизацию по паролю, то можете получить ошибку подключения к ssh. Я с этим сталкивался в прошлых версиях. Когда вывел расширенный лог ошибок плейбука, увидел, что ansible подключается по ssh с использованием публичного ключа, который я не задаю. Изменить это можно в конфиге ansible.cfg, который лежит в корне репозитория. Находим там строку:
ssh_args = -o ControlMaster=auto -o ControlPersist=600s -o PreferredAuthentications=publickey
и удаляем параметр для publickey, чтобы получилось вот так:
ssh_args = -o ControlMaster=auto -o ControlPersist=600s
После этого заново запускайте развертывание ceph. У меня оно прервалось ошибкой:
The conditional check 'item.disk.table == 'gpt'' failed. The error was: error while evaluating conditional (item.disk.table == 'gpt'): 'dict object' has no attribute 'disk'
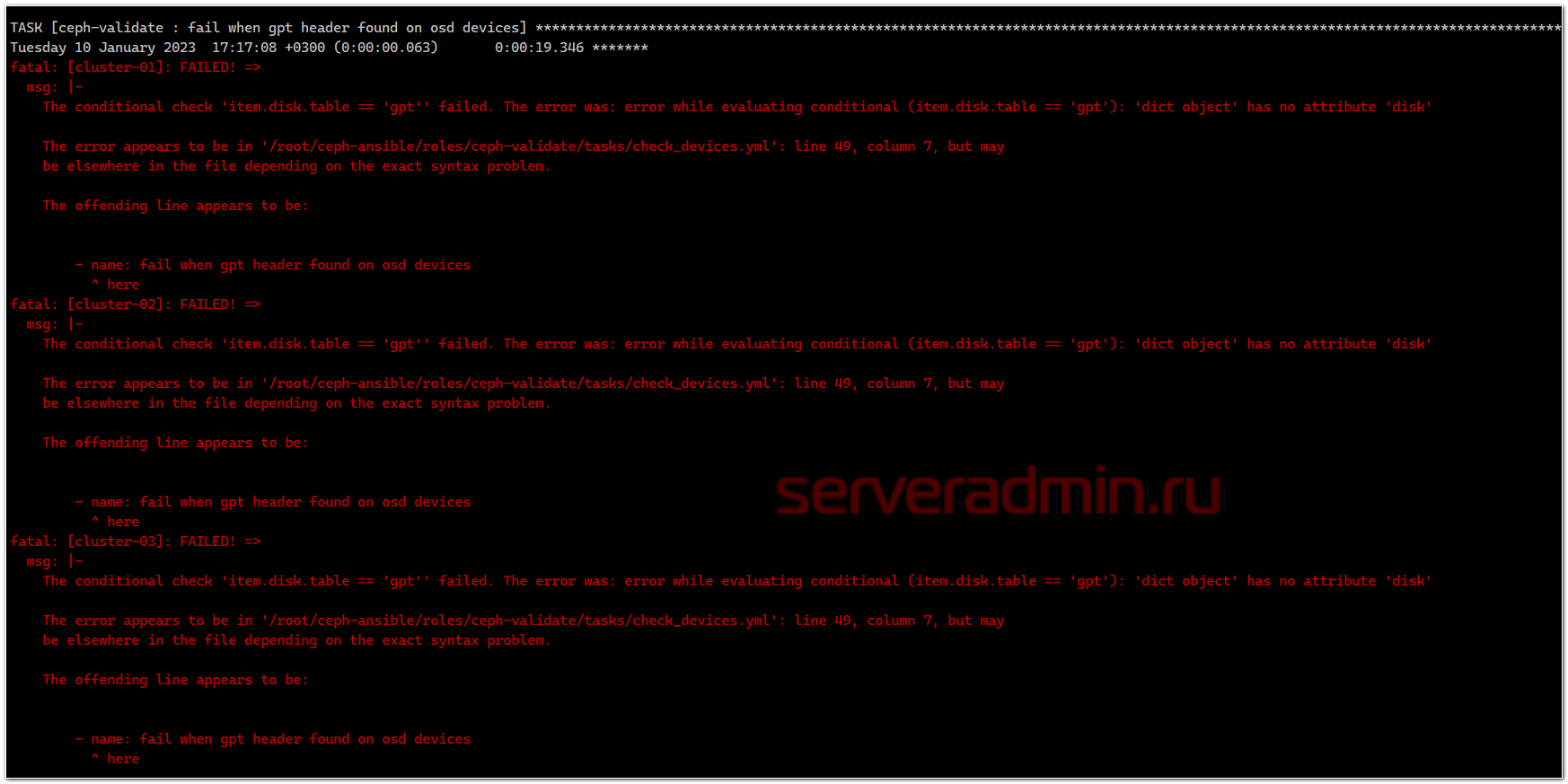
Суть её в том, что на дисках, в моём случае /dev/sdb, не должно быть никакой разметки, и они должны быть объектом типа disk. Проверить это можно через lsblk. У меня все условия выполнялись. Разметки GPT не было, тип был disk. Я не смог разобраться, в чём конкретно тут проблема. Просто взял и удалил эту проверку из плейбука. Для этого открыл файл ceph-ansible/roles/ceph-validate/tasks/check_devices.yml на 49 строке, как указано в ошибке и удалил этот шаг с проверкой.
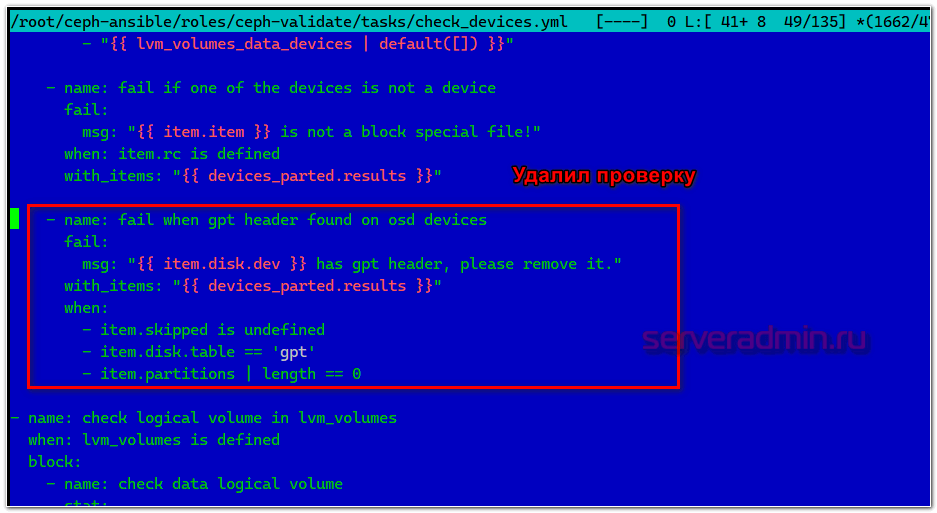
После этого заново запустил установку. Она должна пойти без ошибок. В конце увидите примерно такое сообщение.
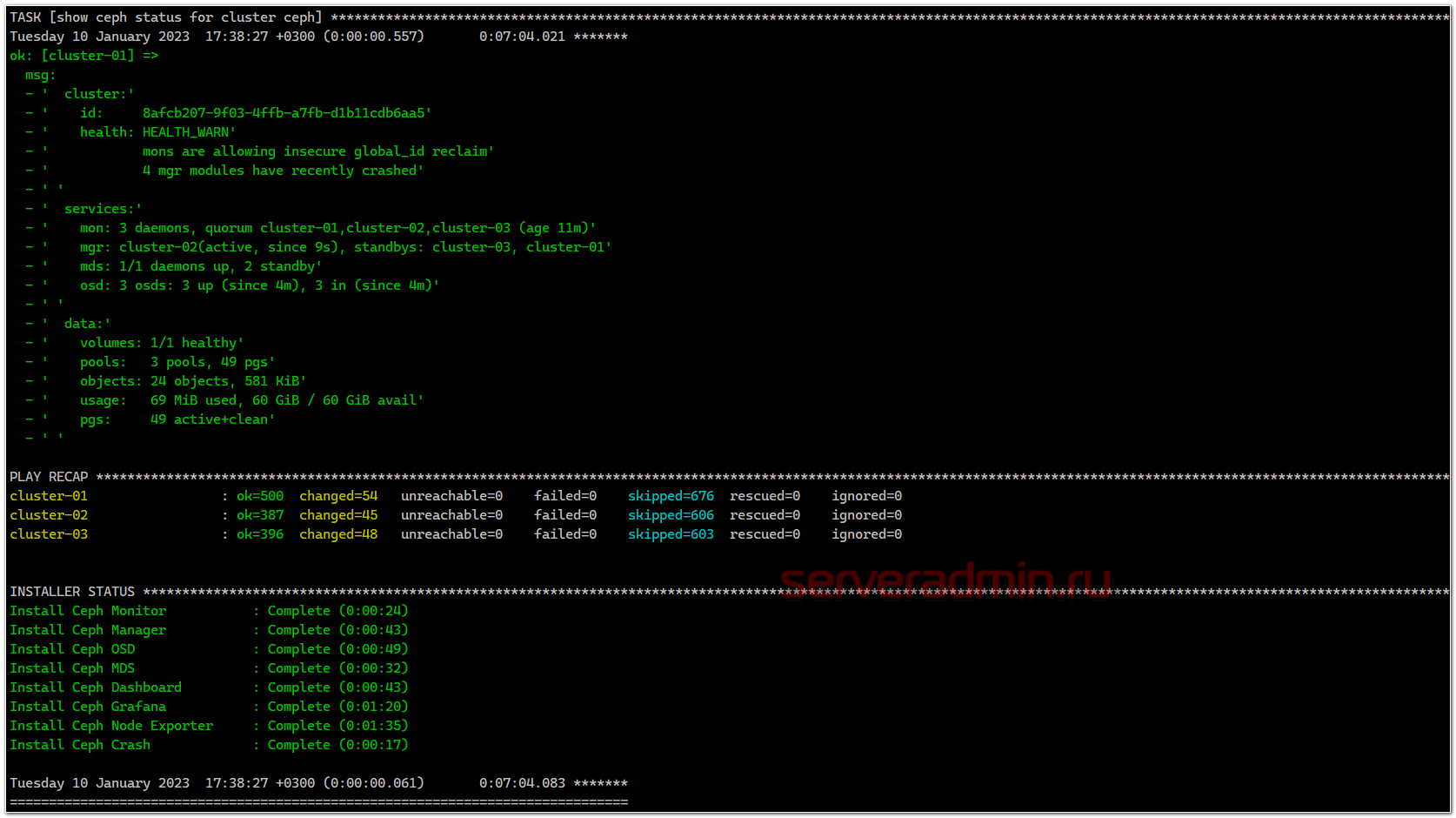
Если будут какие-то ошибки и счетчик failed не будет равен нулю, то разбирайте ошибки, исправляйте их и запускайте роль заново, пока она не закончится без ошибок.
После установки Ceph, можно проверить статус кластера командой, которую нужно выполнить на одной из нод кластера.
# ceph status

mon: 3 daemons, quorum cluster-01,cluster-02,cluster-03 (age 16m)
Вы должны увидеть примерно то же самое, что на скриншоте выше. 3 монитора работают в кворуме, друг друга видят, всё хорошо.
mgr: cluster-02(active, since 5m), standbys: cluster-03, cluster-01
Менеджеры работают в режиме активный и ждущие - 1 активен, остальные ожидают.
Есть некоторые замечания. Например:
mons are allowing insecure global_id reclaim
Убрать это уведомление можно отключив insecure подключения:
# ceph config set mon auth_allow_insecure_global_id_reclaim false
У меня также присутствуют предупреждения вида:
4 mgr modules have recently crashed
Насколько я понял, это произошло из-за ошибок c модулями pip во время установки. У меня не с первого раза отработал плейбук. Я вносил исправления и запускал заново. Посмотреть эти ошибки можно вот так:
# ceph crash ls # ceph crash info <crash-id>
Подозреваю, что если их количество не растёт, то проблем нет. Можно попробовать сделать заново чистую установку сразу без ошибок. Удалить их из статуса можно командой:
# ceph crash archive-all
Кластер ceph установлен. Дальше разберем, как с ним работать.
По адресу http://10.20.1.41:8443 можно попасть в панель управления кластером. Учётные данные те, что указаны в all.yml.

По адресу 10.20.1.41:9092 живёт Prometheus, а по http://10.20.1.41:3000 Grafana с набором дашбордов для мониторинга за Ceph.
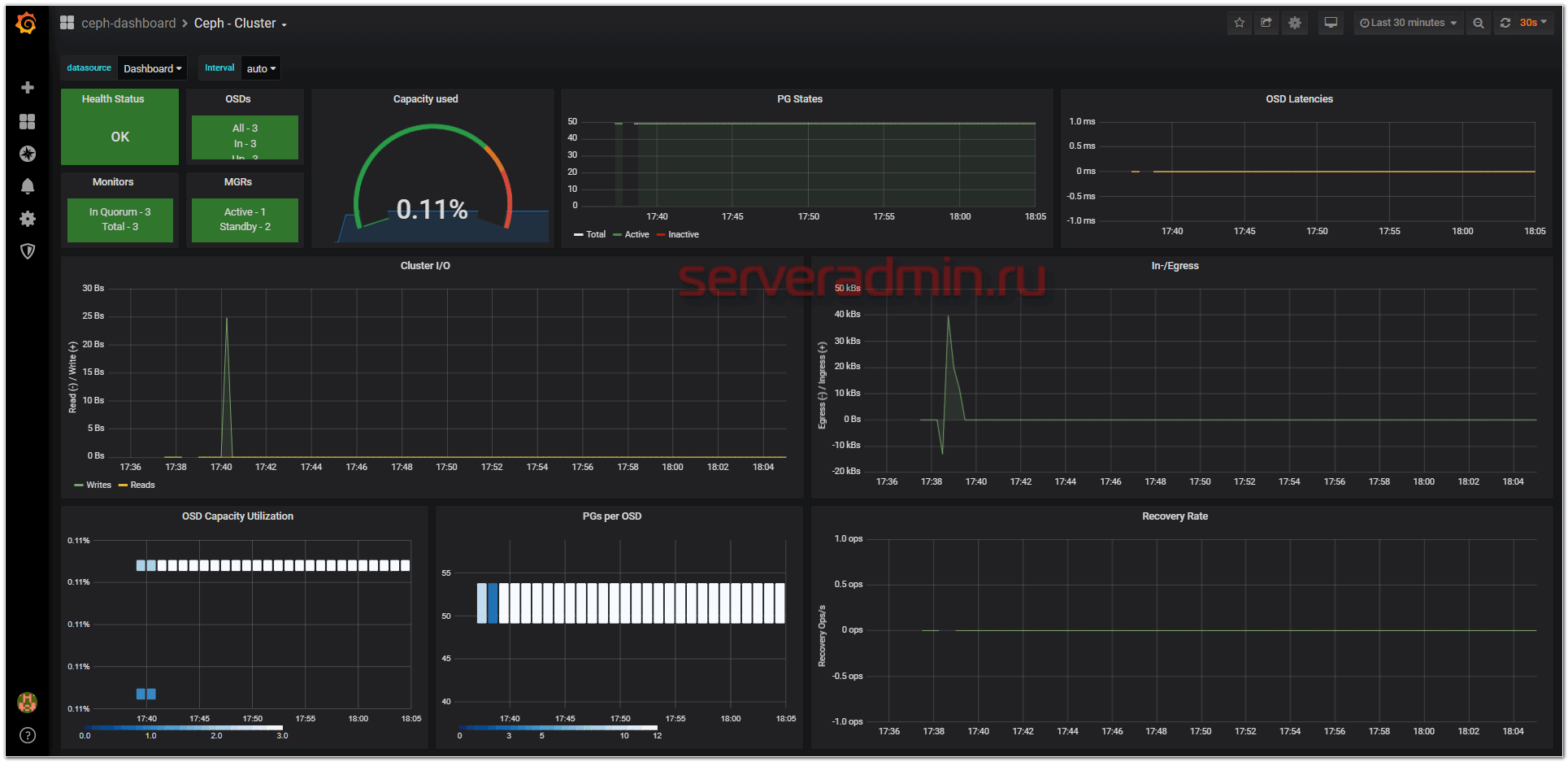
Сервер установлен с полным набором инструментов для управления и мониторинга.
Основные команды
Пройдемся по основным командам ceph, которые вам пригодятся при эксплуатации кластера. Основная - обзор состояния кластера:
# ceph -s
Традиционный ключ -w к команде для отслеживания изменений в реальном времени:
# ceph -w
Посмотреть список пулов в кластере:
# rados lspools
Статистика использования кластера:
# ceph df
Список всех ключей учетных записей кластера:
# ceph auth list
Состояние кворума:
# ceph quorum_status
Просмотр дерева OSD:
# ceph osd tree
Статистика OSD:
# ceph osd dump
Статистика PG:
# ceph pg stat
Список PG:
# ceph pg dump
Создание или удаление OSD:
# ceph osd create || ceph osd rm
Создание или удаление пула:
# ceph osd pool create || ceph osd pool delete
Тестирование производительности OSD:
# ceph tell osd.1 bench
Использование кластера ceph
Для начала давайте посмотрим, какие пулы у нас уже есть в кластере ceph.
# rados lspools
cephfs_data cephfs_metadata
Это дефолтные пулы для работы cephfs, которые были созданы в момент установки кластера. Сейчас подробнее на этом остановимся. Ceph представляет для клиента различные варианты доступа к данным:
- файловая система cephfs;
- блочное устройство rbd;
- объектное хранилище с доступом через s3 совместимое api.
Я рассмотрю два принципиально разных варианта работы с хранилищем - в виде cephfs и rbd. Основное отличие в том, что cephfs позволяет монтировать один и тот же каталог с данными на чтение и запись множеству клиентов. RBD же подразумевает монопольный доступ к выделенному хранилищу. Начнем с cephfs. Для этого у нас уже все готово.
Подключение Cephfs
Как я уже сказал ранее, для работы cephfs у нас уже есть pool, который можно использовать для хранения данных. Я сейчас подключу его к одной из нод кластера, где у меня есть административный доступ к нему и создам в пуле отдельную директорию, которую мы потом смонтируем на другой сервер.
Монтируем pool.
# mount.ceph 10.20.1.41:/ /mnt/cephfs -o name=admin,secret=`ceph auth get-key client.admin`
В данном случае 10.1.4.32 адрес одного из мониторов. Их надо указывать все три, но сейчас я временно подключаю пул просто чтобы создать в нем каталог. Достаточно и одного монитора. Я использую команду:
# ceph auth get-key client.admin
для того, чтобы получить ключ пользователя admin. С помощью такой конструкции он нигде не засвечивается, а сразу передается команде mount. Проверим, что у нас получилось.
# df -h | grep cephfs 10.20.1.41:/ 19G 0 19G 0% /mnt/cephfs
Смонтировали pool. Его размер получился 19 Гб. Напоминаю, что у нас в кластере 3 диска по 20 Гб, фактор репликации 3. По факту у нас есть 19 Гб свободного места для использования в кластере ceph. Это место делится поровну между всеми пулами. К примеру, когда у нас появятся rbd диски, они будут делить этот размер вместе с cephfs.
Создаем в cephfs директорию data1, которую будем монтировать к другому серверу.
# mkdir /mnt/cephfs/data1
Теперь нам нужно создать пользователя для доступа к этой директории.
# ceph auth get-or-create client.data1 mon 'allow r' mds 'allow r, allow rw path=/data1' osd 'allow rw pool=cephfs_data' [client.data1] key = AQBLRDBePhITJRAAFpGaJlGmqOj9RCXhMdIQ+w==
На выходе получите ключ от пользователя. Что я сделал в этой команде:
- Создал клиента data1;
- Выставил ему права к разным сущностям кластера (mon, mds, osd);
- Дал права на запись в директорию data1 в cephfs.
Если забудете ключ доступа, посмотреть его можно с помощью команды:
# ceph auth get-key client.data1
Теперь идем на любой другой сервер в сети, который поддерживает работу с cephfs. Это практически все современные дистрибутивы linux. У них поддержка ceph в ядре. Монтируем каталог кластера ceph, указывая все 3 монитора.
# mount -t ceph 10.20.1.41,10.20.1.42,10.20.1.43:/ /mnt -o name=data1,secret='AQBLRDBePhITJRAAFpGaJlGmqOj9RCXhMdIQ+w=='
Проверяем, что получилось.
# df -h | grep mnt 10.20.1.41,10.20.1.42,10.20.1.43:/ 19G 0 19G 0% /mnt
Каталог data1 на файловой системе cephfs подключен. Можете попробовать на него что-то записать. Этот же файл вы должны увидеть с любого другого клиента, к которому подключен этот же каталог.
Теперь настроим автомонтирование диска cephfs при старте системы. Для этого надо создать конфиг файл /etc/ceph/data1.secret следующего содержания.
AQBLRDBePhITJRAAFpGaJlGmqOj9RCXhMdIQ+w==
Это просто ключ пользователя data1. Добавляем в /etc/fstab подключение диска при загрузке.
10.20.1.41,10.20.1.42,10.20.1.43:/ /mnt ceph name=data1,secretfile=/etc/ceph/data1.secret,_netdev,noatime 0 0
Не забудьте в конце файла fstab сделать переход на новую строку, иначе сервер у вас не загрузится. Теперь проверим, все ли мы сделали правильно. Если у вас уже смонтирован диск, отмонтируйте его и попробуйте автоматически смонтировать на основе записи в fstab.
# umount /mnt # mount -a
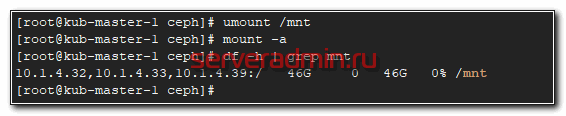
На этом по поводу cephfs все. Можно пользоваться. Переходим к блочным устройствам rbd.
Ceph RBD
Теперь давайте создадим rbd диск в кластере ceph и подключим его к целевому серверу. Для этого идем в консоль на любую ноду кластера. Создаем pool для rbd дисков.
# ceph osd pool create rbdpool 32
| rbdpool | название пула, может быть любым |
| 32 | 32 - кол-во pg (placement groups) в пуле |
Проверим список пулов кластера.
# rados lspools
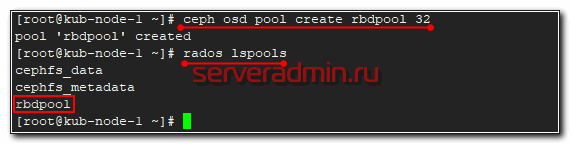
Создаем в этом пуле rbd диск на 10G.
# rbd create disk1 --size 10G --pool rbdpool
Добавим пользователя с разрешениями на использование этого пула. Делается точно так же, как в случае с cephfs, что мы проделали ранее.
# ceph auth get-or-create client.rbduser mon 'allow r, allow command "osd blacklist"' osd 'allow rwx pool=rbdpool'
В консоли увидите ключ пользователя rbduser для подключения пула rbdpool.
Перемещаемся на целевой сервер, куда мы будем подключать rbd диск кластера ceph. Для подключения blockdevice нам необходимо поставить программное обеспечение из репозитория ceph-luminous на сервер, где будет использоваться rbd.
# yum install centos-release-ceph-luminous # yum install ceph-common
Также запишем на целевой сервер ключ клиента, который имеет доступ к пулу с дисками. Создаем файл /etc/ceph/ceph.client.rbduser.keyring следующего содержания.
[client.rbduser] key = AQCW5DFeXNy2JRAAWnCU/DpZhuNHmNcI5l1sEQ==
Там же создаем конфигурационный файл /etc/ceph/ceph.conf, где нам необходимо указать ip адреса мониторов ceph.
mon host = 10.20.1.41,10.20.1.42,10.20.1.43
Пробуем подключить блочное устройство.
# rbd map disk1 --pool rbdpool --id rbduser rbd: sysfs write failed RBD image feature set mismatch. You can disable features unsupported by the kernel with "rbd feature disable rbdpool/disk1 object-map fast-diff deep-flatten". In some cases useful info is found in syslog - try "dmesg | tail". rbd: map failed: (6) No such device or address
Скорее всего получите такую же или подобную ошибку. Суть ее в том, что текущее ядро поддерживает не все возможности образа RBD, поэтому их нужно отключить. Как это сделать показано в подсказке. Для отключения нужен администраторский доступ в кластер. Так что идем на любую ноду пула и выполняем там предложенную команду.
# rbd feature disable rbdpool/disk1 object-map fast-diff deep-flatten
Не должно быть никаких ошибок, как и любого вывода после работы команды. Возвращаемся на целевой сервер и пробуем подключить rbd диск еще раз.
# rbd map disk1 --pool rbdpool --id rbduser /dev/rbd0
Все в порядке. В системе появился новый диск - /dev/rbd0. Создадим на нем файловую систему и подмонтируем к серверу.
# mkfs.xfs -f /dev/rbd0 # mkdir /mnt/rbd # mount /dev/rbd0 /mnt/rbd # df -h | grep rbd
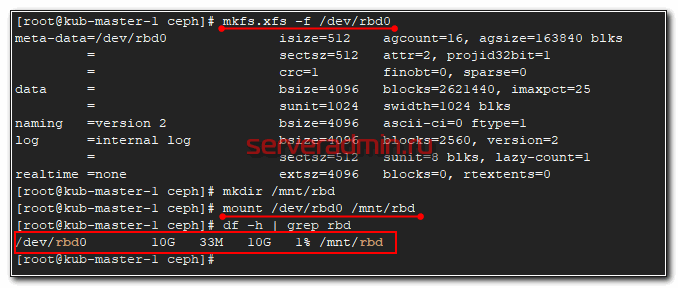
Можно попробовать туда что-то записать и посмотреть на скорость.
# dd if=/dev/zero of=/mnt/rbd/testfile bs=10240 count=100000 100000+0 records in 100000+0 records out 1024000000 bytes (1.0 GB) copied, 6.88704 s, 149 MB/s
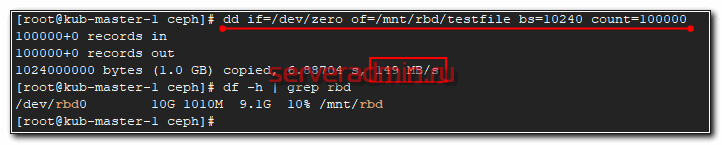
Не знаю, что я измерил :) На самом деле это скорость одиночного sata диска, на котором установлена система сервера, которому я подключил диск. Так понимаю, запись вся ушла в буфер, а потом началась синхронизация по кластеру.
Настроим теперь автоматическое подключение rbd диска при старте системы. Для начала надо настроить mapping диска. Для этого создаем конфиг файл /etc/ceph/rbdmap следующего содержания.
rbdpool/disk1 id=rbduser,keyring=/etc/ceph/ceph.client.rbduser.keyring
Запускаем скрипт rbdmap и добавляем в автозапуск.
# systemctl enable --now rbdmap Created symlink from /etc/systemd/system/multi-user.target.wants/rbdmap.service to /usr/lib/systemd/system/rbdmap.service.
Проверяем статус.
# systemctl status rbdmap
Осталось добавить монтирование блочного устройства rbd в /etc/fstab.
/dev/rbd/rbdpool/disk1 /mnt/rbd xfs noauto,noatime 0 0
И не забудьте в конце сделать переход на новую строку. После этого перезагрузите сервер и проверьте, что rbd диск кластера ceph нормально подключается.
Проверка надежности и отказоустойчивости
Расскажу, какие проверки отказоустойчивости ceph делал я. Напомню, что у меня кластер состоит всего из трех нод, да еще на sata дисках на двух разных гипервизорах. Многого тут не натестируешь :) Диски собраны в raid1, никакой нагрузки помимо ceph на серверах не было. Я просто выключал одну ноду. При этом в работе кластера не было никаких заметных изменений. С ним можно было нормально работать, писать и читать данные. Самое интересное начиналось, когда я запускал обратно выключенную ноду.
В этот момент запускался ребалансинг кластера и он начинал жутко тормозить. Настолько жутко, что в эти моменты я даже не мог зайти на ноды по ssh или напрямую с консоли, чтобы посмотреть, что именно там тормозит. Виртуальные машины вставали колом. Я пытался их отключать и включать по очереди, но ничего не помогало. В итоге я выключил все 3 ноды и стал включать их по одной. Очевидно, что и нагрузки никакой я не давал, так как кластер был не в состоянии обслуживать внешние запросы.
Включил сначала одну ноду, убедился, что она загрузилась и показывает свой статус. Запустил вторую. Дождался, когда полностью синхронизируются две ноды, потом включил третью. Только после этого все вернулось в нормальное состояние. При этом никаких действий с кластером я не производил. Только следил за статусом. Он сам вернулся в рабочее состояние. Данные все оказались на месте. Меня это приятно удивило, с учетом того, что я жестко выключал зависшие виртуалки несколько раз.
Как я понял, если у вас есть возможность снять с кластера нагрузку, то в момент деградации особых проблем у вас не будет. Это актуально для кластеров с холодными данными, например, под бэкапы или другое долгосрочное хранение. Там можно тормознуть задачи и дождаться ребаланса. Особых проблем с эксплуатацией ceph быть не должно. А вот если у вас идет постоянная работа с кластером, то вам нужно все внимательно проектировать, изучать, планировать, тестировать и т.д. Точно должен быть еще один тестовый кластер и доскональное понимание того, что вы делаете.
Заключение
Надеюсь, моя статья про описание, установку и эксплуатацию ceph была полезна. Постарался объяснять все простым языком для тех, кто только начинает знакомство с ceph. Мне система очень понравилась именно тем, что ее можно так легко разворачивать и масштабировать. Берешь обычные серверы, раскатываешь ceph, ставишь фактор репликации 3 и не переживаешь за свои данные. Его можно использовать его под бэкапы, docker registry или некритичное видеонаблюдение.
Переживать начинаешь, когда в кластер идет непрерывная высокая нагрузка. Но тут, как и в любых highload проектах, нет простых решений. Надо во все вникать, во всем разбираться и быть всегда на связи.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном онлайн-курcе по администрированию MikroTik. Автор курcа – сертифицированный тренер MikroTik Дмитрий Скоромнов. Более 40 лабораторных работ по которым дается обратная связь. В три раза больше информации, чем в MTCNA.
Реклама ИП Скоромнов Д.А. ИНН 331403723315

Напишите новую инструкцию для установки через cephadm.
в ubuntu root отключен, ключи ни по одной из инструкции не копируются, не отправляются, cph-common не ставится ни по одной из инструкций, но команды оттуда используются.
Нет пока ни одной нормальной инструкции, которая позволяет установить актуальную версию CEPH.
Уже 4 инструкция по которой пытаюсь на убунте 22.04 пытаюсь поставить CEPH, ни одна не позволяет установить CEPH и подключить ноды в кластер.
Осталась только snap microceph, которая скорее всего поставится без проблем, на снапе, который все хейтят. Но мне нужно развертывание на 3х нодах.
Конечно же рут в Убунте я включил, но всё равно по инструкции возникают другие проблемы.
https://yadi.sk/d/B0sUPwEei-ZDfQ
Возьмите и напишите сами. Как то вы смело предлагаете мне потратить несколько дней, чтобы вам было удобно. Я не располагаю свободным временем, чтобы поддерживать актуальность и тем более писать новые статьи по этой теме. Можете проспонсировать, если вам действительно это нужно.
Владимир, добрый день! Я наткнулся на вашу статью пока пытался решить проблему со своим Ceph кластером в k8s. Суть в том что я его успешно поднял на 3 узлах используя cephfs. Как я заметил уже существует подобный вопрос где вы ответили что RBD не поддерживает подключение более одного пода к диску (ReadWriteMany). Основная моя проблема в том что при использовании CephFS у меня сильно увеличивается задержка обмена данных, примерно в 4 раза. Я могу оставить RBD но тогда при падении сервака, k8s не сможет подключить новый под к pvc. Плюс ко всему я использую mssql с дисками от Ceph кластераесли это о чём-то говорит.
А вопрос у вас в чём? CephFS и другие подобные системы будут заметно медленнее блочных устройств при прочих равных условиях. С этим ничего не поделать.
Вопрос в том, можно как-нибудь использовать RBD таким образом что-бы при падении сервака приложение продолжало иметь доступ к данным PVC ? Единственное что на ум лезет так это установка CephFS поверх RBD (где-то такое решение находил) но к сожалению никак не могу найти какие-то туториалы по этому поводу.
если у кого-то валится установка на ошибке:
```
An exception occurred during task execution. To see the full traceback, use -vvv. The error was: AttributeError: module 'lib' has no attribute 'X509_V_FLAG_CB_ISSUER_CHECK'
```
то необходимо апгрейднуть пакет pyopenssl:
```pip install pyopenssl --upgrade```
С этим openssl часто бывают подобные проблемы. Сталкивался с такой же в другом проекте. Тоже не мог установить из-за проблем с зависимостями из-за pyopenssl.
Добрый день!
Спасибо за статью - всё вроде получилось, только один момент/вопрос возник - я созданный в ceph кластере rbd диск могу смонтировать на несколько отдельных машин чтобы они совместно видели файлы? или для этого cephFX надо использовать?
Просто вроде как смонтировать получилось, но вторая машина не видит файлы созданные на нем с первой...
И если нельзя в rbd то как то вообще можно увидеть что сейчас на этом диске если мы не находимся на машине к которой он примонтирован?
Спасибо!
Для одновременной работы по сети как раз cephFX придумана. А rbd диски для единоличного использования. Их нужно отмонтировать в одном месте и подмонтировать в другом, чтобы посмотреть, что там.
Спасибо! Действительно с fx все получилось - разные поды видят файлы совместно.
Добрый день!
А Вы, случаем, не планируете дополнить статью настройкой S3 под ceph?
Спасибо! )
А что именно интересует для S3? Можно поднять сервер Minio и подключить ему том от ceph.
Собственно интересует как к уже развернутому по статье кластеру ceph добавить возможность обращения по S3.
По minio, кстати, подумаю - возможно и подойдет вариант с ним, спасибо за подсказку! )
Но S3 тоже было бы интересно добавить...
на сколько я понял - возможность обращаться к кластеру по S3 можно реализовать сразу через плейбук которым мы ceph разворачивали?
Я такой информации не видел. S3 это отдельная реализация хранения файлов. Она с ceph никак не связана. Службу S3 можно развернуть на базе любой файловой системы или файлового хранилища.
Добрый день!
Вариант с minio отлично подошел. Как оказалось - для деплоя достаточно pvc указать.
Спасибо!
Статья на самом деле подойдёт лютым эникеям, которые разворачивают всё через хуяк-хуяк и в прод.
На самом деле, Владимир, я Вас уже комментировал во vk и ещё раз призываю обратить внимание на системные требования в плане сети.
https://docs.ceph.com/en/latest/start/hardware-recommendations/#networks
Там чёрным по белому написано "Обеспечьте подключение к сети НЕ МЕНЕЕ 10 Гбит/с в ваших стойках." То есть 10Гбит/с ЭТО МИНИМУМ!!!
Для репликации 1 ТБ данных по сети со скоростью 1 Гбит/с требуется три часа
для репликации 10 ТБ по сети со скоростью 1 Гбит/с требуется тридцать часов.
Но
для репликации 1 ТБ по сети со скоростью 10 Гбит/с требуется всего двадцать минут
для репликации 10 ТБ по сети со скоростью 10 Гбит/с требуется всего один час.
Собственно это и есть причина тормозов в Вашем посте, при отключении одной из нод.
P.S. я всегда восхищался Вашими мануалами и многое использовал у себя в проде, но местами Вы сдаёте позиции...
Странная претензия. Конечно, хорошо, когда у тебя есть 10G. Кто же спорит? Я разве против. На гигабите сеф тоже будет работать и я это сам наблюдал. Всё зависит от объёмов и нагрузки.
Опечатка в статье
"
Теперь подготовим инвентарь для palybook
"
Наверное , playbook
Добрый день!
Как я понял, Ceph нет смысла разворачивать на виртуалках у облачного провайдера, будет значительная просадка по производительности.
Если у кого то есть другое мнение или опыт поднятия кластера на виртуалках в проде, поделитесь спиз)
Спасибо за статью!
Всё зависит от ситуации. Смотря, что вам надо. Если вы используете услуги облачного провайдера, то файловое хранилище можно купить у него как услугу, без необходимости разворачивать самому.
Всем привет!
Как всегда отличный туториал для новичка! Спасибо, Владимир.
Но у меня возникла странная ошибка - при запуске плейбука, ансибл требует ввода SSH-пароля. При это на этом хосте и на хостах для ceph-нод настроен вход по ключу. И сам пароль неизвестно какой - угадать не получилось и в репозитории ceph-absible про это не нашёл. Настройки SSH в ansible.cfg поменял, как описано выше в статье.
Может я что-то делаю не так? Подскажите, пожалуйста.
Так в статье как раз описано, как заходить по паролю. По сути вам надо настроить аутентификацию по ключам для ansible. Можете отдельно погуглить эту тему. Она хорошо раскрыта. Установка ceph по данной статье - просто запуск плейбука ansible. Никаких особых нюансов тут нет. Я сам давно не занимался этой темой.
Проверил с помощью tcpdump - от запуск плейбука до запроса пароля SSH, ансибл сервер даже проверяет онлайн ли будущая нода. То есть, он запрашивает не SSH-пароль будущей ноды.
В общем, что-то очень странное.
Жаль скриншот нельзя прикрепить - возможно вспомнили бы эту ошибку.
Здравствуйте, подскажите сколько RBD-дисков можно создать в пуле?
Здравствуйте,не могли ответить DHT ХЕШ файла на Glusterfs где хранятся на атрибутах каждого самого файла, или в отдельном файле
Заранее благодарен
Был ли опыт подключения grafana и prometheus к ceph?
Сам не делал, но никаких проблем быть не должно. У ceph готовый экспортер для прома есть - https://docs.ceph.com/en/latest/mgr/prometheus/ Его надо только включить.
Имеется в виду, если установить (grafana и prometheus) на саму машину кластера. При падение одного из улов будет ли он так же перекидывать на другую машину, как делает ceph c редирект 303
Не понимаю вопроса. Ceph - это хранилище данных. Прометеус и Графана это сервисы, которые как минимум должны быть развернуты на веб сервере с базой данных.
дело в том что это дело развернуто на одном из узлов ceph (такая схема досталась)
Добрый день.
Статья прекрасная. хочу попробовать в своей лаборатории.
Есть несколько вопросов..
1) Масштабируемость.
если ресурсы в кластере заканчиваются, добавление новой полки,как они добавляются и могут ли быть проблемы?
2) есть ли у системы GUI для админки, или все в консоли ручками
1. Ceph зрелая и полностью готовая к продакшену система. Так что все вопросы масштабируемости там так или иначе решаются. Все зависит от каждой конкретной ситуации.
2. Я не видел, но думаю, что в каком-то виде что-то есть. Не интересовался никогда.
Здравствуйте!
Скажите, занимаетесь ли Вы установкой и настройкой Ceph для малого бизнеса?
Мы бы хотели с Вами посотрудничать.
Да, обращайтесь - https://serveradmin.ru/kontaktyi/
Вроде человек ты с головой и трезво мыслить должен но почитал твою стену в вк понял что г*о засело
Обычно такое пишут люди, у которых самих в головах г*о. Оно стекает, но они этого не замечают.
как насчет ручной настройки ?
Не понял, в чем именно вопрос?
Настойка не через ансимбл, а все создавать вручную, допустим даже так, создать кластер это одно, а добавить в нем ноды, а разделения дисков на SSD, HDD , когда делаешь это руками - приходит больше понимания как оно работает
Если вам нужно понимание, можете и вручную настроить. Рецепты ansible достаточно легко читаются. К сожалению, изучать досконально работу ceph, kubernetes и т.д. имеет смысл, если у вас на этом специализация. У меня банально нет времени глубоко погружаться в эти темы. В общем случае, такая установка через ansible вполне сойдет.
Только упавшая на ваше желание )
Вопрос ко всем, а не только к Виктору. Кто-нибудь в реальной среде тестировал растянутый Ceph? Например, если ноды физически находятся географически в разных местах в радиусе 20 км? При этом настроена оптика, средняя скорость до 10 мбит/сек.
Объем данных примерно 3 ТБ на данный момент, часть из них холодные данные, часть изменяется активно в течении рабочего дня.
Если, например в одном месте настроены две ноды, в другом месте еще одна нода, и в третьем месте также одна нода.
Допустим, происходит сбой в канале связи на 3-4 часа или выходят из строя винты на одной из этих нод. При восстановлении канала связи синхронизация происходит, как я понял из статьи, с жуткими тормозами.
При выходе из строя одного или пару винтов на замену потребуется примерно 2-3 часа.
При таких раскладах Ceph может выступать в качестве достойного решения с точки зрения растянутого кластера?
В статье есть ссылка на другую статью "Ceph. Анатомия катастрофы". Там есть вся информация, чтобы вы могли рассчитать, что произойдет во время сбоя конкретно в вашем случае. Это будет зависеть от конфигурации кластера, размера блока, скорости сети, кол-ву данных и т.д. В общем, это надо считать самим, чужой опыт тут не сильно поможет. Механизм репликации ceph известен.
"Вопрос ко всем, а не только к Виктору. " - сорри за ошибку, я имел в виду автора, Владимира.
Спасибо за труд. Сейчас хоть и нет практической необходимости в Ceph, статью прочитал с удовольствием; в целом представление о системе сложилось, да ещё и сразу живой пример с конфигами.
P.S. Нашёл пару опечаток:
"возможность файлового b блочного доступа"
"У низ поддержка ceph в ядре"
Для статей вашего масштаба на сайте пригодилась бы система сообщения об ошибках по Ctrt+Enter
Эти системы оповещений лишний яваскрипт на сайте, поэтому не ставлю. Он и так перегружен им из-за рекламы.
Где то видел информацию о том, что cephFS с некоторого времени deprecated
А что вместо нее?
Не слышал о таком. Более того, сейчас cephfs более ли менее стабильной стала и пригодной к эксплуатации.
Btrfs у RHEL тоже deprecated, но причина такого статуса если капнуть, банальна: толкают свою xfs
Но xfs же совсем другое. У нее нет функционала btrfs. Или он планируется?